BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT est un projet exploratoire conçu pour construire progressivement un modèle de langage de type GPT. Le projet commence par un modèle Bigram simple et intègre progressivement les concepts avancés de l'architecture du modèle Transformer.
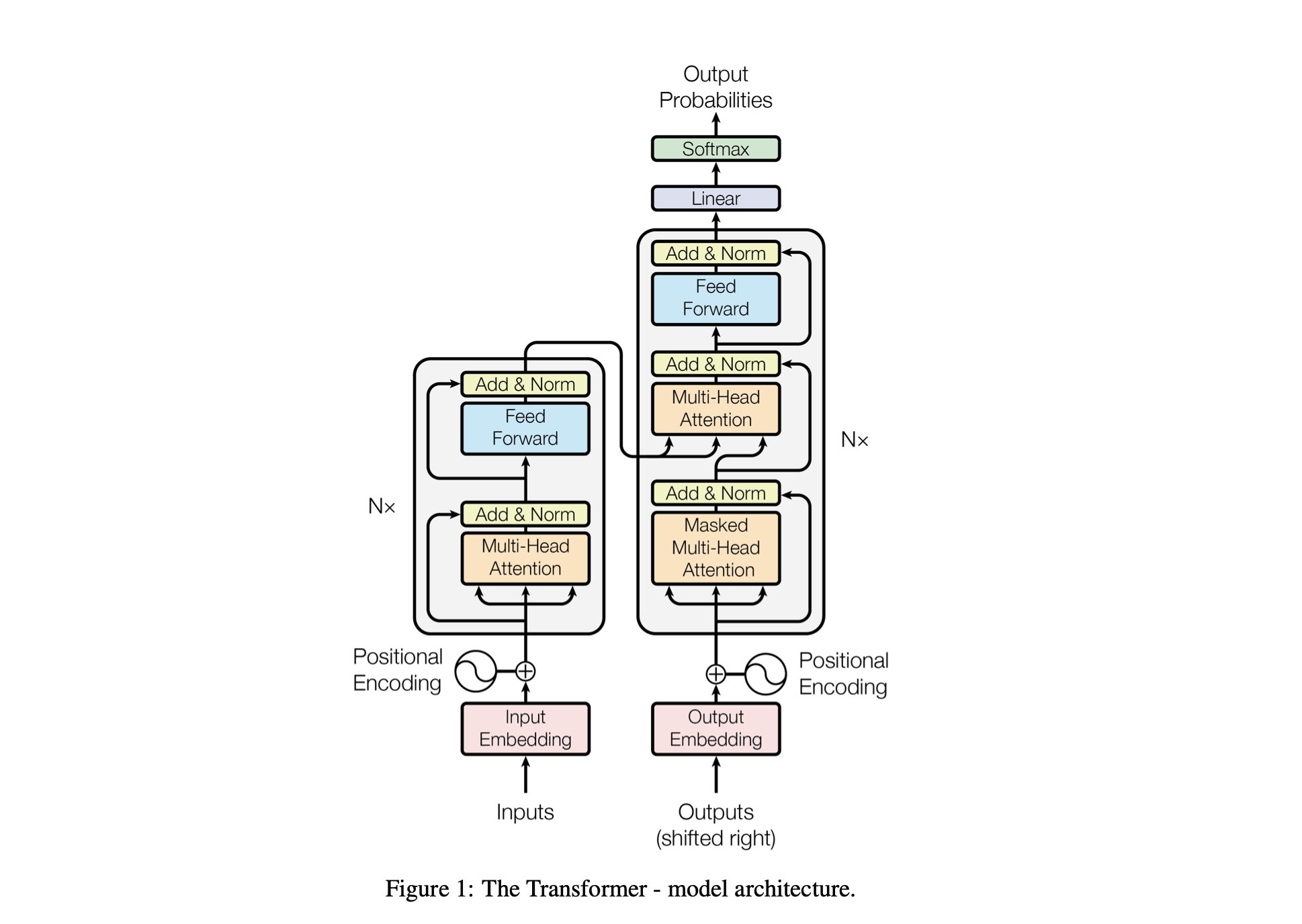
Les performances du modèle sont ajustées à l'aide des hyperparamètres suivants :
batch_size : Le nombre de séquences traitées en parallèle lors de l'entraînementblock_size : La longueur des séquences traitées par le modèled_model : Le nombre de fonctionnalités dans le modèle (la taille des intégrations)d_k : Le nombre de fonctionnalités par tête d'attention.num_iter : Le nombre total d'itérations d'entraînement que le modèle exécuteraNx : Le nombre de blocs de transformateur, ou couches, dans le modèle.eval_interval : L'intervalle auquel la perte du modèle est calculée et évaluéelr_rate : Le taux d'apprentissage pour l'optimiseur Adamdevice : automatiquement défini sur 'cuda' si un GPU compatible est disponible, sinon la valeur par défaut est 'cpu' .eval_iters : le nombre d'itérations sur lequel faire la moyenne de la perte d'évaluationh : Le nombre de têtes d'attention dans le mécanisme d'attention multi-têtesdropout_rate : Le taux d'abandon utilisé pendant l'entraînement pour éviter le surapprentissageCes hyperparamètres ont été soigneusement choisis pour équilibrer la capacité du modèle à apprendre des données sans surajustement et à gérer efficacement les ressources informatiques.
