multimedia gpt
1.0.0
Multimedia GPT connecte votre OpenAI GPT à la vision et à l'audio. Vous pouvez désormais envoyer des images, des enregistrements audio et des documents PDF à l'aide de votre clé API OpenAI et obtenir une réponse aux formats texte et image. Nous ajoutons actuellement la prise en charge des vidéos. Tout est rendu possible par un gestionnaire d'invites inspiré et construit sur Microsoft Visual ChatGPT.
En plus de tous les modèles de base de vision mentionnés dans Microsoft Visual ChatGPT, Multimedia GPT prend en charge OpenAI Whisper et OpenAI DALLE ! Cela signifie que vous n'avez plus besoin de vos propres GPU pour la reconnaissance vocale et la génération d'images (même si vous le pouvez toujours !)
Le modèle de discussion de base peut être configuré comme n'importe quel OpenAI LLM , y compris ChatGPT et GPT-4. Nous utilisons par défaut text-davinci-003 .
Vous êtes invités à lancer ce projet et à ajouter des modèles adaptés à votre propre cas d'utilisation. Un moyen simple de procéder consiste à utiliser llama_index. Vous devrez créer une nouvelle classe pour votre modèle dans model.py et ajouter une méthode d'exécution run_<model_name> dans multimedia_gpt.py . Voir run_pdf pour un exemple.
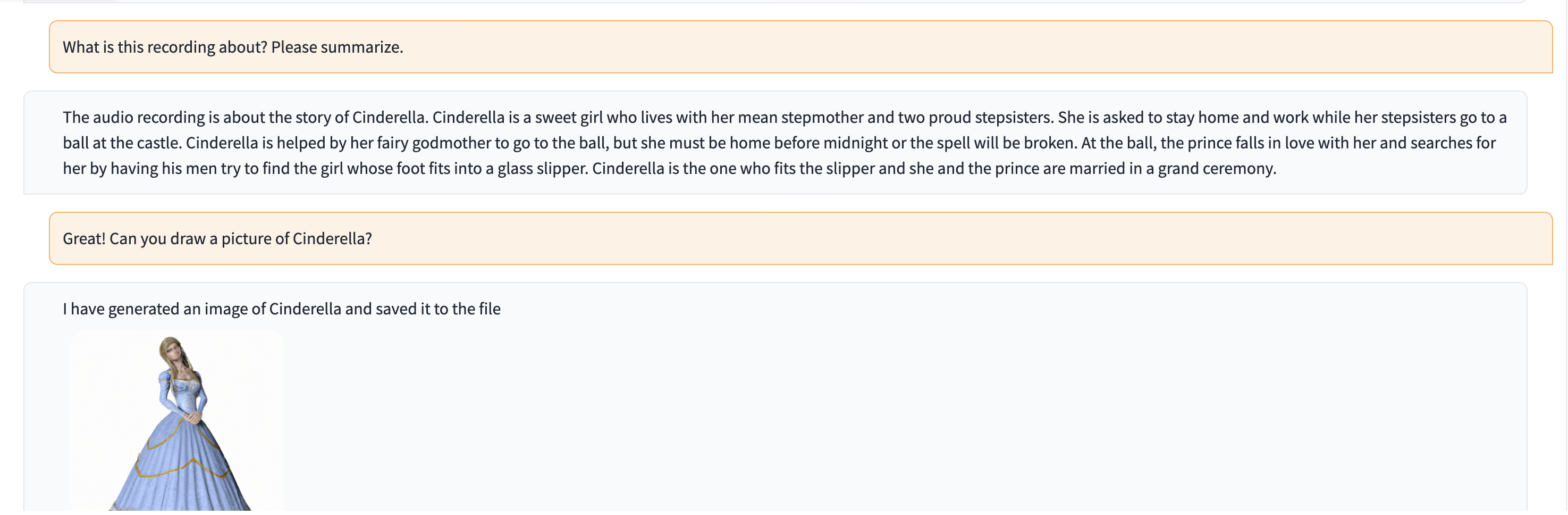
Dans cette démo, ChatGPT est alimenté par un enregistrement d'une personne racontant l'histoire de Cendrillon.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Ce projet est un travail expérimental et ne sera pas déployé dans un environnement de production. Notre objectif est d’explorer le pouvoir de l’incitation.


