visual chatgpt
1.0.0
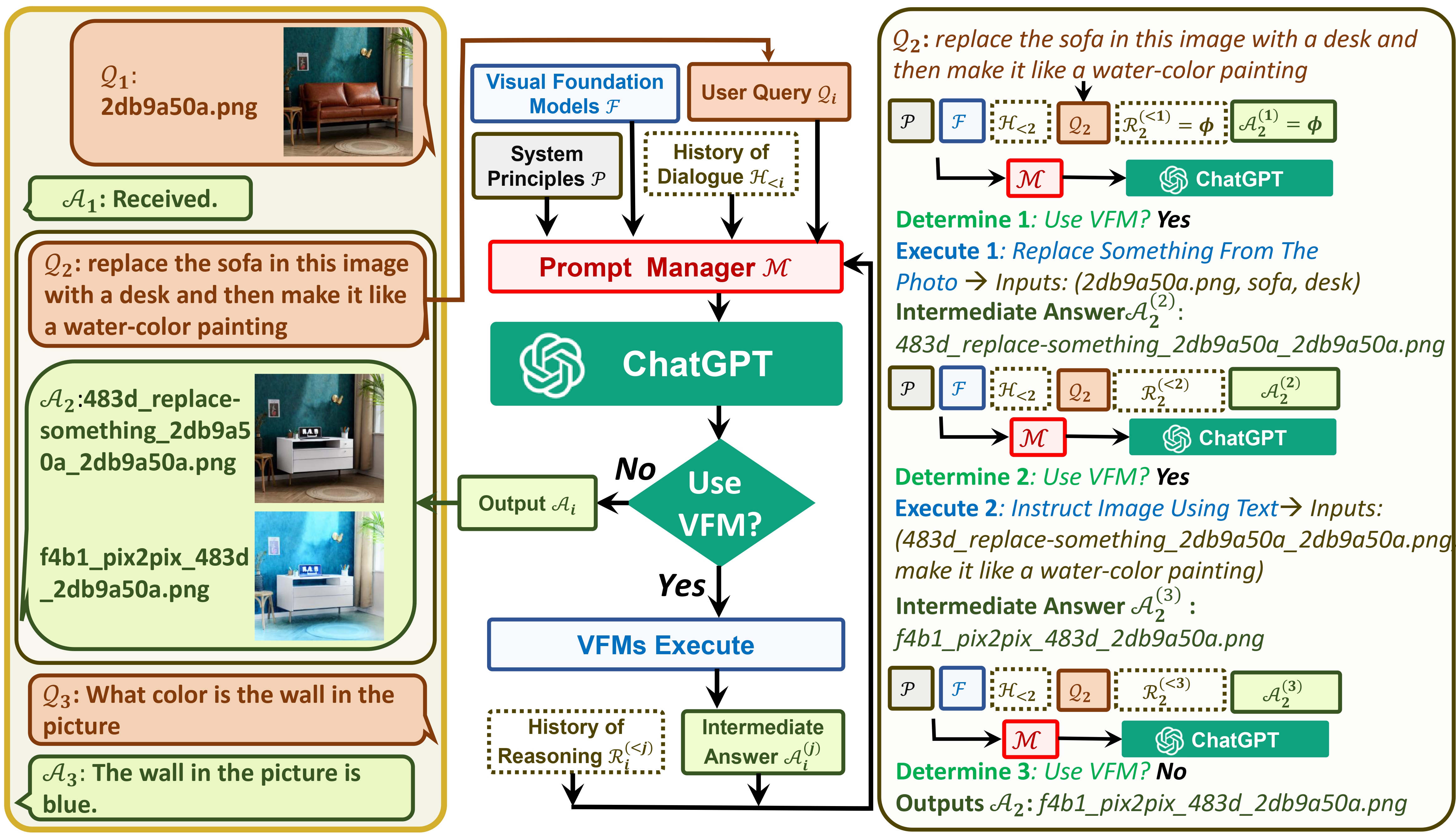
Visual ChatGPT connecte ChatGPT et une série de modèles Visual Foundation pour permettre l'envoi et la réception d'images pendant la discussion.
Consultez notre article : Visual ChatGPT : parler, dessiner et éditer avec des modèles de base visuelle
D'une part, ChatGPT (ou LLM) sert d' interface générale qui offre une compréhension large et diversifiée d'un large éventail de sujets. D'autre part, les modèles de base servent d' experts en matière de domaine en fournissant des connaissances approfondies dans des domaines spécifiques. En tirant parti de connaissances générales et approfondies , nous visons à construire une IA capable de gérer diverses tâches.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Nous répertorions ici l'utilisation de la mémoire GPU de chaque modèle de base visuelle, vous pouvez spécifier celui que vous aimez :
| Modèle de fondation | Mémoire GPU (Mo) |
|---|---|
| Édition d'images | 3981 |
| InstruirePix2Pix | 2827 |
| Texte2Image | 3385 |
| Sous-titrage d'image | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Image2Ligne | 0 |
| LigneTexte2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseTexte2Image | 3529 |
| Image2Seg | 919 |
| SegText2Image | 3529 |
| Image2Profondeur | 0 |
| ProfondeurTexte2Image | 3531 |
| Image2Normal | 0 |
| TexteNormal2Image | 3529 |
| VisuelQuestionRéponse | 1495 |
Nous apprécions l’open source des projets suivants :
Visage câlin LangChain Diffusion stable ControlNet InstructPix2Pix CLIPSeg BLIP
Pour obtenir de l'aide ou des problèmes lors de l'utilisation de Visual ChatGPT, veuillez soumettre un problème GitHub.
Pour d'autres communications, veuillez contacter Chenfei WU ([email protected]) ou Nan DUAN ([email protected]).


