ke dialogue
1.0.0


Voici la mise en œuvre du document :
Apprentissage des bases de connaissances avec paramètres pour les systèmes de dialogue orientés tâches . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung Résultats de l'EMNLP 2020 [PDF]
Si vous utilisez des codes sources ou des ensembles de données inclus dans cette boîte à outils dans votre travail, veuillez citer l'article suivant. Le bibtex est répertorié ci-dessous :
@article{madotto2020learning,
title={Bases de connaissances d'apprentissage avec paramètres pour les systèmes de dialogue orientés tâches},
author={Madotto, Andrea et Cahyawijaya, Samuel et Winata, Genta Indra et Xu, Yan et Liu, Zihan et Lin, Zhaojiang et Fung, Pascale},
journal={préimpression arXiv arXiv:2009.13656},
année={2020}
}
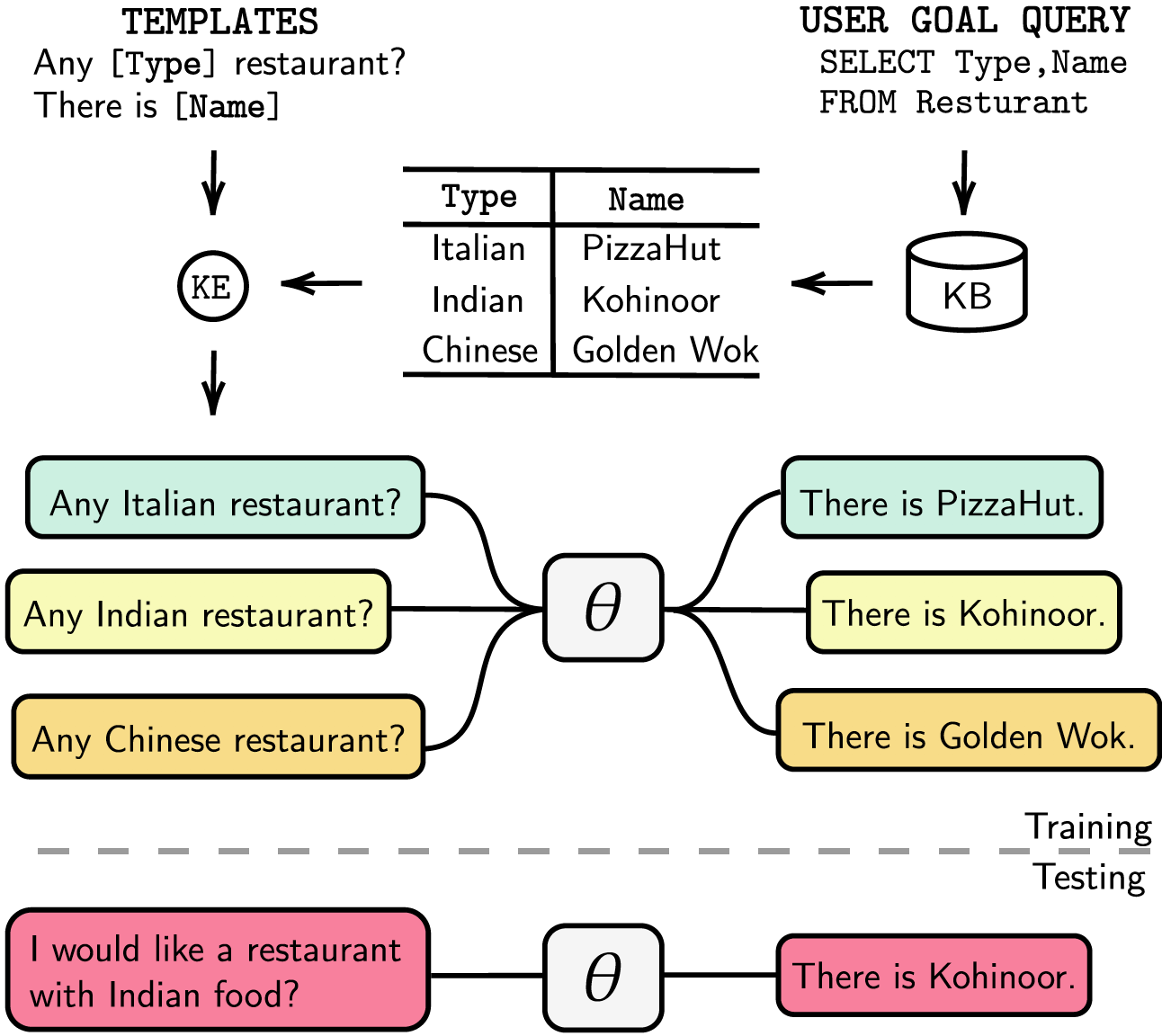
Les systèmes de dialogue orientés tâches sont soit modularisés avec des étapes de suivi de l'état du dialogue (DST) et de gestion séparées, soit formables de bout en bout. Dans les deux cas, la base de connaissances (KB) joue un rôle essentiel pour répondre aux demandes des utilisateurs. Les systèmes modularisés s'appuient sur DST pour interagir avec la base de connaissances, ce qui est coûteux en termes de temps d'annotation et d'inférence. Les systèmes de bout en bout utilisent la Ko directement comme entrée, mais ils ne peuvent pas évoluer lorsque la Ko dépasse quelques centaines d'entrées. Dans cet article, nous proposons une méthode pour intégrer la base de connaissances, de n'importe quelle taille, directement dans les paramètres du modèle. Le modèle résultant ne nécessite aucune réponse DST ou modèle, ni la base de connaissances en entrée, et il peut mettre à jour dynamiquement sa base de connaissances via un réglage fin. Nous évaluons notre solution dans cinq ensembles de données de dialogue orientés tâches avec une taille de Ko petite, moyenne et grande. Nos expériences montrent que les modèles de bout en bout peuvent intégrer efficacement des bases de connaissances dans leurs paramètres et atteindre des performances compétitives dans tous les ensembles de données évalués.
