AMRICA
1.0.0
AMRICA (AMR Inspector for Cross-lingual Alignments) est un outil simple pour aligner et représenter visuellement les AMR (Banarescu, 2013), à la fois pour des contextes bilingues et pour un accord inter-annotateur monolingue. Il est basé sur et étend le système Smatch (Cai, 2012) pour identifier l'accord interannotateur AMR.
Il est également possible d'utiliser AMRICA pour visualiser les alignements manuels que vous avez édités ou compilés vous-même (voir Common Flags).
Téléchargez la source Python depuis github.
Nous supposons que vous avez pip . Pour installer les dépendances (en supposant que vous ayez déjà les dépendances graphviz mentionnées ci-dessous), exécutez simplement :
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz nécessite graphviz pour fonctionner. Sous Linux, vous devrez peut-être installer graphviz libgraphviz-dev pkg-config . De plus, pour préparer des données d'alignement bilingues, vous aurez besoin de GIZA++ et éventuellement de JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
Cette commande lira les AMR dans sample.amr (séparés par des lignes vides) et placera leurs visualisations graphviz dans des fichiers .png situés dans sample_out_dir/ .
Pour générer des visualisations des alignements Smatch, nous avons besoin d'un fichier d'entrée AMR avec chaque champ ::tok ou ::snt contenant des phrases tokenisées, des champs ::id avec un ID de phrase et des champs ::annotator ou ::anno avec un ID d'annotateur. Les annotations d'une phrase particulière sont répertoriées dans l'ordre et la première annotation est considérée comme la référence à des fins de visualisation.
Si vous souhaitez visualiser uniquement l'annotation unique par phrase sans accord inter-annotateur, vous pouvez utiliser un fichier AMR avec un seul annotateur. Dans ce cas, les champs annotateur et ID de phrase sont facultatifs. Le graphique résultant sera tout noir.
Pour les alignements bilingues, nous commençons avec deux fichiers AMR, un contenant les annotations cibles et un avec les annotations sources dans le même ordre, avec les champs ::tok et ::id pour chaque annotation. Si nous voulons des alignements JAMR pour chaque côté, nous les incluons dans un champ ::alignments .
Les alignements de phrases doivent se présenter sous la forme de deux fichiers d'alignement GIZA++ .NBEST, un source-cible et un cible-source. Pour les générer, utilisez l'indicateur --nbestalignments dans votre fichier de configuration GIZA++ défini sur votre nombre nbest préféré.
Les indicateurs peuvent être définis soit sur la ligne de commande, soit dans un fichier de configuration. L'emplacement d'un fichier de configuration peut être défini avec -c CONF_FILE sur la ligne de commande.
En plus de --conf_file , il existe plusieurs autres indicateurs qui s'appliquent à la fois au texte unilingue et bilingue. --outdir DIR est le seul requis et spécifie le répertoire dans lequel nous allons écrire les fichiers image.
Les indicateurs partagés facultatifs sont :
--verbose pour imprimer les phrases au fur et à mesure que nous les alignons.--no-verbose pour remplacer un paramètre par défaut détaillé.--json FILE.json pour écrire les graphiques d'alignement dans un fichier .json.--num_restarts N pour spécifier le nombre de redémarrages aléatoires que Smatch doit exécuter.--align_out FILE.csv pour écrire les alignements dans le fichier.--align_in FILE.csv pour lire les alignements à partir du disque au lieu d'exécuter Smatch.--layout pour modifier le paramètre de mise en page en graphviz.Les fichiers d'alignement .csv sont dans un format dans lequel chaque ensemble de correspondances de graphiques est séparé par une ligne vide, et chaque ligne d'un ensemble contient soit un commentaire, soit une ligne indiquant un alignement. Par exemple:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
Les champs séparés par des tabulations sont l'index du nœud de test (tel que traité par Smatch), l'étiquette du nœud de test, l'index du nœud gold et l'étiquette du nœud gold.
L'alignement monolingue nécessite un indicateur supplémentaire, --infile FILE.amr , avec FILE.amr défini sur l'emplacement du fichier AMR.