| Hyperparamètre | Modèle de processeur | Modèle de GPU |
|---|---|---|
device | 'processeur' | 'cuda' si disponible, sinon 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0,2 | 0,2 |
lr_rate | 0,005 (5e-3) | 0,001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int et int_to_chars .encode et inversement avec la fonction decode .train_data ) et de validation ( valid_data ).get_batch prépare les données en mini-batchs pour la formation.BigramLM .Le mini-batching est une technique d'apprentissage automatique dans laquelle les données d'entraînement sont divisées en petits lots. Chaque mini-lot est traité séparément lors de la formation du modèle. Cette approche permet de :
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Facteur | Petite taille de lot | Grande taille de lot |
|---|---|---|
| Bruit de dégradé | Plus élevé (plus de variance dans les mises à jour) | Inférieur (mises à jour plus cohérentes) |
| Convergence | A tendance à explorer davantage de solutions, y compris des minimums plus plats | Converge souvent vers des minima plus nets |
| Généralisation | Potentiellement meilleur (en raison de minimums plus plats) | Potentiellement pire (en raison de minimums plus nets) |
| Biais | Inférieur (moins susceptible de suradapter aux modèles de données d'entraînement) | Plus élevé (peut être suradapté aux modèles de données d'entraînement) |
| Variance | Plus élevé (en raison d'une plus grande exploration dans l'espace des solutions) | Inférieur (en raison de moins d’exploration dans l’espace des solutions) |
| Coût de calcul | Plus élevé par époque (plus de mises à jour) | Inférieur par époque (moins de mises à jour) |
| Utilisation de la mémoire | Inférieur | Plus haut |
La estimate_loss calcule la perte moyenne du modèle sur un nombre spécifié d'itérations (eval_iters). Il est utilisé pour évaluer les performances du modèle sans affecter ses paramètres. Le modèle est défini en mode d'évaluation pour désactiver certaines couches comme l'abandon pour un calcul de perte cohérent. Après avoir calculé la perte moyenne pour les données de formation et de validation, le modèle revient en mode formation. Cette fonction est essentielle pour suivre le processus de formation et procéder aux ajustements si nécessaire.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Encodage positionnel : ajout d'informations de position au modèle avec le positional_encodings_table dans la classe BigramLM . Nous ajoutons des encodages positionnels aux intégrations de nos personnages comme dans l'architecture du transformateur.
Ici, nous avons configuré et utilisé l'optimiseur AdamW pour former un modèle de réseau neuronal dans PyTorch. L'optimiseur Adam est privilégié dans de nombreux scénarios d'apprentissage profond car il combine les avantages de deux autres extensions de descente de gradient stochastique : AdaGrad et RMSProp. Adam calcule les taux d'apprentissage adaptatif pour chaque paramètre. En plus de stocker une moyenne en décroissance exponentielle des gradients carrés passés comme RMSProp, Adam conserve également une moyenne en décroissance exponentielle des gradients passés, similaire à l'élan. Cela permet à l'optimiseur d'ajuster le taux d'apprentissage pour chaque poids du réseau neuronal, ce qui peut conduire à une formation plus efficace sur des ensembles de données et des architectures complexes.
