DreamerGPT
1.0.0
 DreamerGPT : réglage fin des instructions du modèle en langue chinoise
DreamerGPT : réglage fin des instructions du modèle en langue chinoise? DreamerGPT est un grand projet de mise au point d'enseignement de modèles de langage chinois initié par Xu Hao, Chi Huixuan, Bei Yuanchen et Liu Danyang.
Lire en version anglaise .

 1. Présentation du projet
1. Présentation du projetL'objectif de ce projet est de promouvoir l'application de grands modèles linguistiques chinois dans des scénarios de domaine plus verticaux.
Notre objectif est de réduire la taille des grands modèles et d'aider chacun à se former et à disposer d'un assistant expert personnalisé dans son propre domaine vertical. Il peut s'agir d'un conseiller psychologique, d'un assistant de code, d'un assistant personnel ou de votre propre tuteur de langue, ce qui signifie que. DreamerGPT est un modèle linguistique qui offre les meilleurs résultats possibles, le coût de formation le plus bas et qui est davantage optimisé pour le chinois. Le projet DreamerGPT continuera à ouvrir la formation à chaud de modèles de langage itératifs (y compris LLaMa, BLOOM), la formation aux commandes, l'apprentissage par renforcement, le réglage fin du champ vertical, et continuera à itérer des données de