AudioNotes
1.0.0
Il peut extraire rapidement le contenu audio et vidéo et appeler un grand modèle pour l'organiser en une note de démarque structurée pour une lecture facile et rapide.
FunASR : https://github.com/modelscope/FunASR
Qwen2 : https://ollama.com/library/qwen2
Téléchargez le package d'installation Ollama correspondant au système et installez-le.
https://ollama.com/download
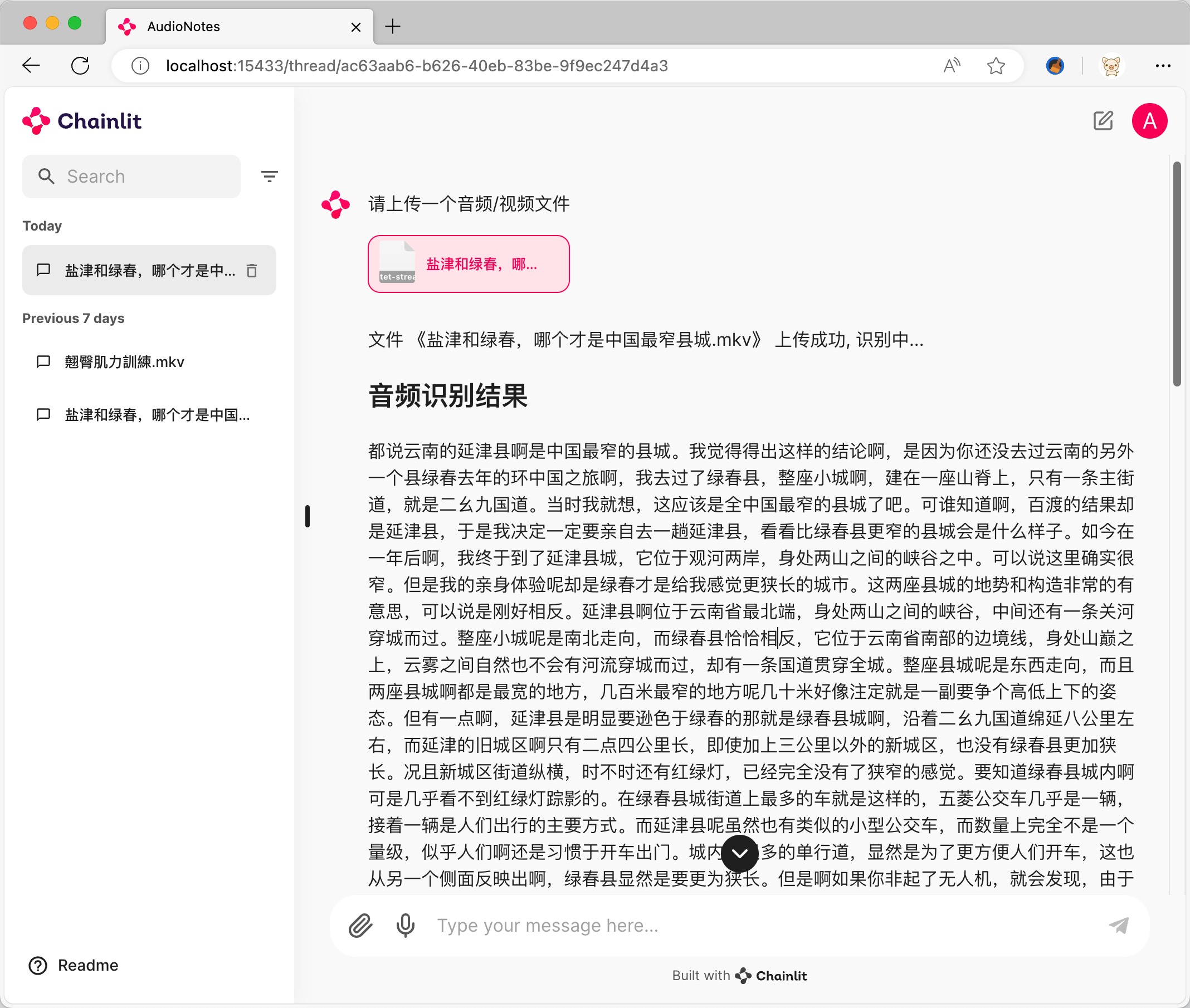
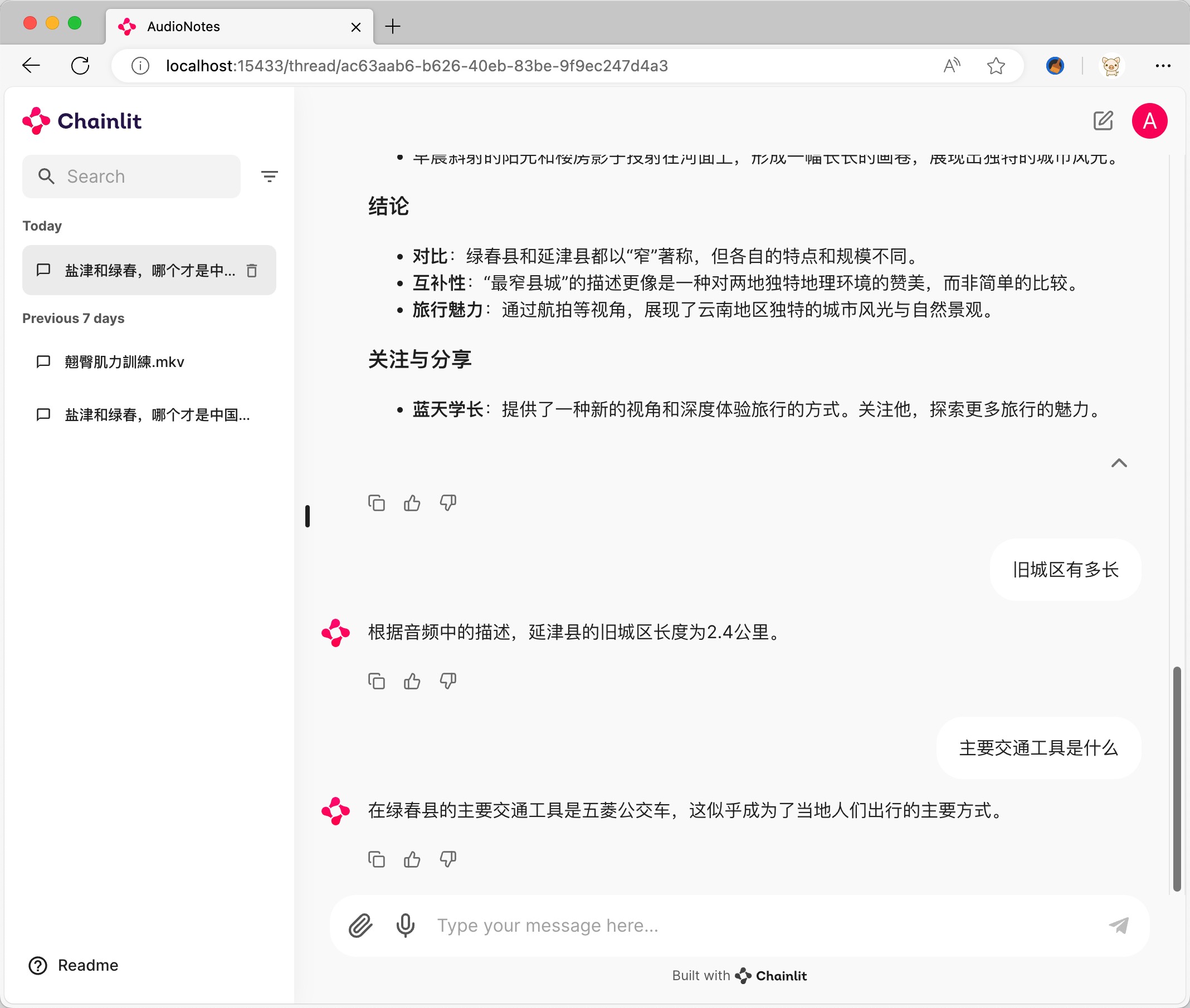
Je prends comme exemple阿里的千问2 7b https://ollama.com/library/qwen2
ollama pull qwen2:7bIl existe deux méthodes de déploiement, l'une consiste à déployer à l'aide de Docker et l'autre à déployer localement.
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml
docker-compose upAprès le démarrage de Docker, visitez http://localhost:15433/
Le compte de connexion est admin et le mot de passe est admin (peut être modifié dans le fichier docker-compose.yml)
Une base de données postgresql accessible est requise
conda create -n AudioNotes python=3.10 -y
conda activate AudioNotes
git clone https://github.com/harry0703/AudioNotes.git
cd AudioNotes
pip install -r requirements.txt Renommez .env.example en .env et modifiez les informations de configuration pertinentes
chainlit run main.pyUne fois le service démarré, visitez http://localhost:8000/
Le compte de connexion est admin et le mot de passe est admin (peut être modifié dans le fichier .env)