AdamW modifie la façon dont la dégradation du poids est incorporée dans le processus d'optimisation, résolvant un problème avec l'optimiseur Adam d'origine où la dégradation du poids n'est pas bien séparée des mises à jour du gradient, conduisant à une application sous-optimale de la régularisation. L'utilisation d'AdamW peut parfois entraîner de meilleures performances de formation et une généralisation à des données invisibles. Nous avons choisi AdamW pour sa capacité à gérer la perte de poids plus efficacement que l'optimiseur Adam standard, conduisant potentiellement à une amélioration de la formation et de la généralisation du modèle.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()L'auto-attention est un mécanisme qui permet au modèle de peser différemment l'importance des différentes parties des données d'entrée. Il s'agit d'un composant clé de l'architecture Transformer, permettant au modèle de se concentrer sur les parties pertinentes de la séquence d'entrée pour effectuer des prédictions.
Attention au produit scalaire : un mécanisme d'attention simple qui calcule une somme pondérée de valeurs basée sur le produit scalaire entre les requêtes et les clés.
Attention au produit scalaire à l'échelle : une amélioration par rapport à l'attention au produit scalaire qui réduit les produits scalaires en fonction de la dimensionnalité des touches, empêchant ainsi les gradients de devenir trop petits pendant la formation.
OneHeadSelfAttention : Implémentation d'un mécanisme d'auto-attention à une seule tête qui permet au modèle de s'occuper de différentes positions de la séquence d'entrée. La classe SelfAttention présente l'intuition derrière le mécanisme d'attention et sa version à l'échelle.
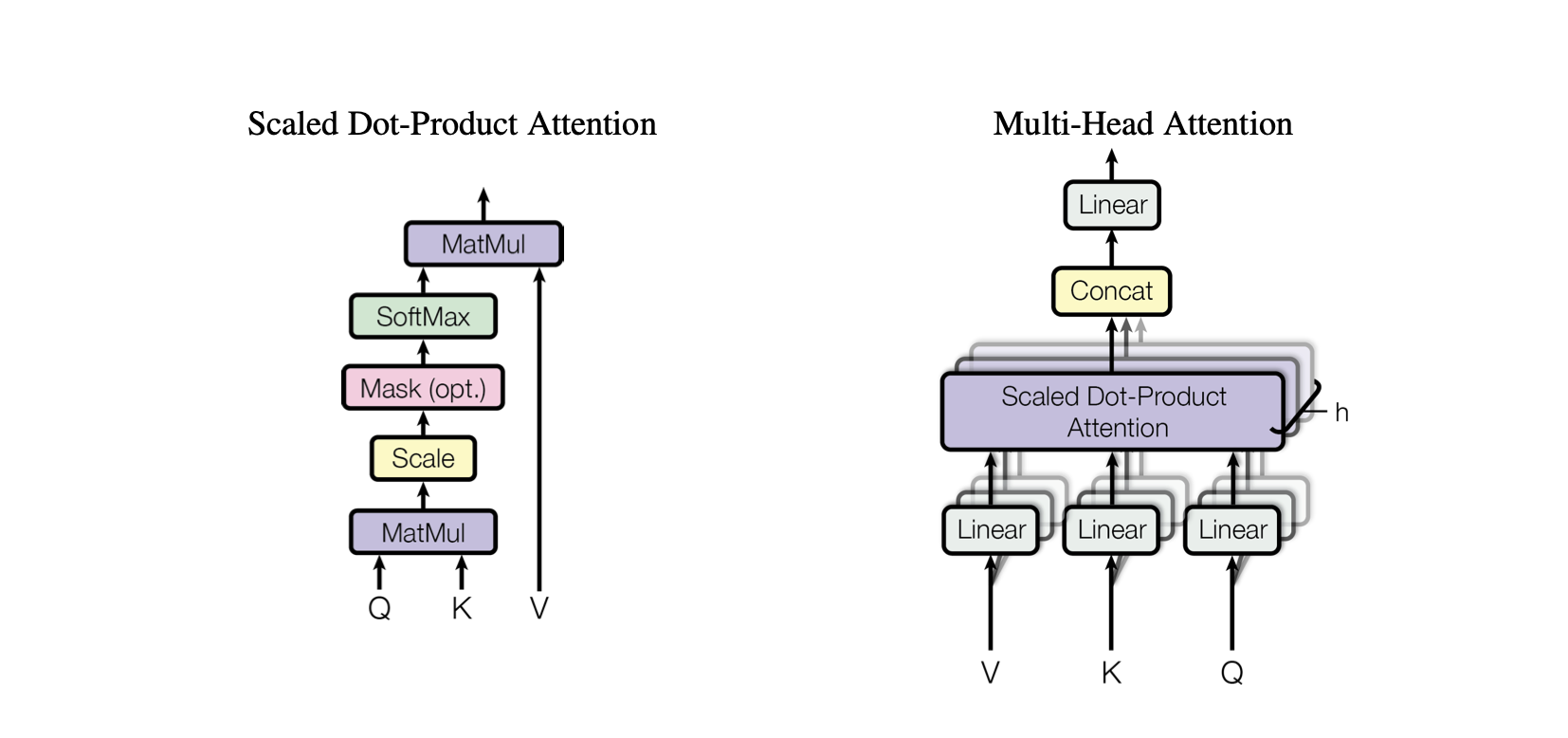
Chaque modèle correspondant dans le projet Baby GPT s'appuie progressivement sur le précédent, en commençant par l'intuition derrière le mécanisme d'auto-attention, suivi par des implémentations pratiques d'attentions de produits scalaires et de produits scalaires à l'échelle, et culminant par l'intégration d'un modèle unique. module d'auto-attention de la tête.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur La classe SelfAttention représente un élément fondamental du modèle Transformer, encapsulant le mécanisme d’auto-attention avec une seule tête. Voici un aperçu de ses composants et processus :
Initialisation : Le constructeur __init__(self, d_k) initialise les couches linéaires pour les clés, les requêtes et les valeurs, le tout avec la dimensionnalité d_k . Ces transformations linéaires projettent l'entrée dans différents sous-espaces pour des calculs d'attention ultérieurs.