formation et des objectifs d'évaluation fiables. En raison du personnel et des ressources limités du projet, la version V0.1 actuelle est optimisée pour le chinois LLaMa pour LLaMa-7B et LLaMa-13B, ajoutant des fonctionnalités chinoises, un alignement linguistique et d'autres capacités. Actuellement, il existe encore des lacunes dans les capacités de dialogue long et le raisonnement logique. Veuillez consulter la prochaine version de la mise à jour pour plus de plans d'itération.
Ce qui suit est une démo de quantification basée sur 8b (la vidéo n'est pas accélérée). Actuellement, l'accélération de l'inférence et l'optimisation des performances sont également en cours d'itération :
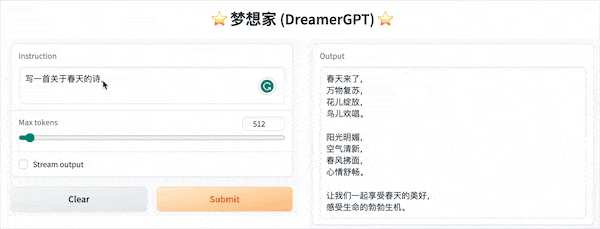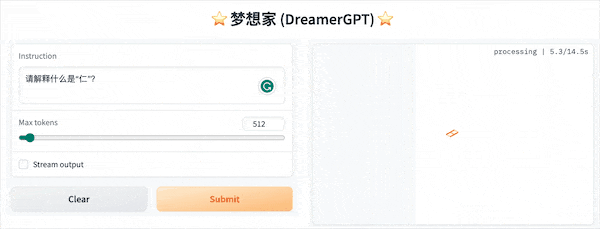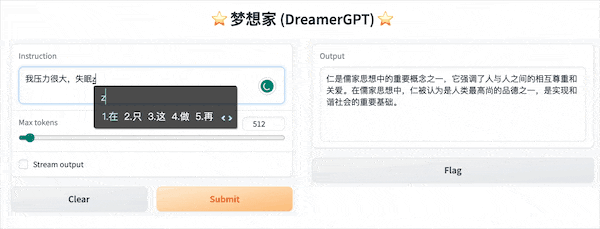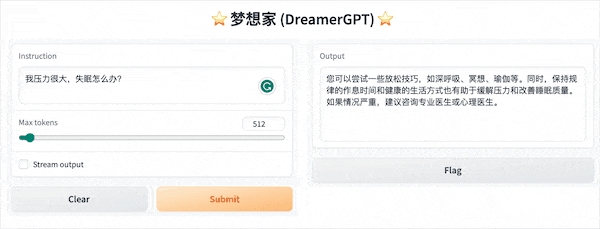
Plus d'affichages de démonstration :
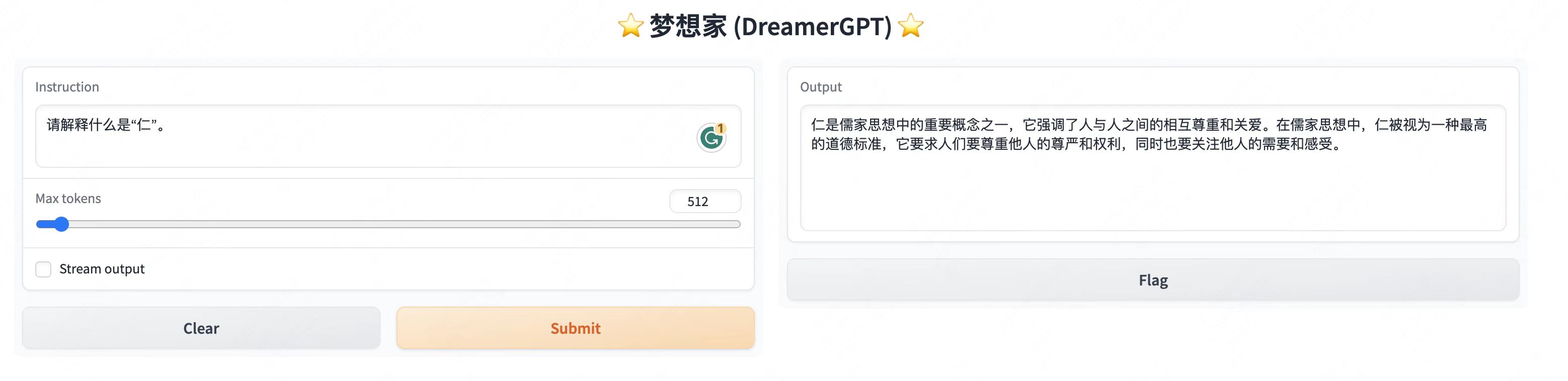

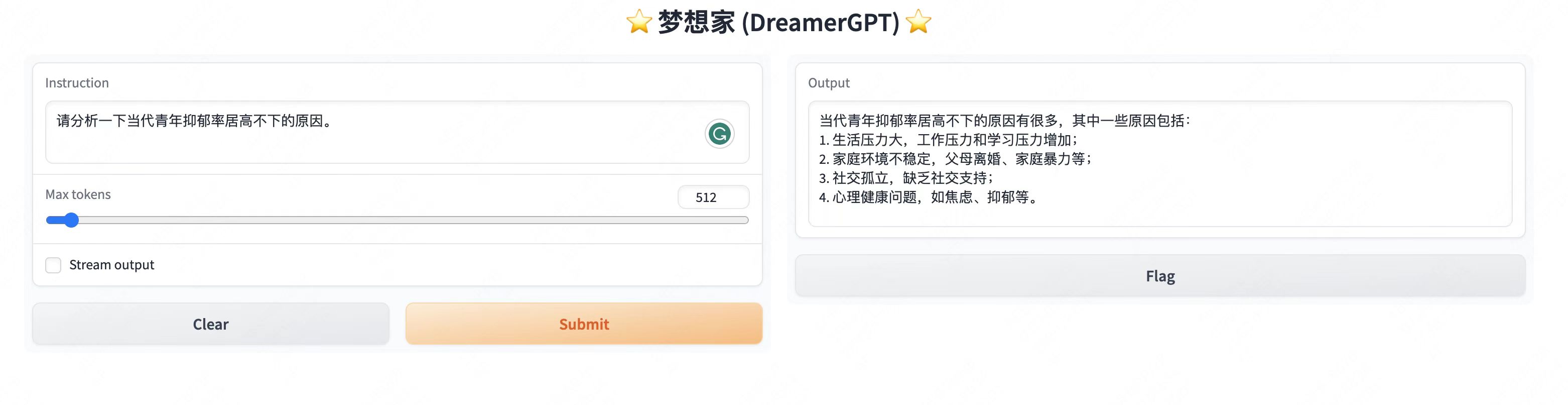
 2. Dernière mise à jour
2. Dernière mise à jour  [2023/06/17] Mise à jour version V0.2 : version d'entraînement incrémental LLaMa firefly, version BLOOM-LoRA (
[2023/06/17] Mise à jour version V0.2 : version d'entraînement incrémental LLaMa firefly, version BLOOM-LoRA ( finetune_bloom.py , generate_bloom.py ).
