llmjudge
1.0.0
Il est difficile d'évaluer les LLM dans un scénario ouvert, il existe un consensus croissant selon lequel les références existantes font défaut et les praticiens chevronnés préfèrent vibrer eux-mêmes les modèles de vérification . J'ai eu recours à des évaluations anecdotiques de développeurs et de chercheurs en qui j'ai confiance, Chatbot Arena étant un excellent complément. La motivation derrière ce dépôt est la méthode de plus en plus populaire consistant à utiliser des LLM solides comme juge des modèles. Cette méthode existe depuis quelques mois, avec des modèles comme JudgeLM, et plus récemment MT-Bench.
Vous avez peut-être ou non vu ce fil. Selon les auteurs du tweet d'Arize AI, l'utilisation des LLM en tant que juge justifie la prudence du serveur, en particulier en ce qui concerne l'utilisation d'évaluations numériques des scores. Il semble que les LLM sont très mauvais pour gérer des plages continues, ce qui devient flagrant lorsqu'ils les incitent à évaluer X de 1 à 10. Ce référentiel est un document vivant d'expériences tentant de comprendre et de capturer la frontière irrégulière de ce problème. Des travaux récents ont établi une forte corrélation entre MT-Bench et Human Judgment (Arena Elo) , ce qui signifie que les LLM sont capables d'être des juges, alors que se passe-t-il ici ?
