T2M GPT
1.0.0
Implémentation Pytorch de l'article "T2M-GPT : Générer un mouvement humain à partir de descriptions textuelles avec des représentations discrètes"
[Page du projet] [Papier] [Démo du notebook] [HuggingFace] [Démo de l'espace] [T2M-GPT+]

Si notre projet est utile pour votre recherche, pensez à citer :
@inproceedings{zhang2023generating,
title={T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations},
author={Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Huang, Shaoli and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
| Texte : un homme s’avance et fait le poirier. | ||||
|---|---|---|---|---|
| GT | T2M | MDM | MouvementDiffuse | La nôtre |
 | 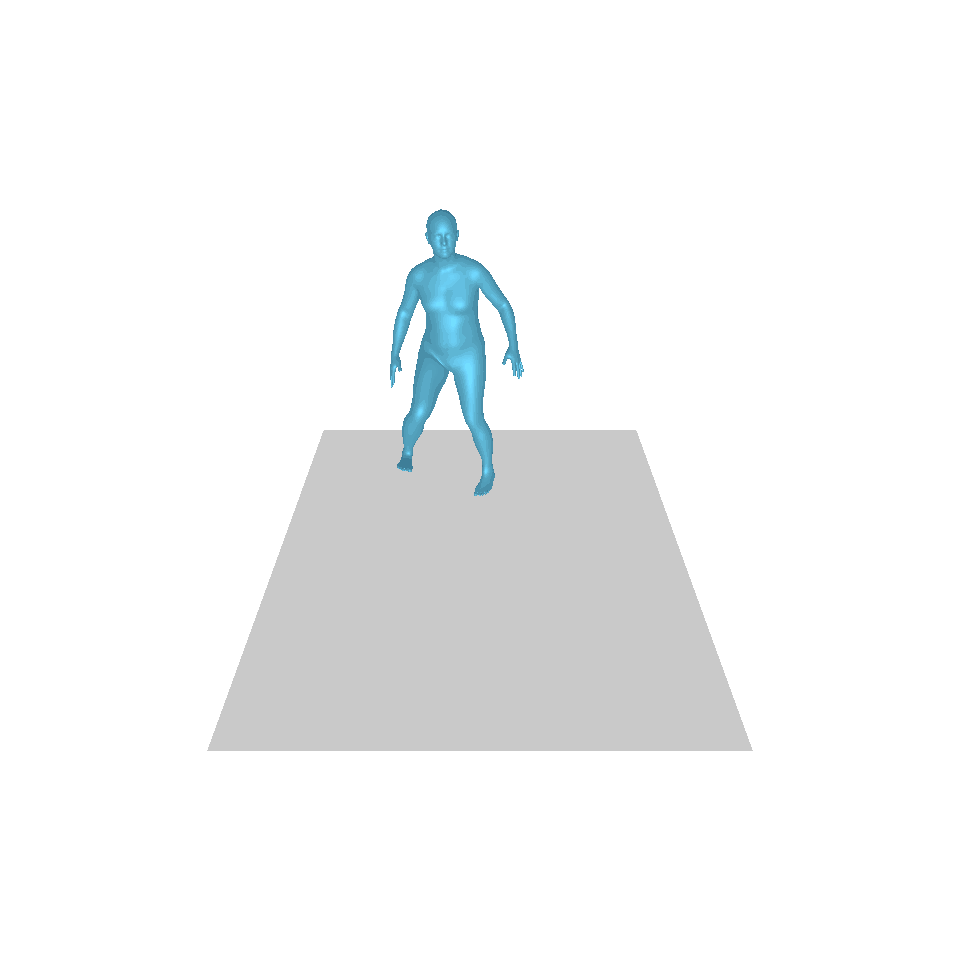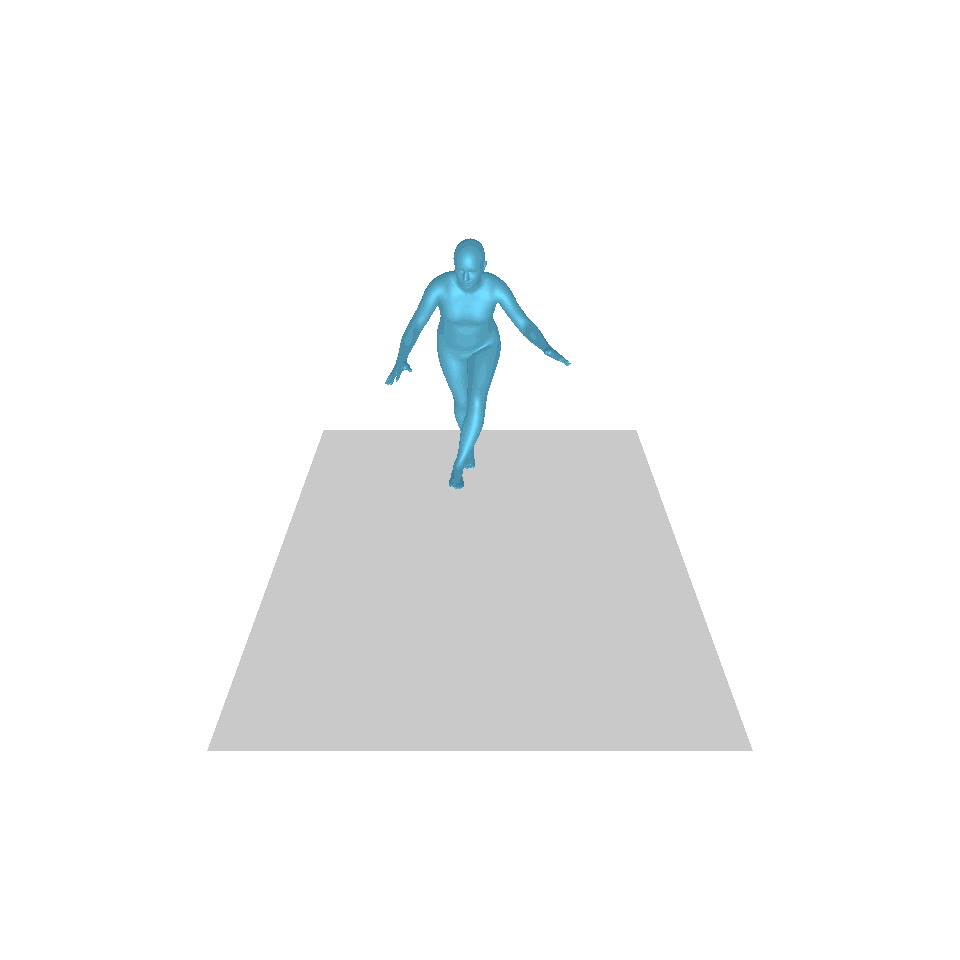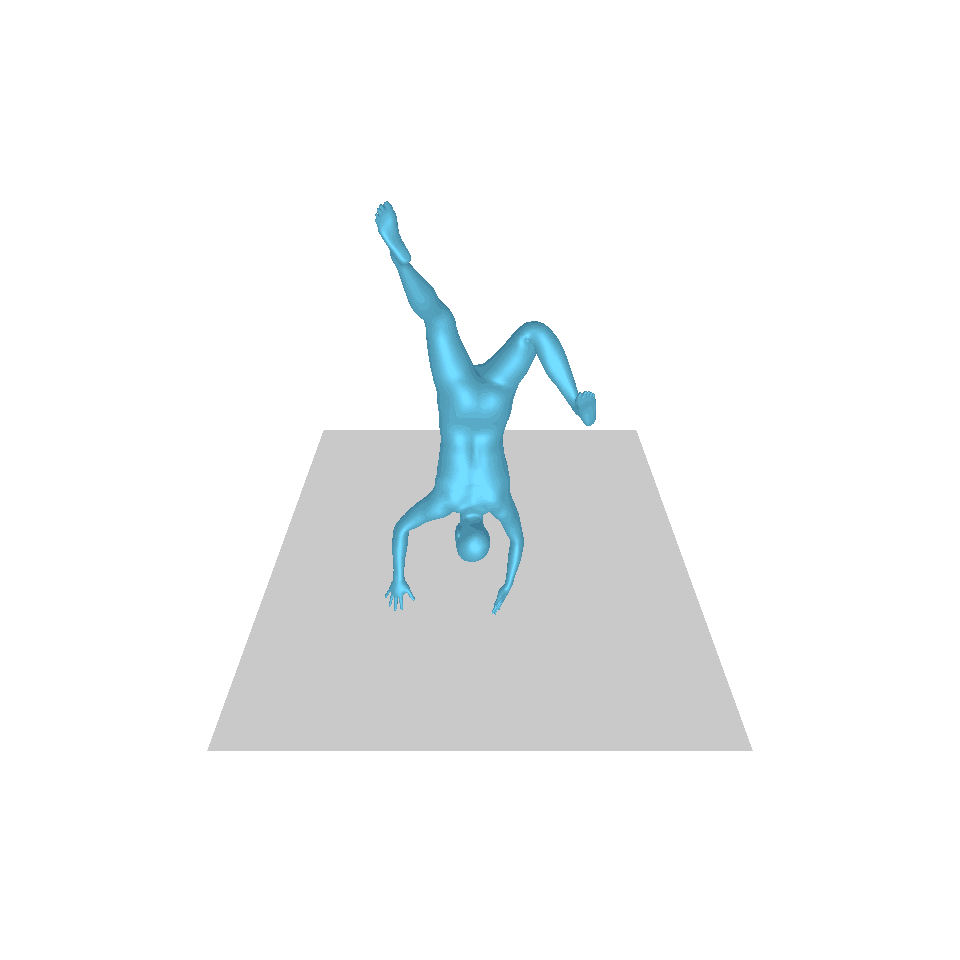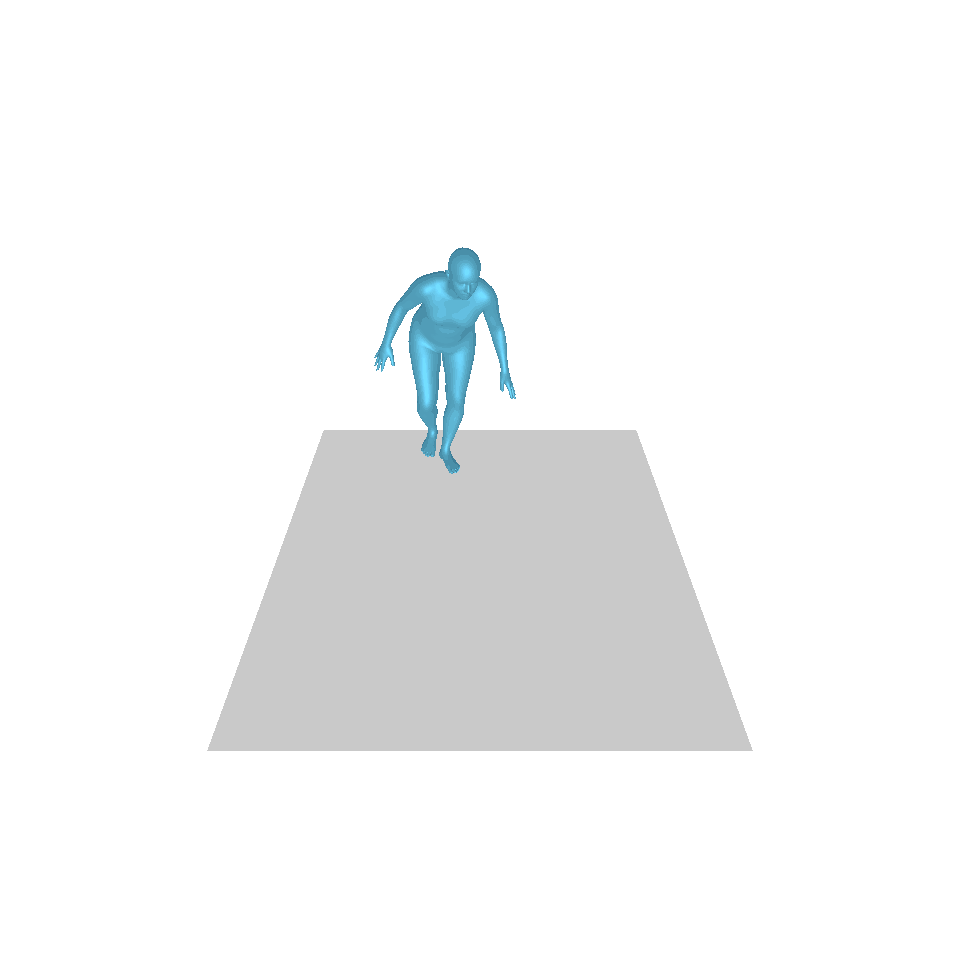 |  | 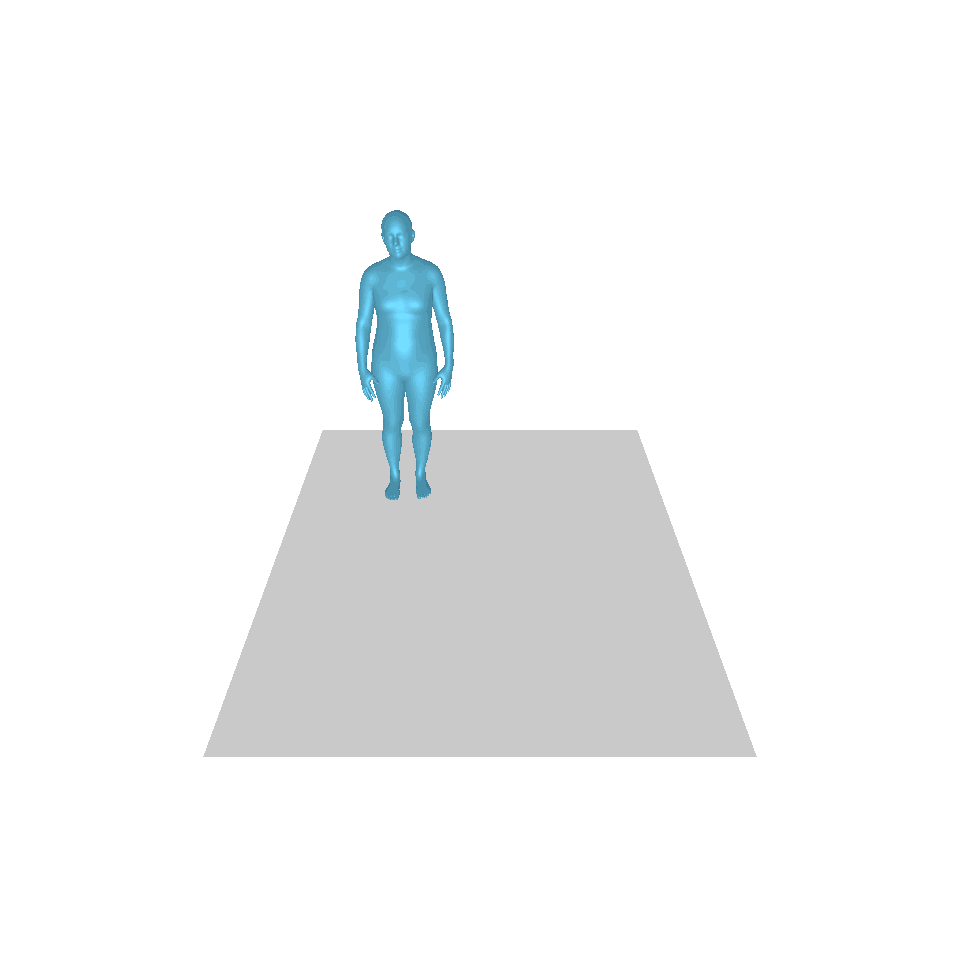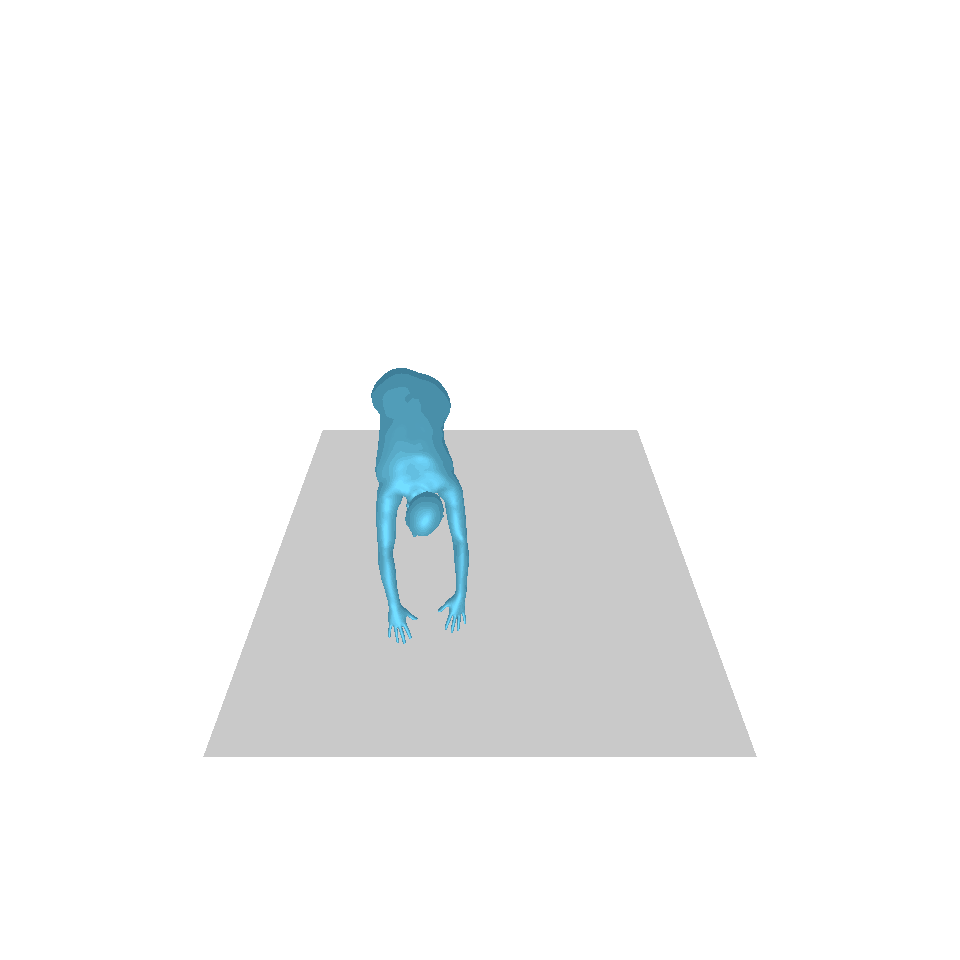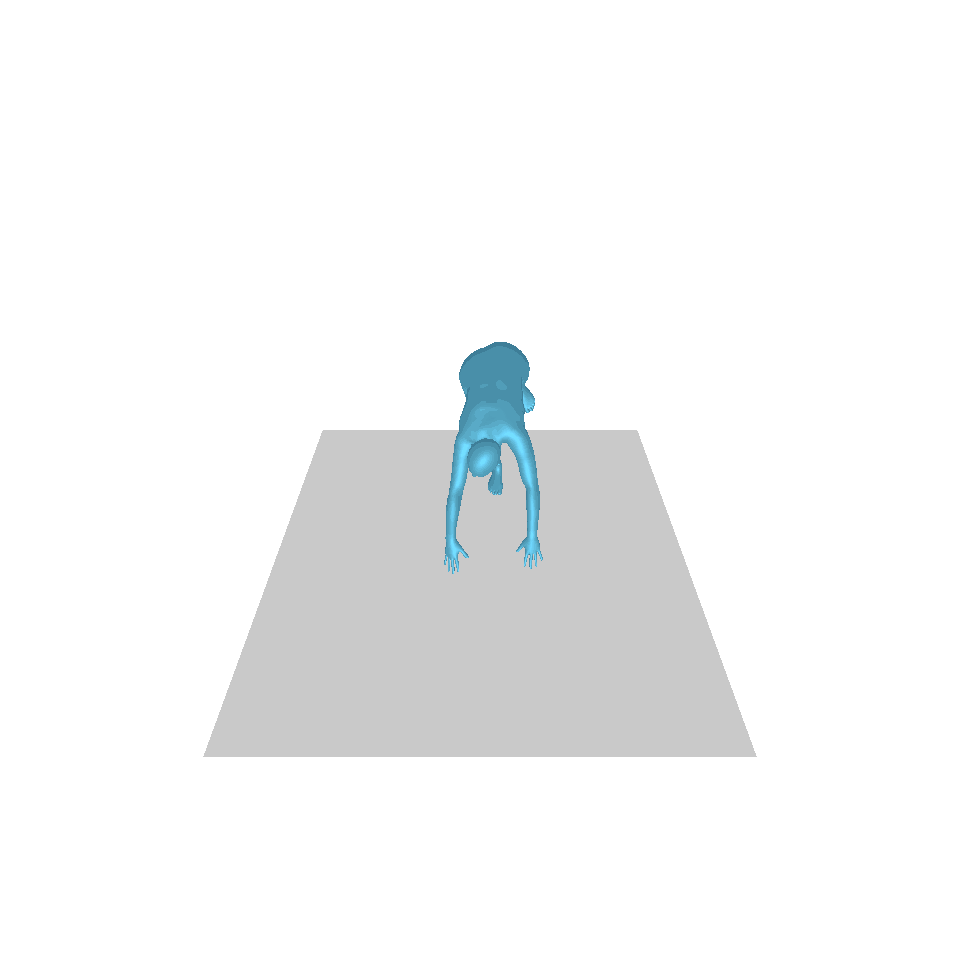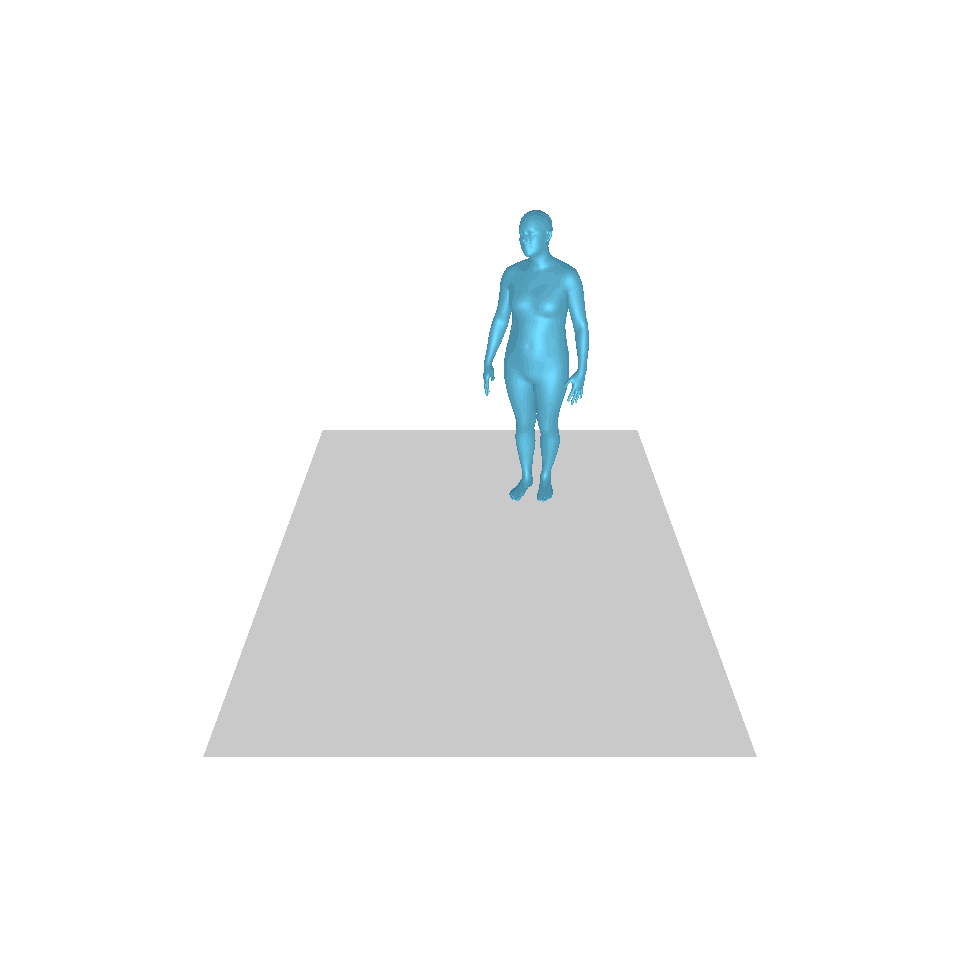 | 