[2023/04/23] Commande chinoise officiellement open source affinant le grand modèle Dreamer (DreamerGPT) , offrant actuellement une expérience de téléchargement de la version V0.1
Modèles existants (formation incrémentielle continue, davantage de modèles à mettre à jour) :
| Nom du modèle | données d'entraînement = | Téléchargement du poids |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + luciole-train-1 | [Visage câlin] |
| D7b-5-1 | D7b-4-1 + luciole-train-1 | [Visage câlin] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chinois-alpaga-lora-13b-hot start + COIG-part1, COIG-traduction + PsyQA-5 | [Google Drive] [HuggingFace] |
| D13b-2-2-2 | Chinois-alpaga-lora-13b-hot start + luciole-train-0 + COIG-part1, COIG-traduction | [Google Drive] [HuggingFace] |
| D13b-2-3 | Alpaga chinois-lora-13b-démarrage à chaud + luciole-train-0 + COIG-part1, COIG-traduction + PsyQA-5 | [Google Drive] [HuggingFace] |
| D7b-4-1 | Alpaga-lora-chinois-7b-hotstart+firefly-train-0 | [Google Drive] [HuggingFace] |
Aperçu de l'évaluation du modèle
 3. Préparation du modèle et des données
3. Préparation du modèle et des donnéesTéléchargement du poids du modèle :
Les données sont traitées uniformément au format json suivant :
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Script de téléchargement et de prétraitement des données :
| données | taper |
|---|---|
| Alpaga-GPT4 | Anglais |
| Firefly (prétraité en plusieurs copies, alignement du format) | Chinois |
| COIG | Chinois, code, chinois et anglais |
| PsyQA (prétraité en plusieurs copies, format aligné) | Conseil psychologique chinois |
| BELLE | Chinois |
| tapis | Conversation chinoise |
| Distiques (prétraités en plusieurs copies, format aligné) | Chinois |
Remarque : Les données proviennent de la communauté open source et sont accessibles via des liens.
 4. Code de formation et scripts
4. Code de formation et scriptsIntroduction au code et au script :
finetune.py : Instructions pour affiner le code de démarrage à chaud/d'entraînement incrémentielgenerate.py : code d'inférence/testscripts/ : exécuter des scriptsscripts/rerun-2-alpaca-13b-2.sh , voir scripts/README.md pour une explication de chaque paramètre.  5. Comment utiliser
5. Comment utiliserVeuillez vous référer à Alpaca-LoRA pour plus de détails et les questions connexes.
pip install -r requirements.txtFusion de poids (en prenant l'alpaca-lora-13b comme exemple) :
cd scripts/
bash merge-13b-alpaca.shSignification du paramètre (veuillez modifier vous-même le chemin concerné) :
--base_model , poids original du lama--lora_model , poids du lama chinois/alpaga-lora--output_dir , chemin vers la sortie des poids de fusionPrenons le processus de formation suivant comme exemple pour montrer le script en cours d'exécution.
| commencer | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaga-lora-13b-hot start, numéro d'expérience : 2 | Données : luciole-train-0 | Données : COIG-part1, COIG-traduction | Données : PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shExplication des paramètres importants (veuillez modifier vous-même les chemins concernés) :
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 Si l'ensemble de données lui-même est relativement petit, il peut être réduit de manière appropriée, par exemple 500, 200Notez que si vous souhaitez télécharger directement les poids affinés pour l'inférence, vous pouvez ignorer 5.3 et passer directement à 5.4.
Par exemple, je souhaite évaluer les résultats du réglage fin rerun-2-alpaca-13b-2.sh :
1. Interaction avec la version Web :
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Inférence par lots et enregistrement des résultats :
cd scripts/
bash save-generate-2-alpaca-13b-2.shExplication des paramètres importants (veuillez modifier vous-même les chemins concernés) :
--is_ui False : Qu'il s'agisse d'une version web, la valeur par défaut est True--test_input_path 'xxx.json' : chemin des instructions d'entréetest.json dans le répertoire de poids LoRA correspondant.  6. Rapport d'évaluation
6. Rapport d'évaluation Il existe actuellement 8 types de tâches de test dans les échantillons d'évaluation (éthique numérique et dialogue Duolun à évaluer), chaque catégorie comporte 10 échantillons et la version quantifiée 8 bits est notée selon l'interface appelant GPT-4/GPT 3.5 ( la version non quantifiée a un score plus élevé), chaque échantillon est noté sur une plage de 0 à 10. Voir test_data/ pour des exemples d'évaluation.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Remarque : La notation est à titre de référence uniquement (par rapport à GPT 3.5). La notation de GPT 4 est plus précise et plus informative.