Voici un exemple de fichier de configuration :
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
En alignement bilingue, il y a plus de drapeaux obligatoires.
--src_amr FILE pour le fichier AMR d'annotation source.--tgt_amr FILE pour le fichier AMR d'annotation cible.--align_tgt2src FILE.A3.NBEST pour le fichier GIZA++ .NBEST alignant la cible sur la source (avec la cible comme vcb1), généré avec --nbestalignments N--align_src2tgt FILE.A3.NBEST pour le fichier GIZA++ .NBEST alignant la source sur la cible (avec la source comme vcb1), généré avec --nbestalignments N Maintenant, si --nbestalignments N était défini sur >1, nous devrions le spécifier avec --num_aligned_in_file . Si on veut ne compter que le haut --num_align_read .
--nbestalignments est un indicateur délicat à utiliser, car il ne sera généré que lors d'une exécution d'alignement final. Je n'ai pu le faire fonctionner moi-même qu'avec les paramètres par défaut de GIZA++.
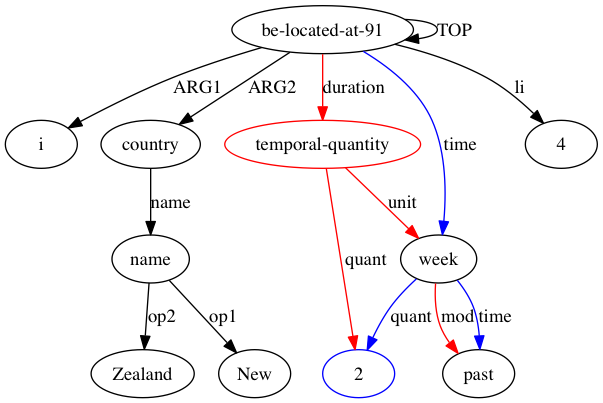
Puisque AMRICA est une variante de Smatch, il faut commencer par comprendre Smatch. Smatch tente d'identifier une correspondance entre les nœuds variables de deux représentations AMR de la même phrase afin de mesurer l'accord inter-annotateur. La correspondance doit être sélectionnée pour maximiser le score Smatch, qui attribue un point pour chaque arête apparaissant dans les deux graphiques, répartis en trois catégories. Chaque catégorie est illustrée par l'annotation suivante : « Cela n'a pas pris longtemps ».
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)Étant donné que le problème de trouver la correspondance maximisant le score Smatch est NP-complet, Smatch utilise un algorithme d'escalade pour se rapprocher de la meilleure solution. Il effectue l'amorçage en faisant correspondre chaque nœud à un nœud partageant son étiquette si possible et en faisant correspondre les nœuds restants dans le plus petit graphique (ci-après la cible) de manière aléatoire. Smatch effectue ensuite une étape en trouvant l'action qui augmentera le plus le score en changeant les correspondances de deux nœuds cibles ou en déplaçant une correspondance de son nœud source vers un nœud source sans correspondance. Il répète cette étape jusqu'à ce qu'aucune étape ne puisse augmenter immédiatement le score Smatch.
Pour éviter les optima locaux, Smatch redémarre généralement 5 fois.
Pour des détails techniques sur le fonctionnement interne d'AMRICA, il peut être plus utile de lire notre document de démonstration NAACL.
AMRICA commence par remplacer tous les nœuds constants par des nœuds variables qui sont des instances de l'étiquette de la constante. Ceci est nécessaire pour pouvoir aligner les nœuds constants ainsi que les variables. Ainsi, les seuls points ajoutés au score AMRICA proviendront de la correspondance des bords variable-variable et des étiquettes d'instance.
Alors que Smatch essaie de faire correspondre chaque nœud du plus petit graphique à un nœud du plus grand graphique, AMRICA supprime les correspondances qui n'augmentent pas le score Smatch modifié, ou score AMRICA.