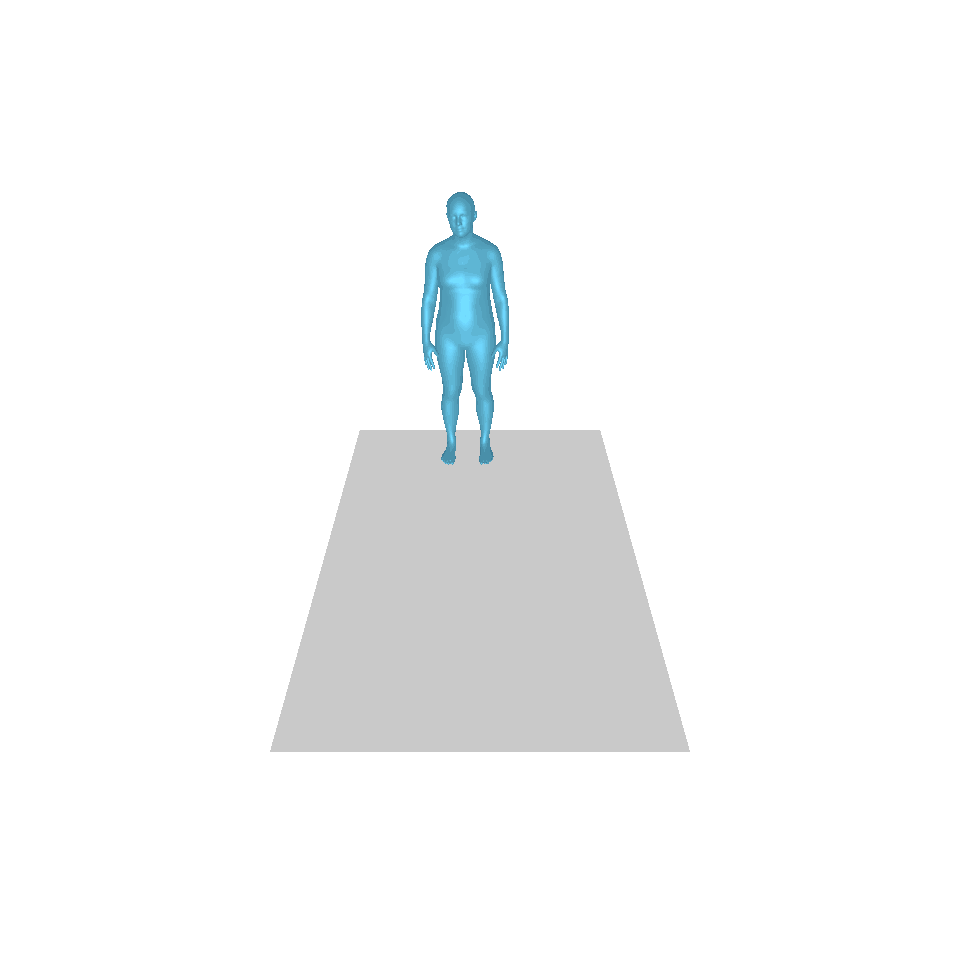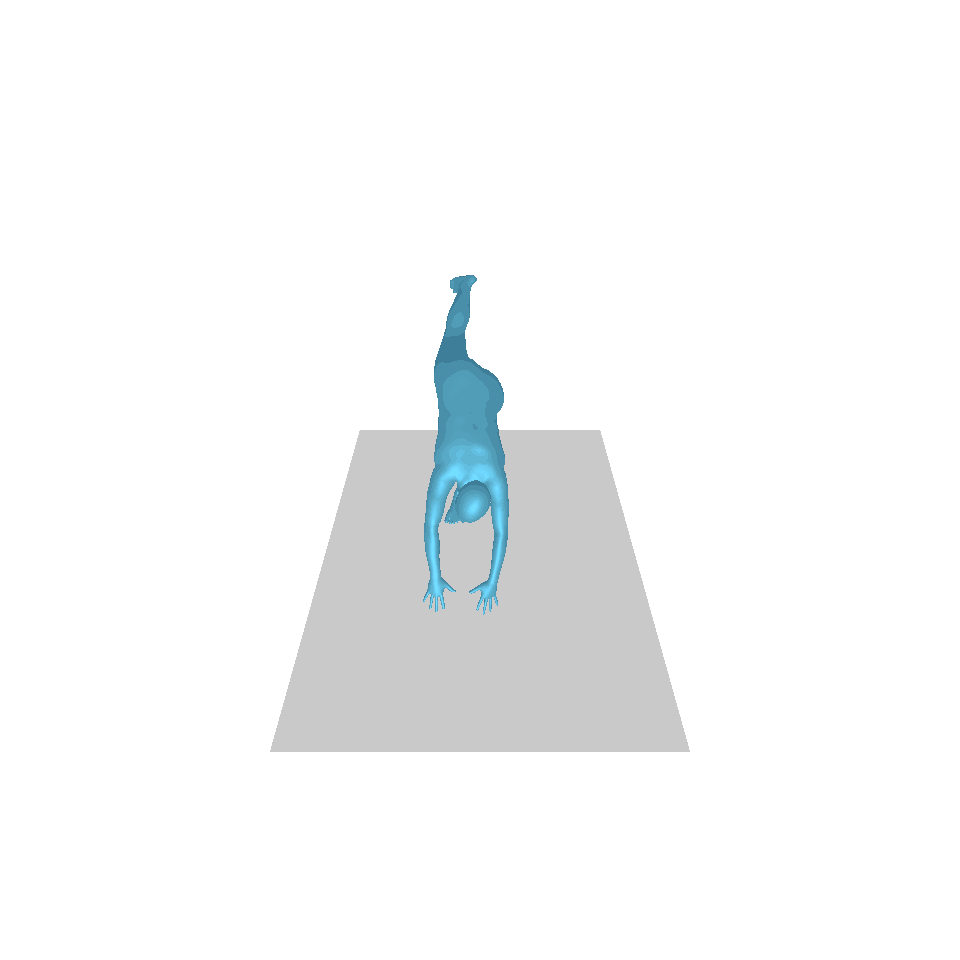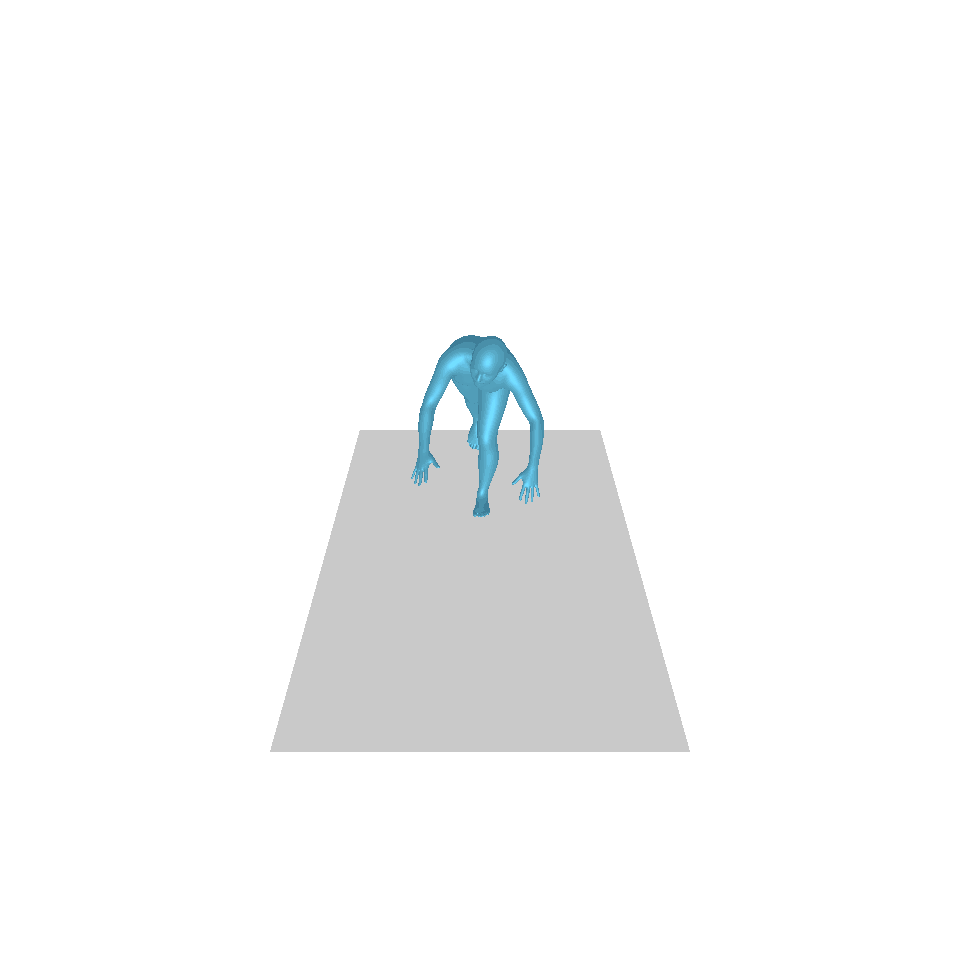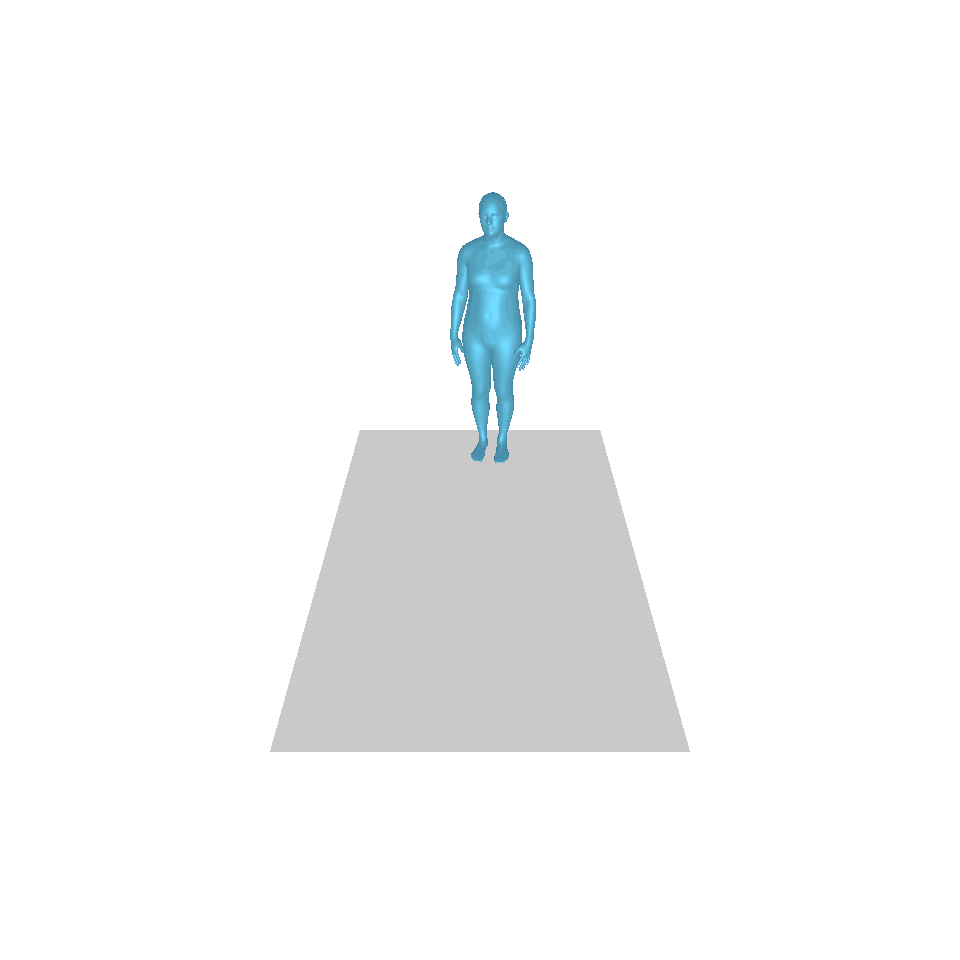 |
| Texte : Un homme se lève de terre, marche en cercle