Nous avons répertorié nos dépendances sur requirements.txt , vous pouvez installer les dépendances en exécutant
❱❱❱ pip install -r requirements.txt De plus, notre code inclut également la prise en charge fp16 avec apex . Vous pouvez trouver le package sur https://github.com/NVIDIA/apex.
Ensemble de données Téléchargez l' ensemble de données prétraité et placez le fichier zip dans le dossier ./knowledge_embed/babi5 . Extrayez le fichier zip en exécutant
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipGénérez les dialogues délexicalisés à partir de l'ensemble de données bAbI-5 via
❱❱❱ python3 generate_delexicalization_babi.pyGénérez les données lexicalisées à partir de l'ensemble de données bAbI-5 via
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Où le maximum <num_augmented_knowledge> est de 558 (recommandé) et <num_augmented_dialogues> est de 264 car cela correspond au nombre de connaissances et au nombre de dialogues dans l'ensemble de données bAbI-5.
Affiner GPT-2
Nous fournissons le point de contrôle du modèle GPT-2 affiné sur l'ensemble de formation bAbI. Vous pouvez également choisir d'entraîner le modèle vous-même à l'aide de la commande suivante.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Notez que la valeur de --kbpercentage est égale à <num_augmented_dialogues> celle qui provient de la lexicalisation. Ce paramètre est utilisé pour sélectionner le fichier d'augmentation à intégrer dans l'ensemble de données du train.
Vous pouvez évaluer le modèle en exécutant le script suivant
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Scoring bAbI-5 Pour exécuter le scorer pour le modèle de tâche bAbI-5, vous pouvez exécuter la commande suivante. Le marqueur lira tous les result.json sous le dossier runs généré à partir d' evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Ensemble de données
Téléchargez l' ensemble de données prétraité et placez le fichier zip dans le dossier ./knowledge_embed/camrest . Décompressez le fichier zip en exécutant
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipGénérez les dialogues délexicalisés à partir de l'ensemble de données CamRest via
❱❱❱ python3 generate_delexicalization_CAMREST.pyGénérez les données lexicalisées à partir de l'ensemble de données CamRest via
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Où le maximum <num_augmented_knowledge> est de 201 (recommandé) et <num_augmented_dialogues> est de 156, ce qui est assez énorme car il correspond au nombre de connaissances et au nombre de dialogues dans l'ensemble de données CamRest.
Affiner GPT-2
Nous fournissons le point de contrôle du modèle GPT-2 affiné sur l'ensemble de formation CamRest. Vous pouvez également choisir d'entraîner le modèle vous-même à l'aide de la commande suivante.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Notez que la valeur de --kbpercentage est égale à <num_augmented_dialogues> celle qui provient de la lexicalisation. Ce paramètre est utilisé pour sélectionner le fichier d'augmentation à intégrer dans l'ensemble de données du train.