Vous trouverez ci-dessous tous les détails et les résultats.
En raison de contraintes de coûts, je me concentrerai dans un premier temps sur la tâche d'orthographe/faute d'orthographe décrite dans les tweets. Je crains un peu que le X quantitatif de cette tâche contamine les connaissances de cette expérience, mais nous verrons. Je me félicite d'une analyse plus complète de ce phénomène, mes résultats doivent être pris avec des pincettes compte tenu du caractère limité de l'expérience.
J'ai généré un ensemble de données d'orthographe ou de fautes d'orthographe, sans savoir quel nom est le plus approprié, à partir des essais de Paul Graham. Ce choix était principalement par commodité, car j'ai déjà utilisé l'ensemble de données lors de tests de pression sur les fenêtres contextuelles. J'ai extrait un contexte de 3 000 mots des essais et inséré des fautes d'orthographe sur des mots aléatoires en fonction du taux de fautes d'orthographe souhaité. En pseudocode :
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
Le code complet est facilement disponible sous forme de cahier.
Compte tenu de l'ensemble de données généré, nous invitons les LLM à évaluer la quantité de mots mal orthographiés dans un contexte à l'aide de différents modèles de notation. Nous utilisons les API suivantes
GPT-4 : gpt-4-0125-preview
GPT-3.5 : gpt-3.5-turbo-1106
à température = 0.
Test 1. Confirmons que les LLM ont du mal à gérer les plages numériques dans un environnement de tir nul. Nous proposons à GPT-3.5 et GPT-4 un modèle de notation numérique, allant du score 0 au score 10.
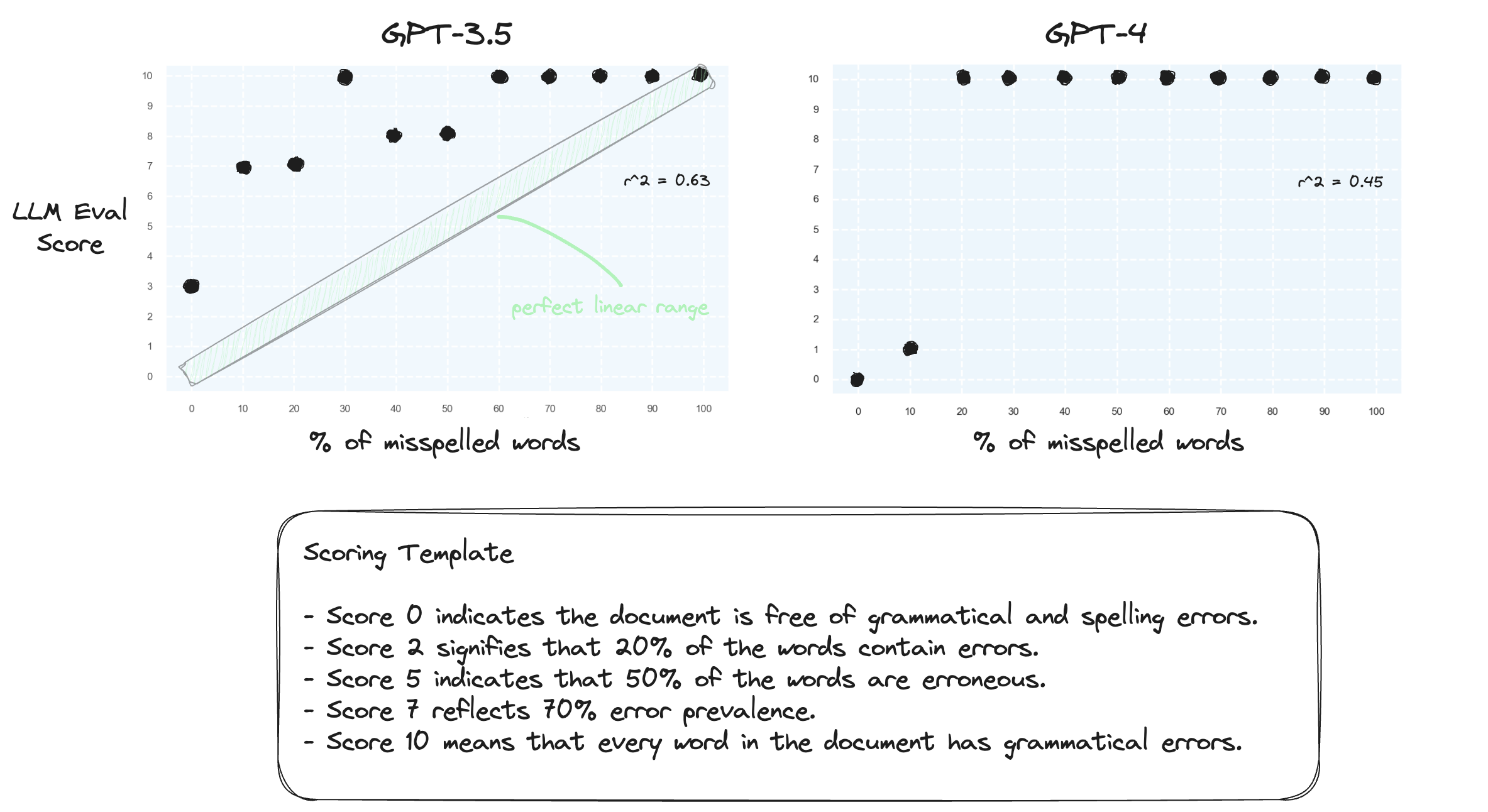
Comme prévu, les deux jugent gravement mal.
Test 2. Que se passe-t-il si on inverse la plage de notation ? Désormais, une note de 10 représente un document parfaitement orthographié.
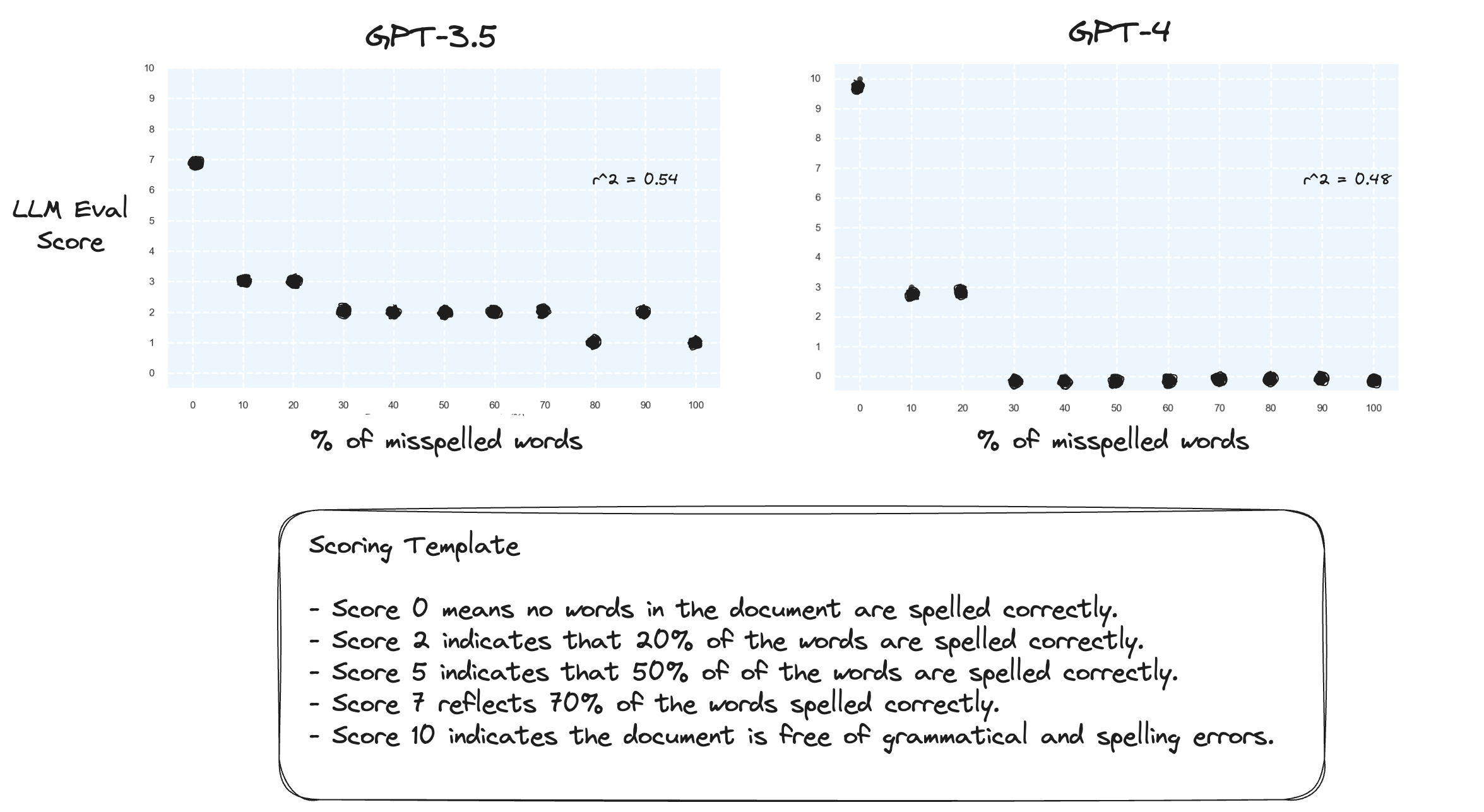
Cela ne semble pas faire une grande différence.
Test 3. Si nous en croyons l'hypothèse d'Arize, nous pourrions constater des améliorations si nous évitons une grille de notation et utilisons à la place des « notes étiquetées ». Dans ce cas, j'ai décidé de passer à une échelle de notation de 5 points.
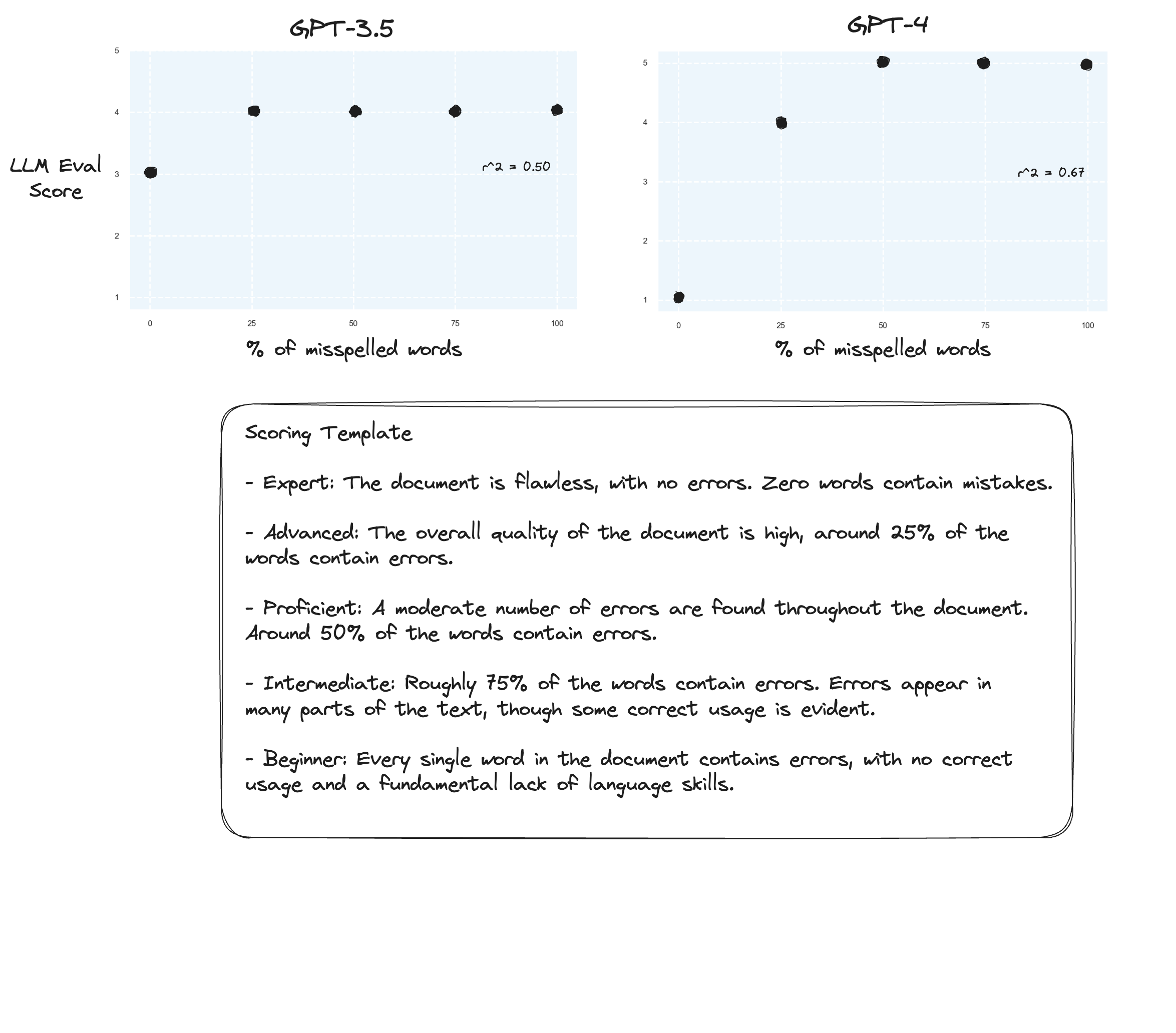
Peut-être de légères améliorations ? Difficile de le dire honnêtement. Je ne suis pas impressionné.
Test 4. Qu'en est-il de la chaîne de pensée sans tir ?

gpt-3.5 s'est transformé en charabia pour deux des invites. Comme prévu, gpt-4 constate une amélioration lorsqu'il est invité à réfléchir à voix haute. Remarquez à quel point il est très hésitant d'attribuer une note de 10.
Test 5. Comme le suggère l'auteur de Prométhée ; mapper chaque score avec sa propre explication améliore probablement la capacité du LLM à noter sur toute la plage numérique. Ceci, combiné au CoT, donne les résultats suivants :

Améliorations continues pour gpt-4. Il est encore très réticent à attribuer des scores limites de 0 à 10.
Test 6. Après en avoir lu davantage sur MT Bench, j'ai décidé de tester une approche alternative, en utilisant des comparaisons par paires plutôt qu'une notation isolée. Maintenant, normalement, cela nécessiterait des comparaisons O(n * log N), mais comme nous connaissons déjà l'ordre, j'ai pensé que nous testerions simplement les cas les plus difficiles : comparer 0 % de faute d'orthographe contre 10 % de faute d'orthographe, 10 % contre 20 % et ainsi de suite. pour un total de 10 comparaisons. Notez que j'ai également utilisé CoT zéro tir.