et se rassied sur le sol. | ||||
| GT | T2M | MDM | MouvementDiffuse | La nôtre |
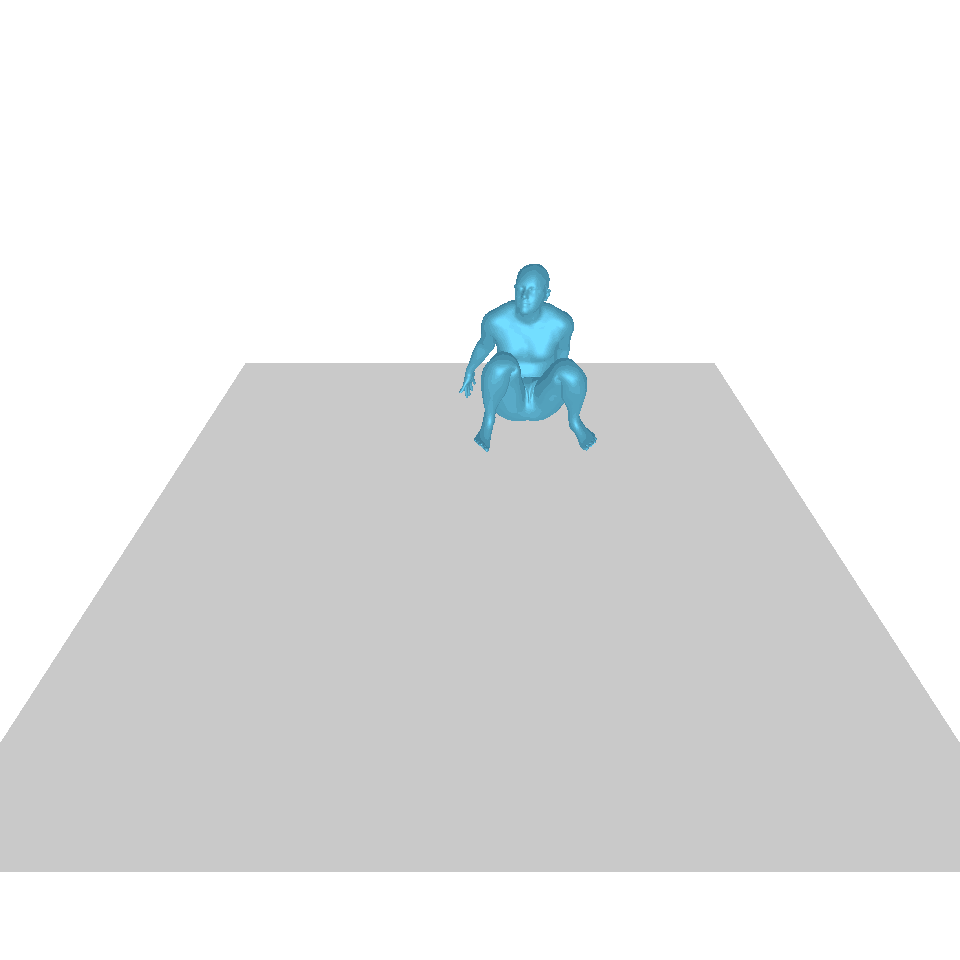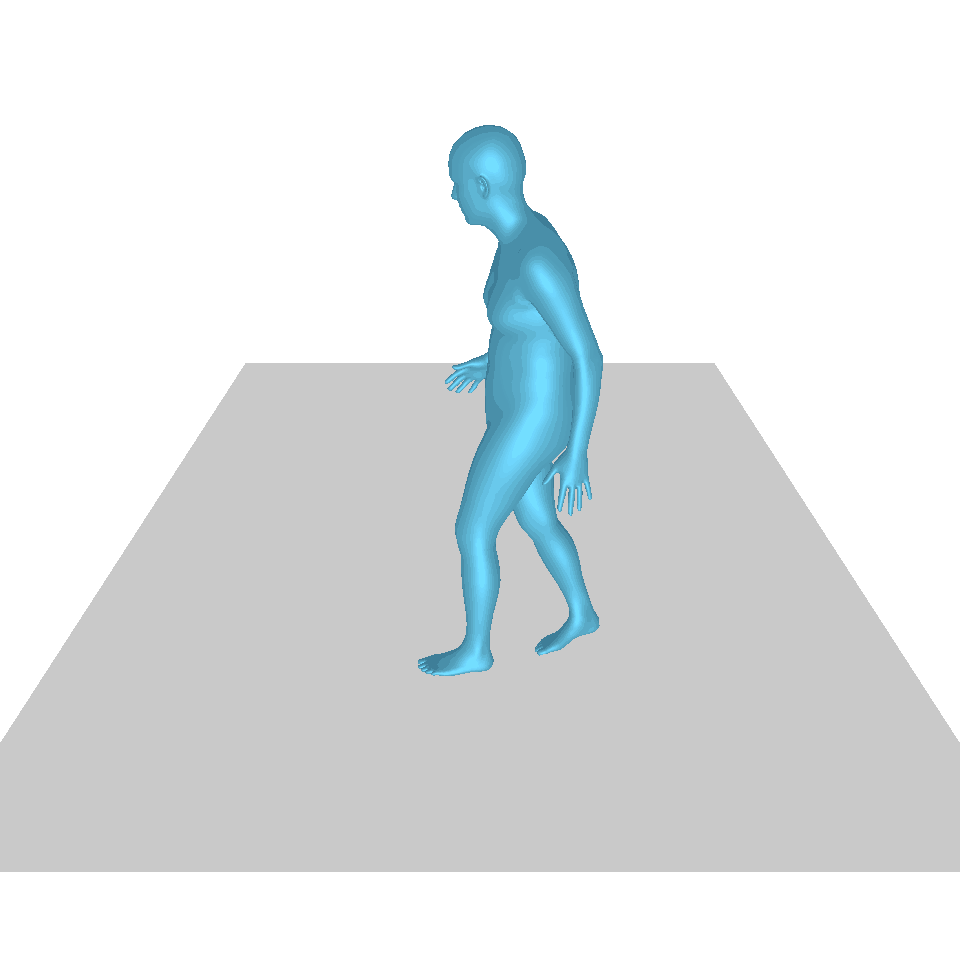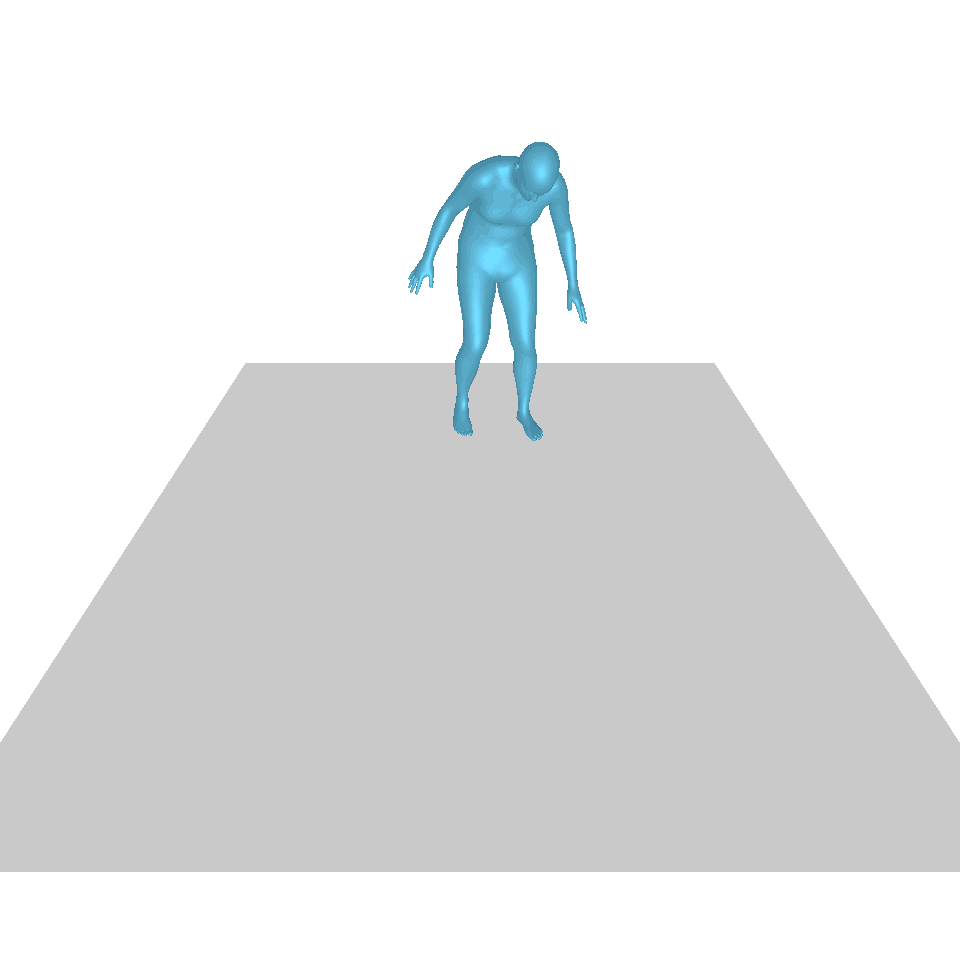