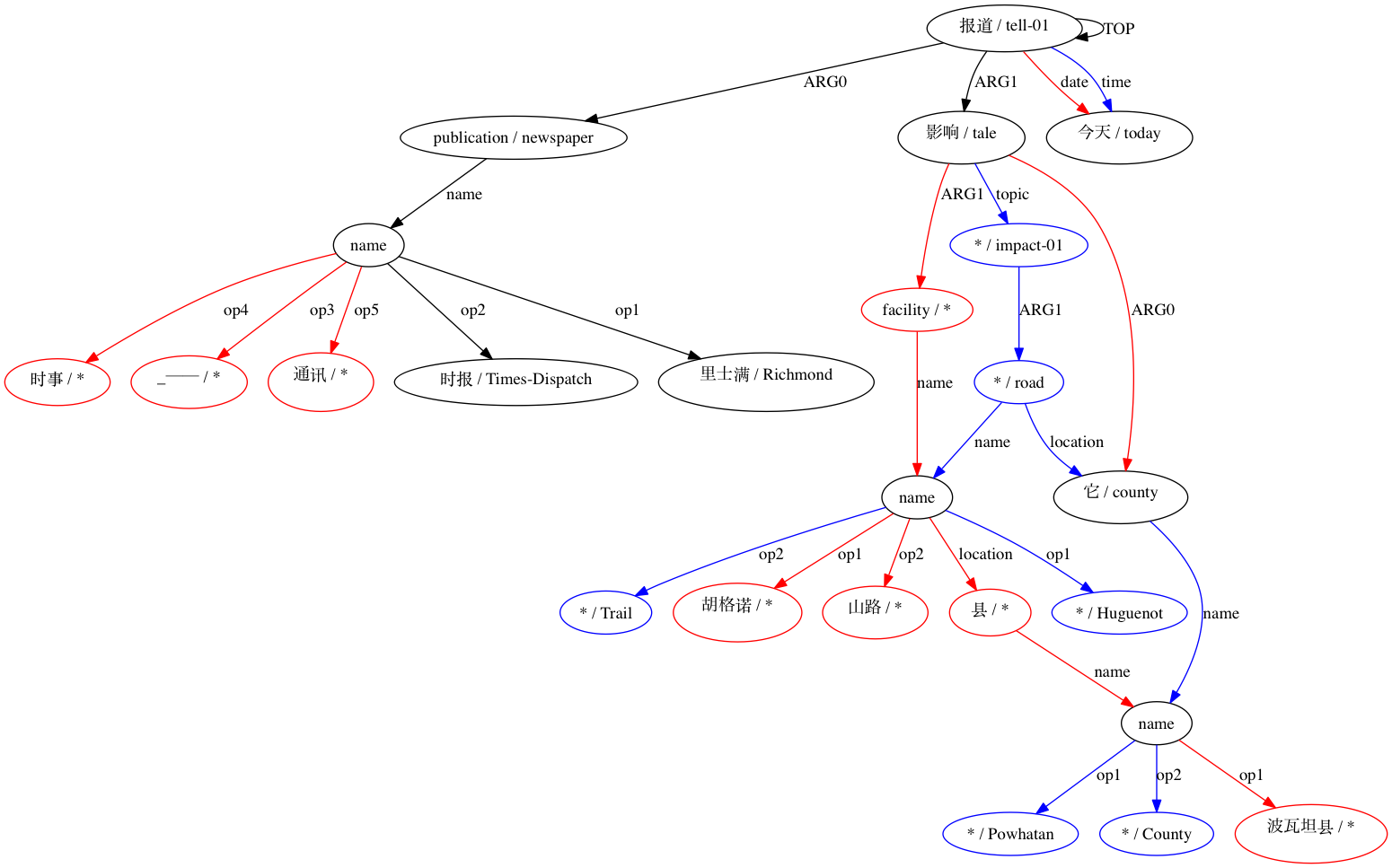
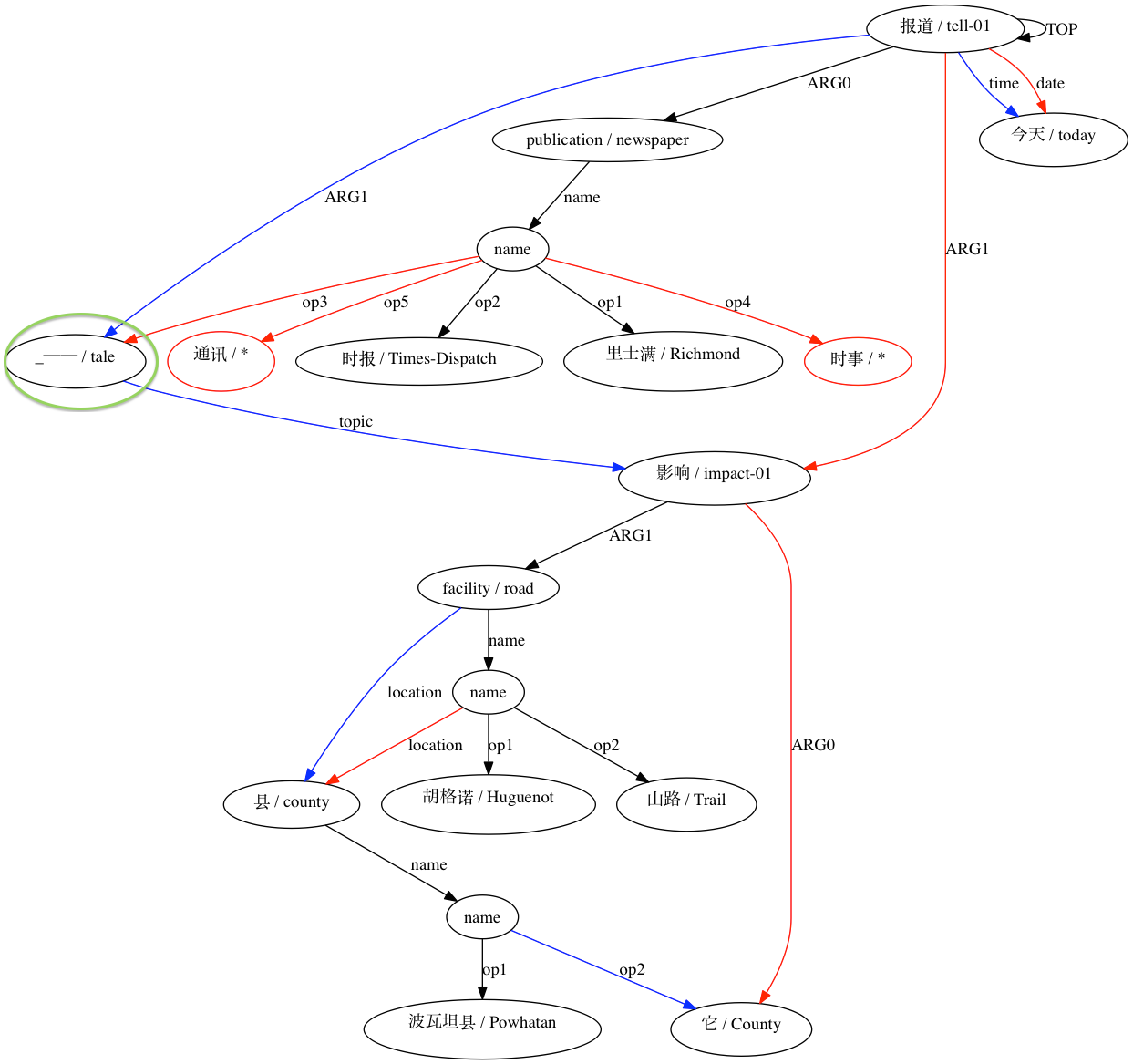
AMRICA génère ensuite des fichiers images à partir de graphiques graphviz des alignements. Si un nœud ou une arête apparaît uniquement dans les données Gold, il est rouge. Si ce nœud ou ce bord apparaît uniquement dans les données de test, il est bleu. Si le nœud ou l'arête a une correspondance dans notre alignement final, il est noir.
