datalens
1.0.0
Il s'agit d'une expérience personnelle qui utilise des LLM pour classer les données d'emploi non structurées en fonction de critères définis par l'utilisateur. Les plateformes de recherche d’emploi traditionnelles s’appuient sur des systèmes de filtrage rigides, mais de nombreux utilisateurs ne disposent pas de critères aussi concrets. Datalens vous permet de définir vos préférences de manière plus naturelle, puis d'évaluer chaque offre d'emploi en fonction de sa pertinence.
Certains critères peuvent être plus importants que d’autres, c’est pourquoi les « critères obligatoires » sont pondérés deux fois plus que les critères normaux.
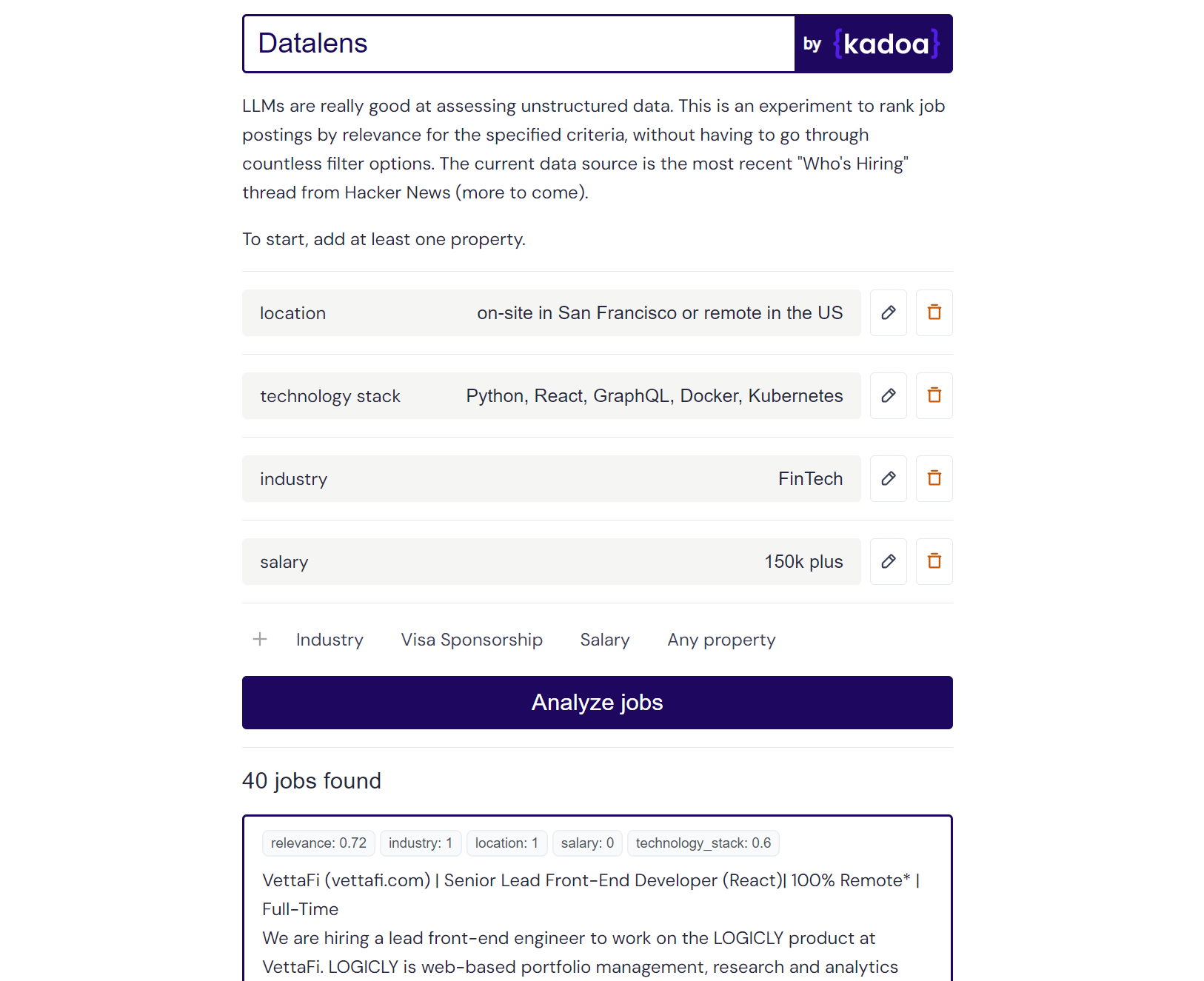
Exemple de résultat Claude-2 :
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Vous pouvez ajouter n'importe quelle source de données de travail de votre choix. Je l'ai préconfiguré avec le fil de discussion "Who's Hiring" le plus récent de Hacker News, mais vous pouvez ajouter vos propres sources.
Ajoutez de nouvelles sources de tâches en mettant à jour sources_config.json. Exemple:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
J'ai utilisé mon propre outil Kadoa pour récupérer les données de travail à partir des pages de l'entreprise, mais vous pouvez utiliser n'importe quelle autre méthode de scraping traditionnelle.
Voici quelques points de terminaison publics prêts à l'emploi pour obtenir toutes les offres d'emploi de ces entreprises (mis à jour quotidiennement) :
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Faites-moi savoir si vous devez ajouter d'autres sociétés. Nous sommes également heureux de vous donner un accès d'essai à Kadoa.
Le score de pertinence fonctionne mieux avec gpt-4-0613 qui renvoie des scores granulaires compris entre 0 et 1. claude-2 fonctionne très bien aussi si vous y avez accès. gpt-3.5-turbo-0613 peut être utilisé, mais il renvoie souvent des scores binaires de 0 ou 1 pour les critères, sans la nuance nécessaire pour faire la distinction entre les correspondances partielles et complètes.
Le modèle par défaut est gpt-3.5-turbo-0613 pour des raisons de coût. Vous pouvez passer de GPT à Claude en remplaçant use_claude par use_openai .
L'exécution continue de ce script peut entraîner une utilisation élevée de l'API, veuillez donc l'utiliser de manière responsable. J'enregistre le coût de chaque appel GPT.
Pour exécuter l'application, vous avez besoin de :
Copiez le fichier .env.example et remplissez-le.
Exécutez le serveur Flask :
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Accédez au répertoire client et installez les dépendances de nœud :
cd client
npm install
Exécutez le client Next.js :
cd client
npm run dev


