TEMPO
1.0.0

Le code officiel de ["TEMPO : Transformateur pré-entraîné génératif basé sur des invites pour la prévision des séries chronologiques (ICLR 2024)"].
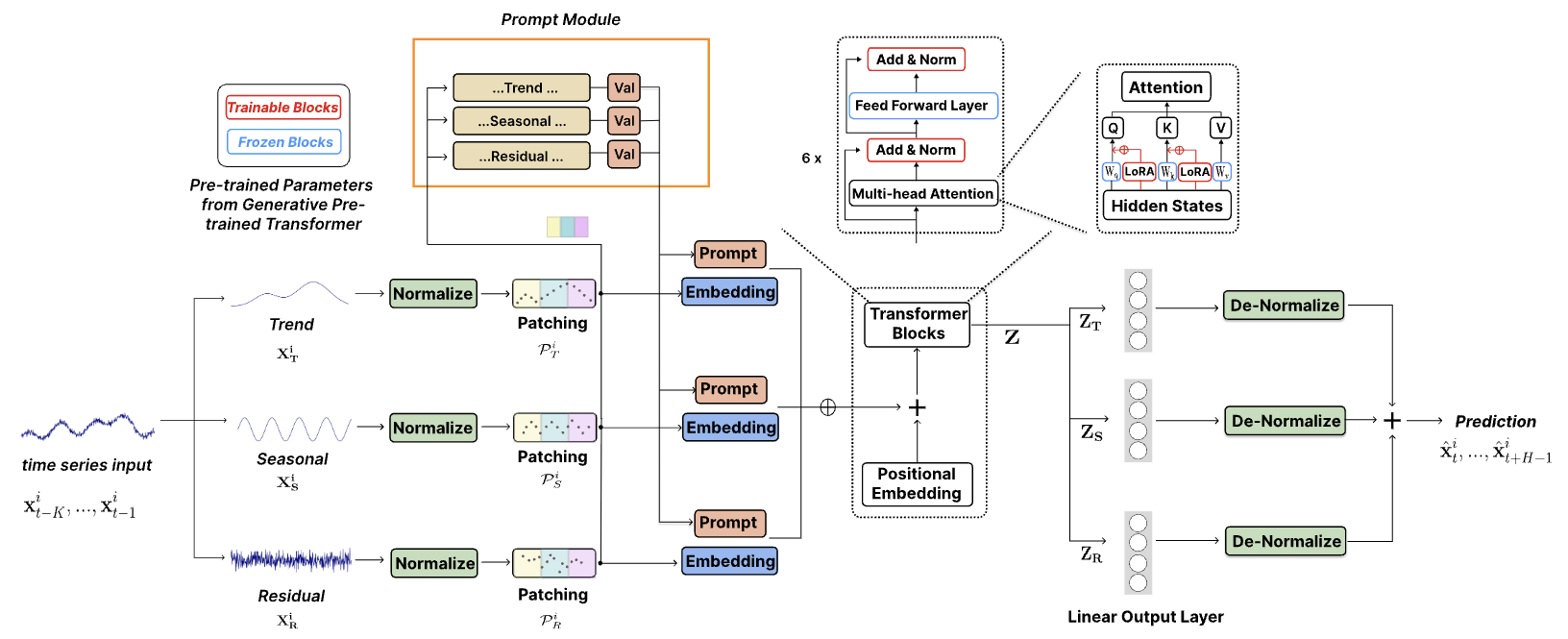
TEMPO est l'un des tout premiers modèles de base de séries chronologiques open source pour la version v1.0 des tâches de prévision.
Octobre 2024 : Nous avons rationalisé notre structure de code, permettant aux utilisateurs de télécharger le modèle pré-entraîné et d'effectuer une inférence zéro avec une seule ligne de code ! Consultez notre démo pour plus de détails. Le nombre de téléchargements de notre modèle sur HuggingFace est désormais traçable !
Juin 2024 : Nous avons ajouté des démos pour reproduire des expériences sans tir dans Colab. Nous avons également ajouté la démo de création de l'ensemble de données client et effectué directement l'inférence via notre modèle de base pré-entraîné : Colab
Mai 2024 : TEMPO a lancé une démo en ligne basée sur une interface graphique, permettant aux utilisateurs d'interagir directement avec notre modèle de fondation !
Mai 2024 : TEMPO publie le modèle de base pré-entraîné 80M dans HuggingFace !
Mai 2024 : ? Nous avons ajouté le code pour les modèles TEMPO de pré-entraînement et d'inférence. Vous pouvez trouver une démo de script de pré-formation dans ce dossier. Nous avons également ajouté un script pour la démo d'inférence.
Mars 2024 : ? Publication de l'ensemble de données TETS du S&P 500 utilisé dans des expériences multimodales dans TEMPO.
Mars 2024 : ? TEMPO a publié en ligne le code du projet et le point de contrôle pré-entraîné !
Janvier 2024 : L'article TEMPO est accepté par l'ICLR !
Oct 2023 : publication de l'article TEMPO sur Arxiv !
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
Un exemple simplifié montrant comment effectuer des prévisions à l'aide de TEMPO :
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )Veuillez essayer de reproduire les expériences zéro tir sur ETTh2 [ici sur Colab].