Vous pouvez évaluer le modèle en exécutant le script suivant
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Scoring CamRest Pour exécuter le scorer pour le modèle de tâche bAbI 5, vous pouvez exécuter la commande suivante. Le marqueur lira tous les result.json sous le dossier runs généré à partir d' evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Ensemble de données
Téléchargez l' ensemble de données prétraité et placez-le dans le dossier ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipAffiner GPT-2
Nous fournissons le point de contrôle du modèle GPT-2 affiné sur l'ensemble de formation SMD. Téléchargez le point de contrôle et placez-le dans le dossier ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsVous pouvez également choisir d'entraîner le modèle vous-même à l'aide de la commande suivante.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Préparer des dialogues intégrés aux connaissances
Tout d’abord, nous devons créer des bases de données pour les requêtes SQL.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Ensuite, nous générons des dialogues basés sur des modèles pré-conçus par domaines. La commande suivante vous permet de générer des dialogues dans le domaine weather . Veuillez remplacer weather par navigate ou schedule dans dialogue_path et les arguments domain si vous souhaitez générer des dialogues dans les deux autres domaines. Vous pouvez également modifier le nombre de modèles utilisés dans le processus de relexicalisation en modifiant l'argument num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testAdapter le modèle GPT-2 affiné à l'ensemble de test
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""Vous pouvez également accélérer le processus de réglage fin en exécutant des expériences en parallèle. Veuillez modifier le paramètre GPU dans #L14 du code.
❱❱❱ python runner_expe_SMD.py Ensemble de données
Téléchargez l' ensemble de données prétraité et placez-le dans le dossier ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipPréparez les dialogues Knowledge-Embedded (vous pouvez ignorer cette étape si vous avez téléchargé le fichier zip ci-dessus)
Vous pouvez préparer les ensembles de données en exécutant
❱❱❱ bash generate_MWOZ_all_data.shLe script shell génère les dialogues délexicalisés à partir du jeu de données MWOZ en appelant
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyAffiner GPT-2
Nous fournissons le point de contrôle du modèle GPT-2 affiné sur l'ensemble de formation MWOZ. Téléchargez le point de contrôle et placez-le dans le dossier ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsVous pouvez également choisir d'entraîner le modèle vous-même à l'aide de la commande suivante.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Mise en route Nous utilisons l'édition du serveur communautaire neo4j et la bibliothèque apoc pour traiter les données graphiques. apoc est utilisé pour paralléliser la requête dans neo4j , afin que nous puissions traiter plus rapidement les graphiques à grande échelle
Avant de passer à la section ensemble de données, vous devez vous assurer que neo4j (https://neo4j.com/download-center/#community) et apoc (https://neo4j.com/developer/neo4j-apoc/) sont installés sur votre système.
Si vous n'êtes pas familier avec les syntaxes CYPHER et apoc , vous pouvez suivre le tutoriel sur https://neo4j.com/developer/cypher/ et https://neo4j.com/blog/intro-user-defined-procedures-apoc/
Ensemble de données Téléchargez l' ensemble de données d'origine et placez le fichier zip dans le dossier ./knowledge_embed/opendialkg . Extrayez le fichier zip en exécutant
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipGénérez les dialogues délexicalisés à partir du jeu de données opendialkg via ( ATTENTION : cela nécessite environ 12 heures pour s'exécuter)
❱❱❱ python3 generate_delexicalization_DIALKG.py Ce script produira ./opendialkg/dialogkg_train_meta.pt qui sera utilisé pour générer le dialogue lexicalisé. Vous pouvez ensuite générer le dialogue lexicalisé à partir de l'ensemble de données opendialkg via
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Ce script produira des échantillons de dialogues au plus batch_size * max_iter échantillons, mais dans chaque lot, il existe une possibilité où il n'y a pas de candidat valide et résultant en moins d'échantillons. Le nombre de générations est limité par un autre facteur appelé stop_count qui arrêtera la génération si le nombre d'échantillons générés est supérieur au stop_count spécifié. Le fichier produira 4 fichiers : ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv et ./opendialkg/generation_iteration_{random_seed}.csv qui sont utilisés pour vérifier le changement de distribution du compter dans la base de données ; et ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json qui contient les échantillons générés.
Remarques :
neo4j dans generate_delexicalization_DIALKG.py et generate_dialogues_DIALKG.py .Affiner GPT-2
Nous fournissons le point de contrôle du modèle GPT-2 affiné sur l'ensemble de formation opendialkg. Vous pouvez également choisir d'entraîner le modèle vous-même à l'aide de la commande suivante.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Notez que la valeur de --kbpercentage est égale à <random_seed> celle qui provient de la lexicalisation. Ce paramètre est utilisé pour sélectionner le fichier d'augmentation à intégrer dans l'ensemble de données du train.
Vous pouvez évaluer le modèle en exécutant le script suivant
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Scoring OpenDialKG Pour exécuter le scorer pour le modèle de tâche bAbI-5, vous pouvez exécuter la commande suivante. Le marqueur lira tous les result.json sous le dossier runs généré à partir d' evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Pour les détails concernant les expériences, les hyperparamètres et les résultats de l'évaluation, vous pouvez les trouver dans l'article principal et les documents supplémentaires de notre travail.