Buffers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) enregistre une matrice triangulaire inférieure en tant que tampon persistant qui n'est pas considéré comme un paramètre de modèle. Cette matrice est utilisée pour le masquage dans le mécanisme d'attention afin d'éviter que les positions futures ne soient prises en compte à chaque étape de calcul (utile dans l'auto-attention du décodeur).
Forward Pass : La méthode forward(self, X) définit le calcul effectué à chaque appel du module d'auto-attention
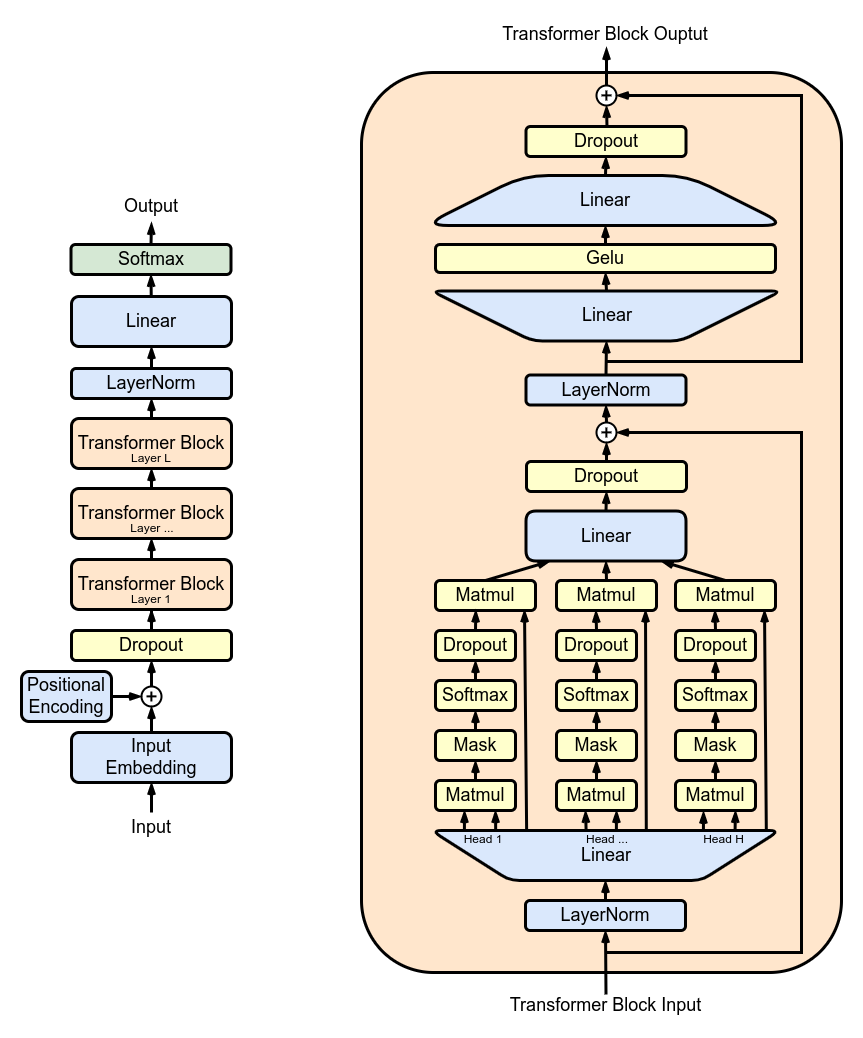
MultiHeadAttention : combinaison des sorties de plusieurs têtes SelfAttention dans la classe MultiHeadAttention . La classe MultiHeadAttention est une implémentation étendue du mécanisme d'auto-attention avec une tête de l'étape précédente, mais désormais plusieurs têtes d'attention fonctionnent en parallèle, chacune se concentrant sur différentes parties de l'entrée.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : Implémentation d'un réseau neuronal feed-forward avec activation ReLU au sein de la classe FeedForward . Pour ajouter ce feed-forward entièrement connecté à notre modèle comme dans le modèle Transformer original.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : empiler des blocs de transformateur à l'aide de la classe Block pour créer une architecture de réseau plus profonde. Profondeur et complexité : dans les réseaux de neurones, la profondeur fait référence au nombre de couches à travers lesquelles les données sont traitées. Chaque couche supplémentaire (ou bloc, dans le cas des transformateurs) permet au réseau de capturer des caractéristiques plus complexes et abstraites des données d'entrée.