Nous utilisons la page Colab suivante pour montrer la démonstration de la création de l'ensemble de données client et effectuer directement l'inférence via notre modèle de base pré-entraîné : [Colab]
Veuillez essayer notre démo de modèle de base [ici].
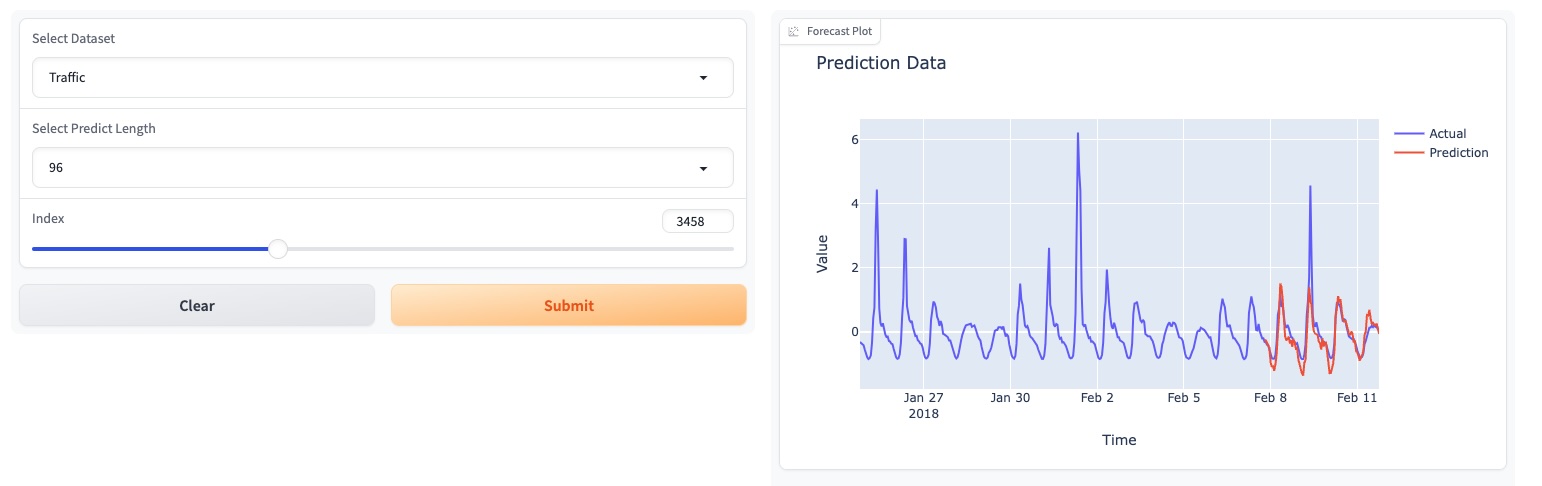
Nous avons également mis à jour nos modèles sur HuggingFace : [Melady/TEMPO].
Téléchargez les données depuis [Google Drive] ou [Baidu Drive] et placez les données téléchargées dans le dossier ./dataset . Vous pouvez également télécharger les résultats STL depuis [Google Drive] et placer les données téléchargées dans le dossier ./stl .
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
Après l'entraînement, nous pouvons tester le modèle TEMPO sous le réglage zéro-shot :
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
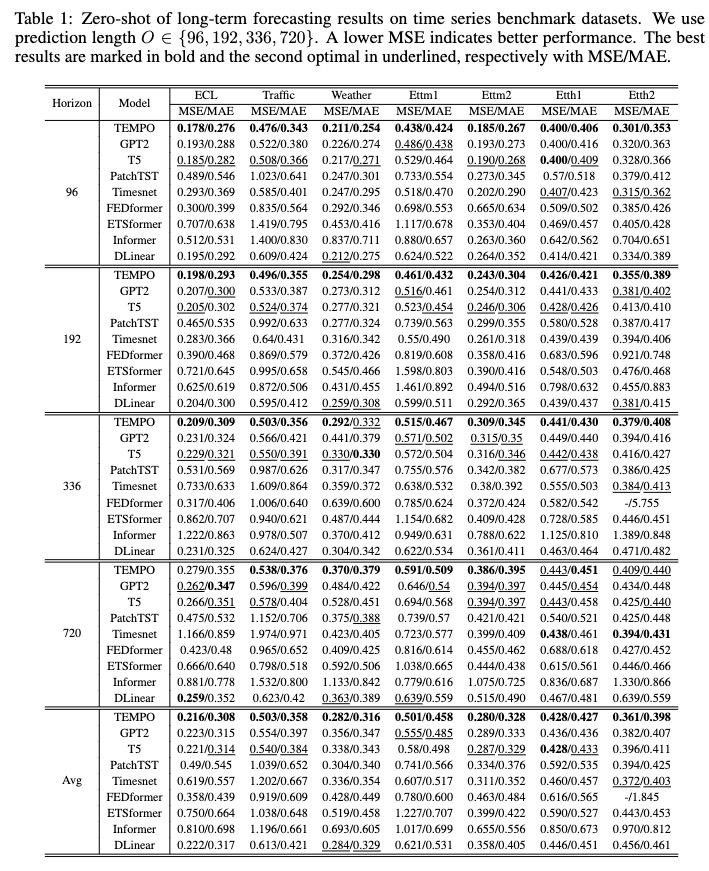
Vous pouvez télécharger le modèle pré-entraîné depuis [Google Drive], puis exécuter le script de test pour vous amuser.