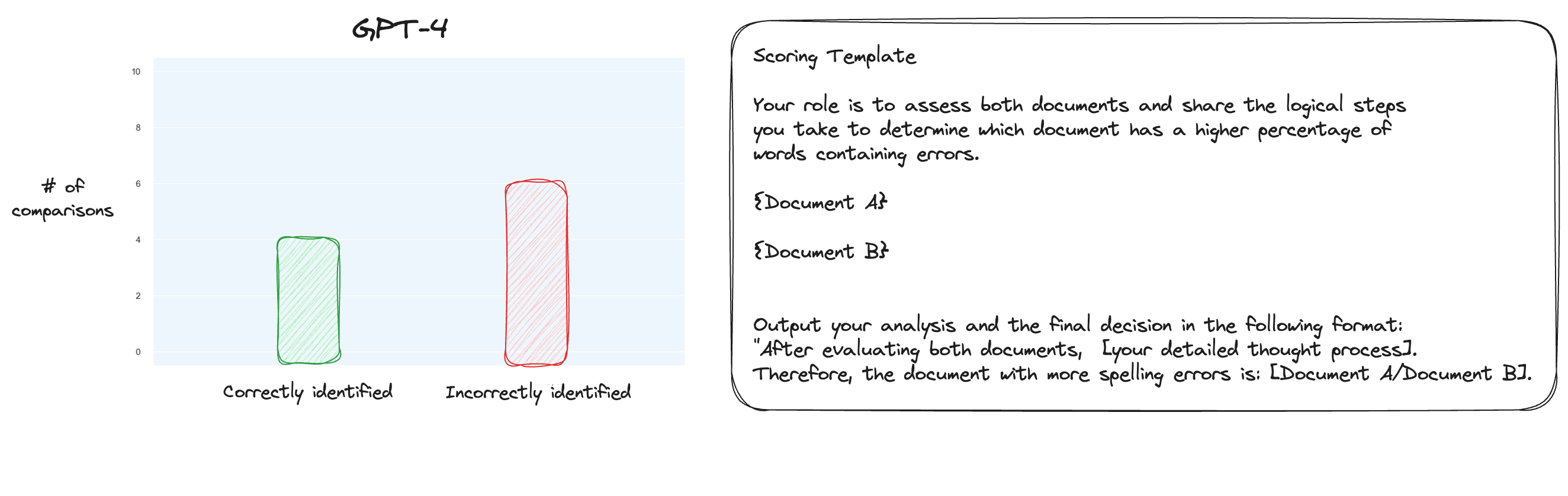
Mon hypothèse était que GPT-4 aurait excellé dans un scénario où il aurait pu comparer deux textes dans sa fenêtre contextuelle, mais j'avais tort. À ma grande surprise, cela n’a vraiment pas amélioré les choses. Bien sûr, c’est la comparaison la plus difficile parmi toutes les comparaisons possibles, mais dans l’ensemble, cela reste une tâche simple. Peut-être que les aspects quantitatifs de cette tâche sont par nature très difficiles pour les LLM. Hmm, je dois peut-être trouver une meilleure tâche proxy...
(31/1) J'ai parcouru les composants internes de MT-Bench et j'ai été très surpris de constater qu'ils demandent simplement à GPT-4 de noter les résultats sur une échelle de 1 à 10. Ils proposent des options de notation alternatives telles que des comparaisons par paires par rapport à une ligne de base, mais l'option recommandée est l'option numérique. L’invite de jugement est également étonnamment simple :
Veuillez agir en tant que juge impartial et évaluer la qualité de la réponse fournie par un assistant IA à la question de l'utilisateur affichée ci-dessous. Votre évaluation doit prendre en compte des facteurs tels que l'utilité, la pertinence, l'exactitude, la profondeur, la créativité et le niveau de détail de la réponse. Commencez votre évaluation en fournissant une brève explication. Soyez le plus objectif possible. Après avoir fourni votre explication, vous devez noter la réponse sur une échelle de 1 à 10 en suivant strictement ce format : [note], par exemple : « Note : 5 ». [Question] {question} [Début de la réponse de l'assistant] {réponse} [Fin de la réponse de l'assistant]
Si l'on croit que c'est tout ce qu'il y a à juger dans MT-Bench, alors je commence à remettre en question l'utilisation de la tâche de faute d'orthographe comme tâche proxy...
(2/2) Je souhaite que GPT-4 juge les textes mal orthographiés via une comparaison par paire plutôt qu'une notation isolée. C'est l'une des méthodes de jugement alternatives pour MT Bench (bien qu'ils recommandent une notation isolée), et je soupçonne qu'elle est plus adaptée à cette tâche. Les résultats de la cartographie complète CoT + sont définitivement une amélioration mais je pense qu'il y a encore du travail à faire. L'inconvénient de la notation par paire est bien sûr que vous aurez besoin de beaucoup plus d'appels API pour établir le classement complet (en pratique).