Traitement séquentiel : chaque bloc Transformer traite la sortie de son bloc précédent, construisant progressivement une compréhension plus sophistiquée de l'entrée. Ce traitement séquentiel permet au réseau de développer une représentation approfondie et en couches des données. Composants d'un bloc transformateur
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : amélioration de la classe Block pour inclure des connexions résiduelles, améliorant ainsi l'efficacité de l'apprentissage. Les connexions résiduelles, également connues sous le nom de connexions sautées, constituent une innovation essentielle dans la conception de réseaux neuronaux profonds, en particulier dans les modèles Transformer. Ils abordent l’un des principaux défis de la formation de réseaux profonds : le problème du gradient de disparition.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Ajout de la normalisation des couches à nos sorties de couche Transformer.Normalizing avec nn.LayerNorm(d_model) dans la classe Block .
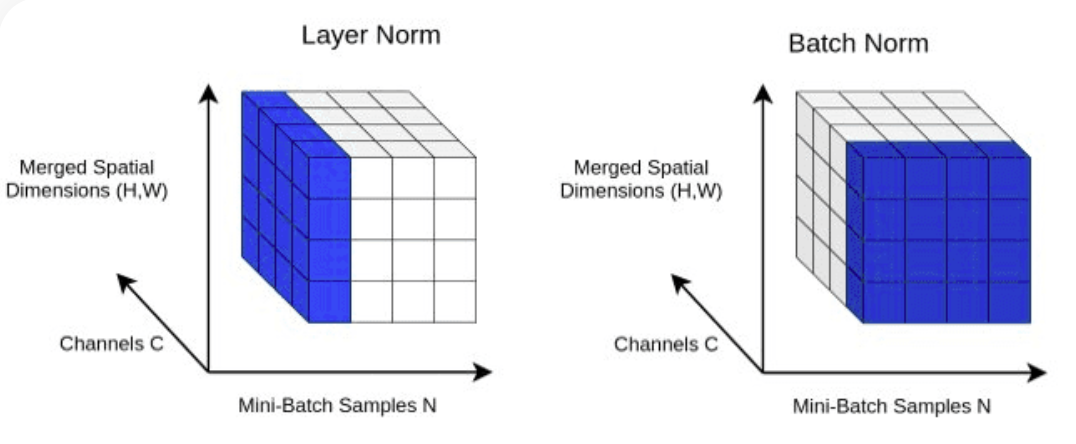
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : À ajouter aux couches SelfAttention et FeedForward comme méthode de régularisation pour éviter le surajustement. Nous ajoutons l'abandon à :
ScaleUp : augmentation de la complexité du modèle en développant batch_size , block_size , d_model , d_k et Nx . Vous aurez besoin de la boîte à outils CUDA ainsi que d'une machine avec GPU NVIDIA pour entraîner et tester ce modèle plus grand.
Si vous souhaitez essayer CUDA pour l'accélération GPU, assurez-vous que vous disposez de la version appropriée de PyTorch qui prend en charge CUDA.
import torch
torch . cuda . is_available ()Vous pouvez le faire en spécifiant la version CUDA dans votre commande d'installation PyTorch, comme dans la ligne de commande :
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