| Tâches de test | Exemple détaillé | Nombre d'échantillons | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Score total pour chaque élément | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Anecdote | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| traduire | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| génération de texte | 03générer.json | 10 | 56 | 65* | 55 | 61 | 91 |
| analyse des sentiments | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| compréhension écrite | 05compréhension.json | 10 | 74* | 74* | 74* | 76,5 | 96,5 |
| Caractéristiques chinoises | 06chinois.json | 10 | 69* | 69* | 69* | 43 | 86 |
| génération de code | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Éthique, Refus de répondre | 08alignement.json | 10 | 87* | 87* | 87* | 71 | 95,5 |
| raisonnement mathématique | (à évaluer) | -- | -- | -- | -- | -- | -- |
| Plusieurs cycles de dialogue | (à évaluer) | -- | -- | -- | -- | -- | -- |
| Tâches de test | Exemple détaillé | Nombre d'échantillons | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Score total pour chaque élément | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Anecdote | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| traduire | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| génération de texte | 03générer.json | 10 | 65 | 73* | 63 | 71 | 92 |
| analyse des sentiments | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| compréhension écrite | 05compréhension.json | 10 | 75 | 77 | 76 | 85* | 91 |
| Caractéristiques chinoises | 06chinois.json | 10 | 82* | 83 | 82* | 40 | 68 |
| génération de code | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Éthique, Refus de répondre | 08alignement.json | 10 | 71* | 70 | 67 | 71* | 94 |
| raisonnement mathématique | (à évaluer) | -- | -- | -- | -- | -- | -- |
| Plusieurs cycles de dialogue | (à évaluer) | -- | -- | -- | -- | -- | -- |
Dans l'ensemble, le modèle a de bonnes performances en traduction , analyse des sentiments , compréhension en lecture , etc.
Deux personnes ont noté manuellement puis ont fait la moyenne.
| Tâches de test | Exemple détaillé | Nombre d'échantillons | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Score total pour chaque élément | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Anecdote | 01qa.json | 10 | 83* | 82 | 82 | 69,75 | 96.25 |
| traduire | 02translate.json | 10 | 76,5* | 76,5* | 76,5* | 62,5 | 84 |
| génération de texte | 03générer.json | 10 | 44 | 51,5* | 43 | 47 | 81,5 |
| analyse des sentiments | 04analyse.json | 10 | 89* | 89* | 89* | 85,5 | 91 |
| compréhension écrite | 05compréhension.json | 10 | 69* | 69* | 69* | 75,75 | 96 |
| Caractéristiques chinoises | 06chinois.json | 10 | 55* | 55* | 55* | 37,5 | 87,5 |
| génération de code | 07code.json | 10 | 61,5* | 61,5* | 61,5* | 57 | 88,5 |
| Éthique, Refus de répondre | 08alignement.json | 10 | 84* | 84* | 84* | 70 | 95,5 |
| éthique numérique | (à évaluer) | -- | -- | -- | -- | -- | -- |
| Plusieurs cycles de dialogue | (à évaluer) | -- | -- | -- | -- | -- | -- |
 7. Contenu de la mise à jour de la prochaine version
7. Contenu de la mise à jour de la prochaine versionListe À FAIRE :
 Limitations, restrictions d'utilisation et clauses de non-responsabilité
Limitations, restrictions d'utilisation et clauses de non-responsabilitéLe modèle SFT formé sur la base des données actuelles et des modèles de base présente toujours les problèmes suivants en termes d'efficacité :
Les instructions factuelles peuvent conduire à des réponses incorrectes qui vont à l’encontre des faits.
Les instructions préjudiciables ne peuvent pas être correctement identifiées, ce qui peut conduire à des remarques discriminatoires, préjudiciables et contraires à l'éthique.
Les capacités du modèle doivent encore être améliorées dans certains scénarios impliquant du raisonnement, du codage, de multiples cycles de dialogue, etc.
Sur la base des limites du modèle ci-dessus, nous exigeons que le contenu de ce projet et les dérivés ultérieurs générés par ce projet puissent être utilisés uniquement à des fins de recherche universitaire et non à des fins commerciales ou pour des utilisations préjudiciables à la société. Le développeur du projet n'assume aucun préjudice, perte ou responsabilité légale causé par l'utilisation de ce projet (y compris, mais sans s'y limiter, les données, modèles, codes, etc.).
 Citation
CitationSi vous utilisez le code, les données ou les modèles de ce projet, merci de citer ce projet.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Contactez-nous
Contactez-nousIl y a encore de nombreuses lacunes dans ce projet. Veuillez laisser vos suggestions et questions et nous ferons de notre mieux pour améliorer ce projet.
Courriel : [email protected]


