SwiftInfer
1.0.0
Streaming-LLM est une technique permettant de prendre en charge une longueur d'entrée infinie pour l'inférence LLM. Il exploite Attention Sink pour empêcher l’effondrement du modèle lorsque la fenêtre d’attention se déplace. Le travail original est implémenté dans PyTorch, nous proposons SwiftInfer , une implémentation TensorRT pour rendre StreamingLLM plus adapté à la production. Notre implémentation s'appuie sur le projet TensorRT-LLM récemment publié.
Nous utilisons l'API de TensorRT-LLM pour construire le modèle et exécuter l'inférence. Comme l'API de TensorRT-LLM n'est pas stable et évolue rapidement, nous lions notre implémentation au commit 42af740db51d6f11442fd5509ef745a4c043ce51 dont la version est v0.6.0 . Nous pourrons mettre à niveau ce référentiel à mesure que les API de TensorRT-LLM deviennent plus stables.
Si vous avez build TensorRT-LLM V0.6.0 , exécutez simplement :
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .Sinon, vous devez d'abord installer TensorRT-LLM.
Si vous utilisez Docker, vous pouvez suivre l'installation de TensorRT-LLM pour installer TensorRT-LLM V0.6.0 .
En utilisant Docker, vous pouvez installer SwiftInfer en exécutant simplement :
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Si vous n'utilisez pas Docker, nous fournissons un script pour installer automatiquement TensorRT-LLM.
Conditions préalables
Veuillez vous assurer que vous avez installé les packages suivants :
Assurez-vous que la version de TensorRT >= 9.1.0 et de la boîte à outils CUDA >= 12.2.
Pour installer Tensorrt :
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Pour télécharger nccl, suivez la page de téléchargement NCCL.
Pour télécharger cudnn, suivez la page de téléchargement de cuDNN.
Commandes
Avant d'exécuter les commandes suivantes, assurez-vous d'avoir correctement défini nvcc . Pour le vérifier, exécutez :
nvcc --versionPour installer TensorRT-LLM et SwiftInfer, exécutez :
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Pour exécuter l'exemple Llama, vous devez d'abord cloner le référentiel Hugging Face pour le modèle meta-llama/Llama-2-7b-chat-hf ou d'autres variantes basées sur Llama telles que lmsys/vicuna-7b-v1.3. Ensuite, vous pouvez exécuter la commande suivante pour créer le moteur TensorRT. Vous devez remplacer <model-dir> par le chemin réel vers le modèle Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1Ensuite, vous devez télécharger les données MT-Bench fournies par LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlEnfin, vous êtes prêt à exécuter l'exemple Llama avec la commande suivante.
❗️❗️❗️ Avant cela, veuillez noter que :
only_n_first est utilisé pour contrôler le nombre d'échantillons à évaluer. Si vous souhaitez évaluer tous les échantillons, veuillez supprimer cet argument. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Vous devriez vous attendre à voir la génération comme suit :
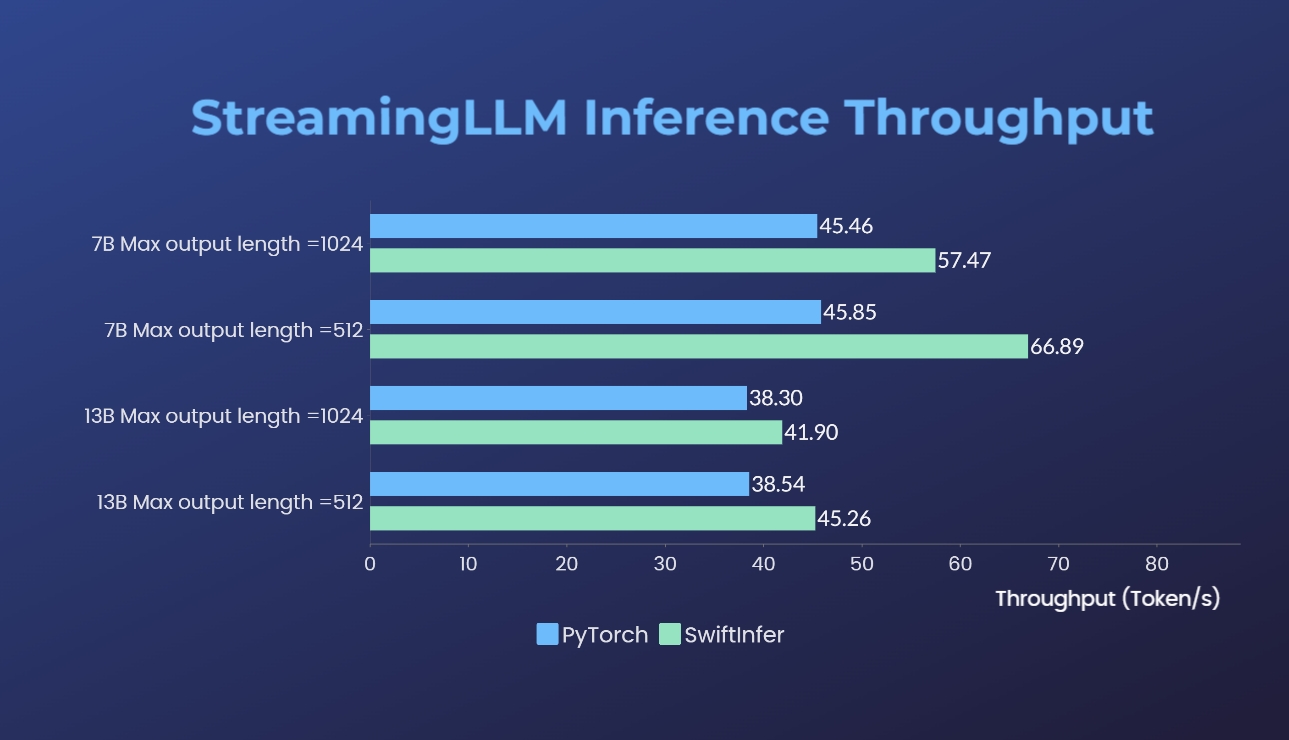
Nous avons comparé nos implémentations de Streaming-LLM avec la version originale de PyTorch. La commande de référence pour notre implémentation est donnée dans la section Exemple d'exécution de Llama tandis que celle de l'implémentation originale de PyTorch est donnée dans le dossier torch_streamingllm. Le matériel utilisé est répertorié ci-dessous :
Les résultats (20 cycles de conversations) sont :
Nous travaillons toujours à l'amélioration des performances et à l'adaptation aux API TensorRT V0.7.1. Nous remarquons également que TensorRT-LLM a intégré StreamingLLM dans son exemple, mais il semble qu'il soit plus adapté à la génération de texte unique qu'aux conversations à plusieurs tours.
Ce travail s'inspire du Streaming-LLM pour le rendre utilisable en production. Tout au long du développement, nous avons référencé les documents suivants et nous souhaitons reconnaître leurs efforts et leur contribution à la communauté open source et au monde universitaire.
Si vous trouvez StreamingLLM et notre implémentation TensorRT utiles, veuillez citer notre référentiel et le travail original proposé par Xiao et al. du laboratoire Han du MIT.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}