En AMRICA, au lieu d'ajouter un point pour chaque étiquette d'instance parfaitement correspondante, nous ajoutons un point basé sur un score de probabilité d'alignement de ces étiquettes. Le score de vraisemblance ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) avec l'ensemble d'étiquettes cible Lt, l'ensemble d'étiquettes source Ls, la phrase cible Wt, la phrase source Ws et l'alignement aLt,Ls[i] mappant Lt[ i] sur une étiquette Ls[aLt,Ls[i]], est calculé à partir d'une vraisemblance définie par les règles suivantes :
En général, l'AMRICA bilingue semble nécessiter plus de redémarrages aléatoires que l'AMRICA monolingue pour fonctionner correctement. Ce nombre de redémarrages peut être modifié avec l'indicateur --num_restarts .
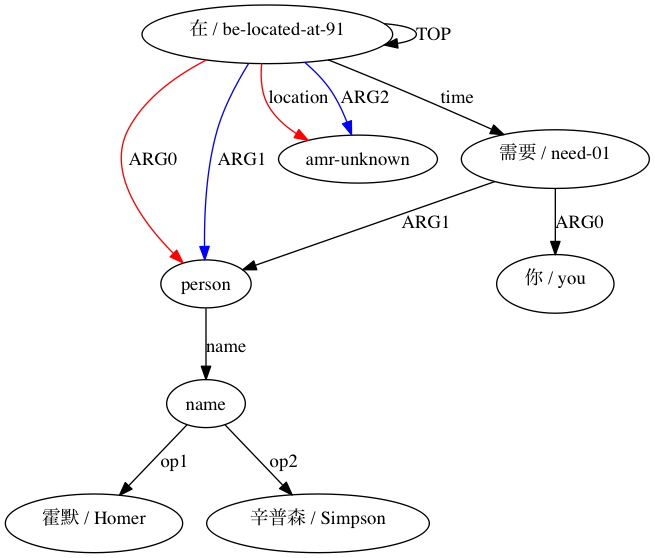
Nous pouvons observer dans quelle mesure l'utilisation d'approximations de type Smatch (ici, avec 20 initialisations aléatoires) améliore la précision par rapport à la sélection de correspondances probables à partir de données d'alignement brutes (initialisation intelligente). Pour un appariement déclaré structurellement compatible par (Xue 2014).
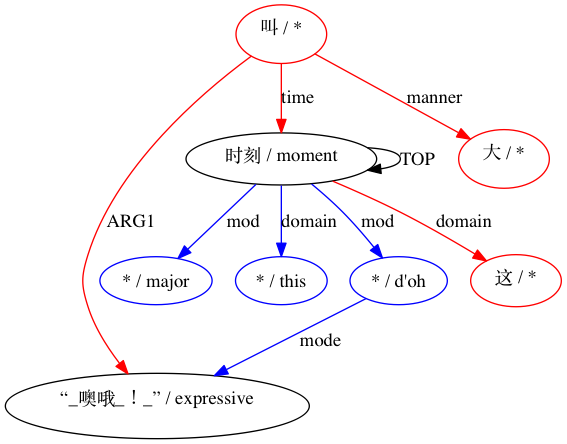
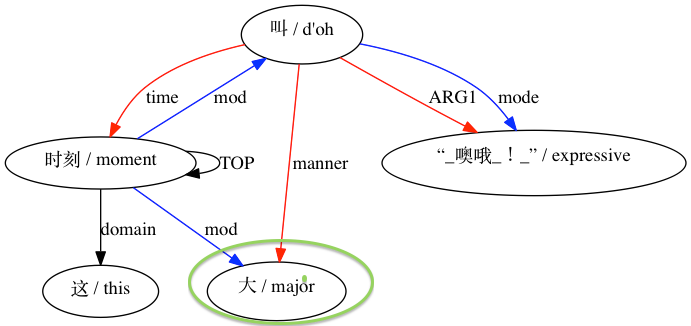
Pour un appariement considéré comme incompatible :
Ce logiciel a été développé en partie avec le soutien de la National Science Foundation (États-Unis) sous les récompenses 1349902 et 0530118. L'Université d'Édimbourg est un organisme caritatif enregistré en Écosse sous le numéro d'enregistrement SC005336.