Voici les invites utilisées pour générer les informations textuelles correspondantes des séries chronologiques via [API OPENAI ChatGPT-3.5]

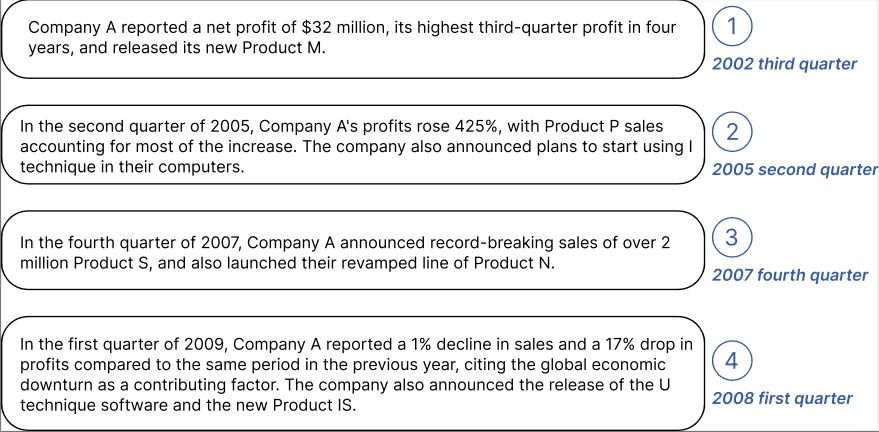
Les données des séries chronologiques proviennent du [S&P 500]. Voici le cas d'EBITDA pour une entreprise de l'ensemble de données :
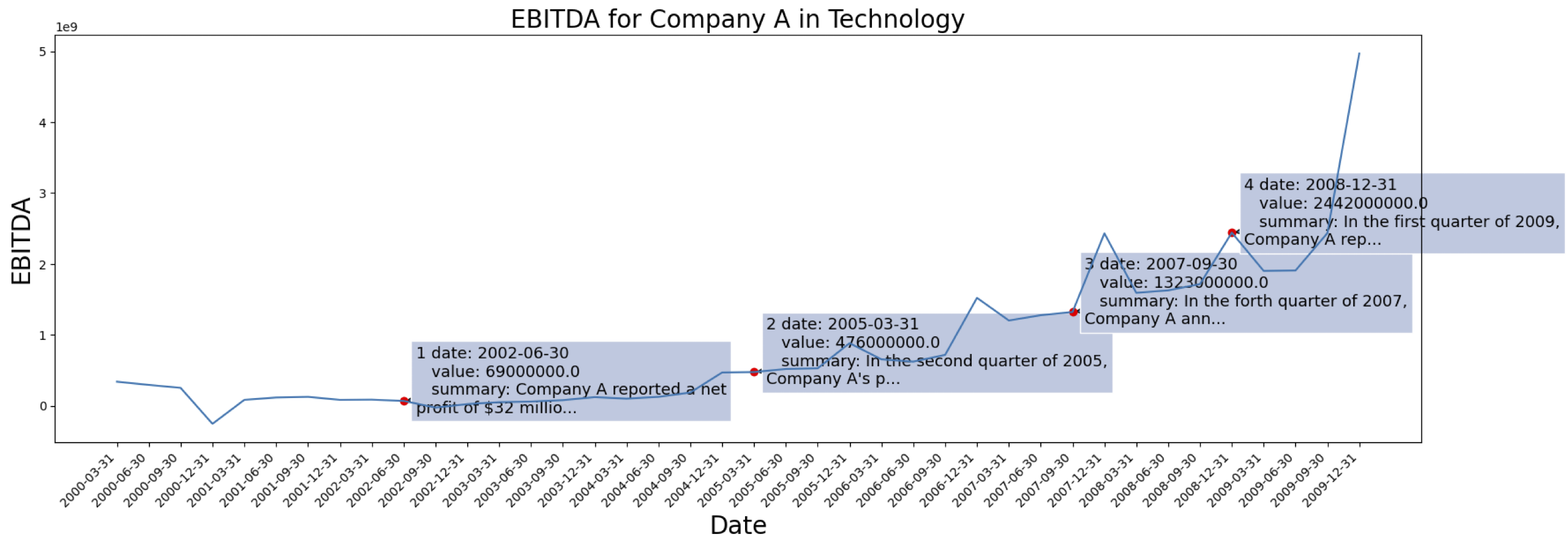
Exemple d'informations contextuelles générées pour la Société marquée ci-dessus :
Vous pouvez télécharger les données traitées avec intégration de texte depuis GPT2 à partir de : [TETS].
N'hésitez pas à vous connecter [email protected] / [email protected] si vous souhaitez appliquer TEMPO à votre application réelle.
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