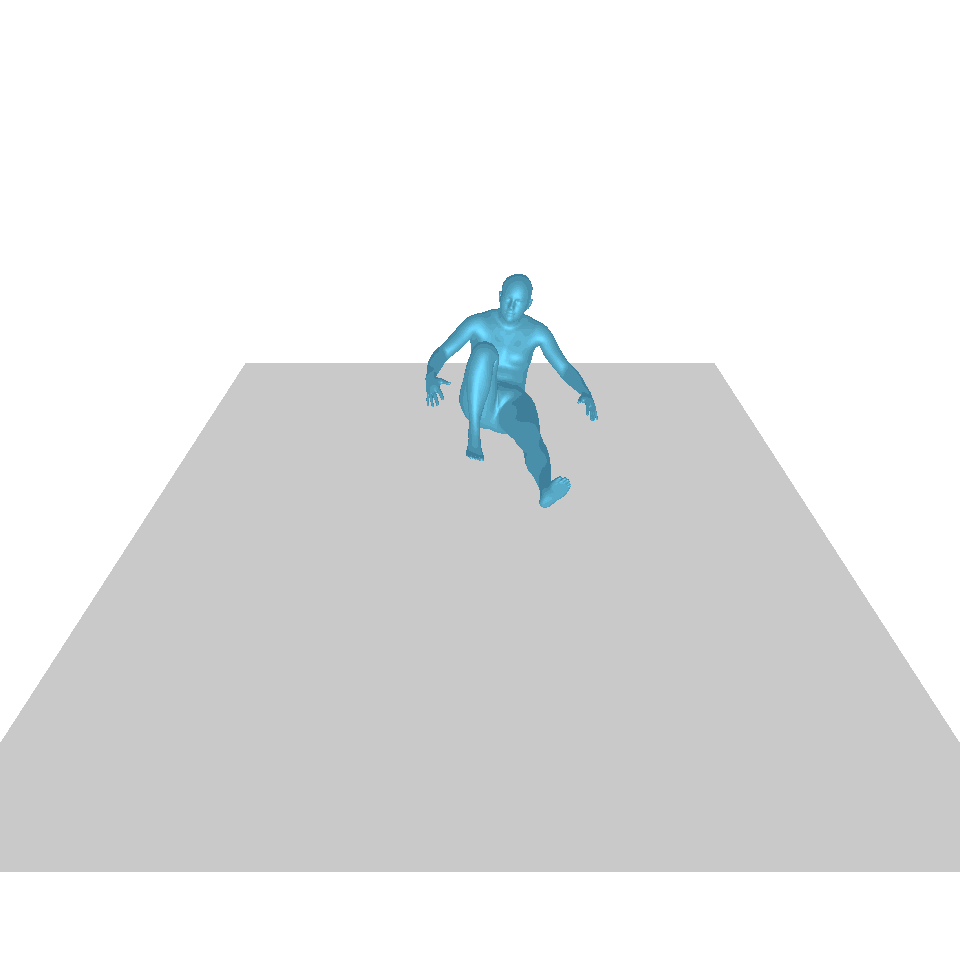 | 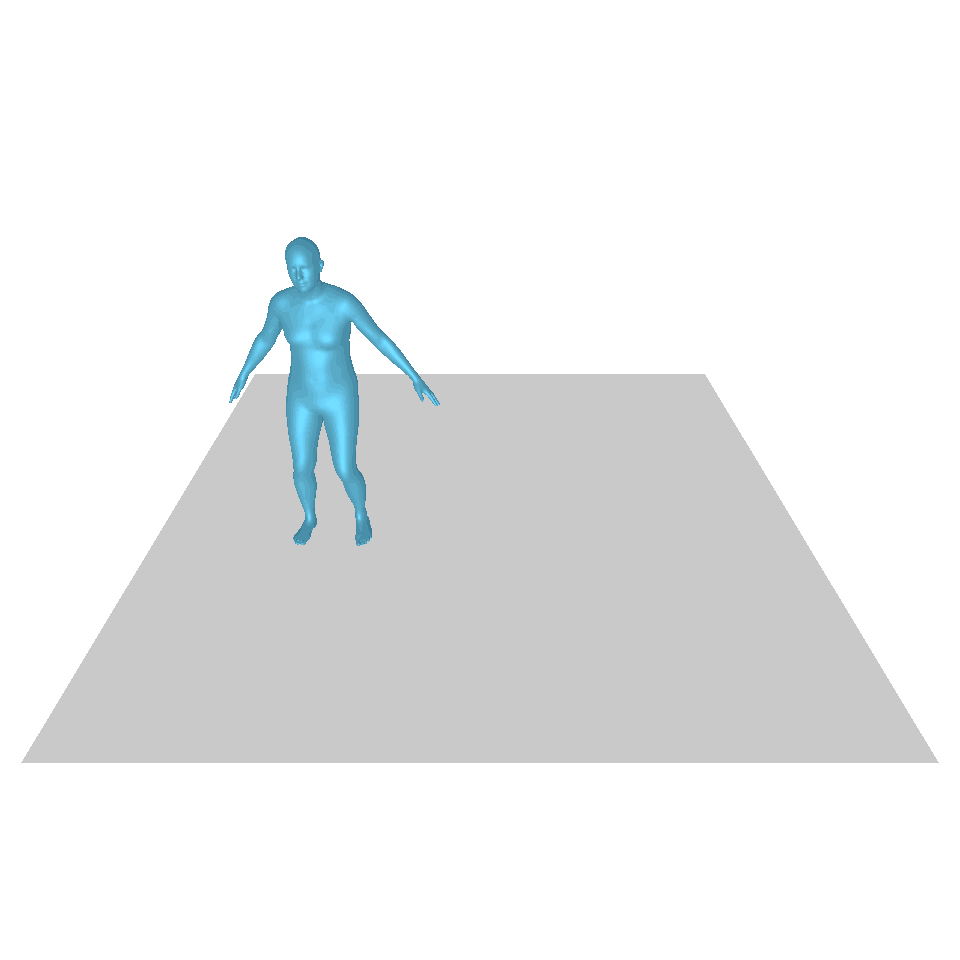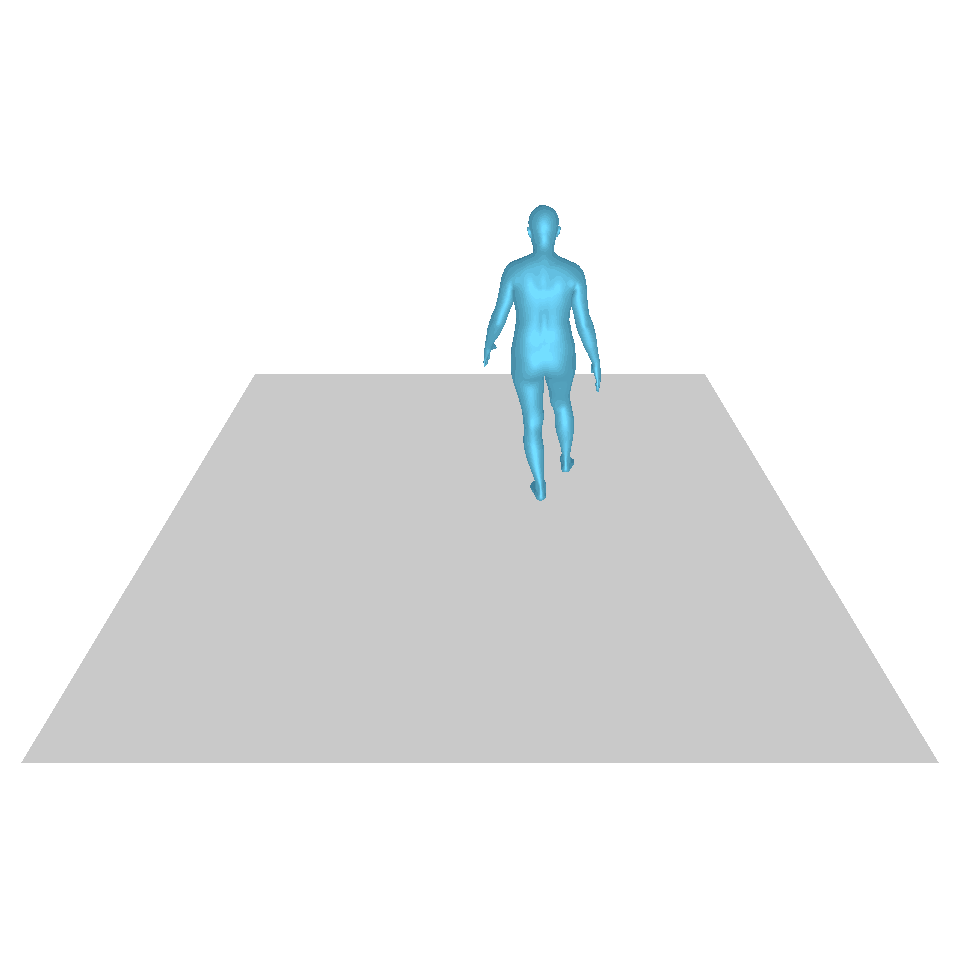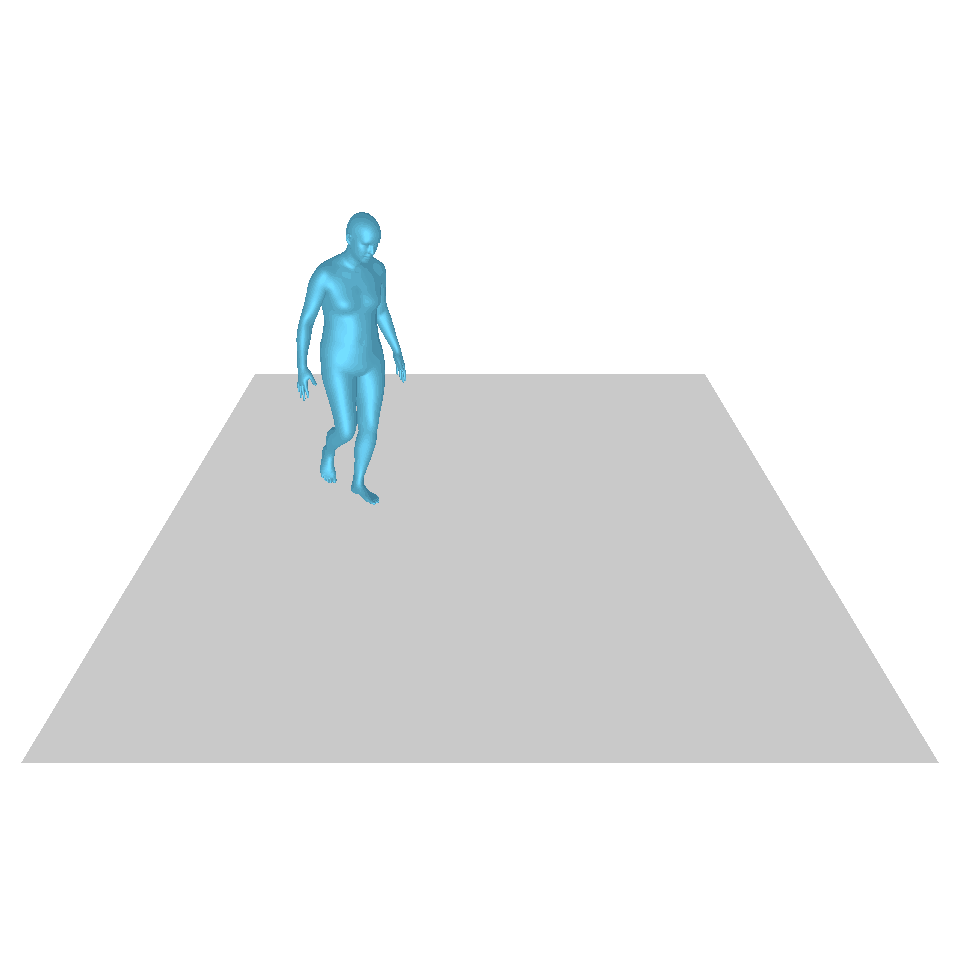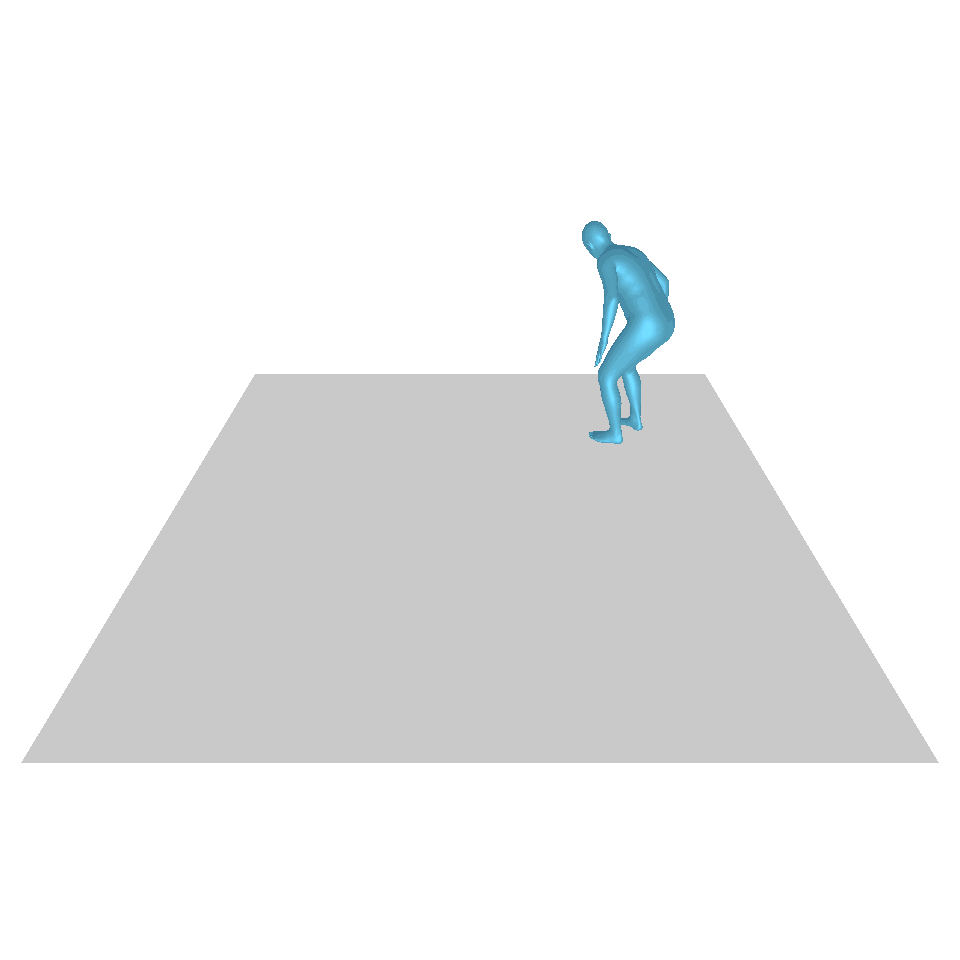 | 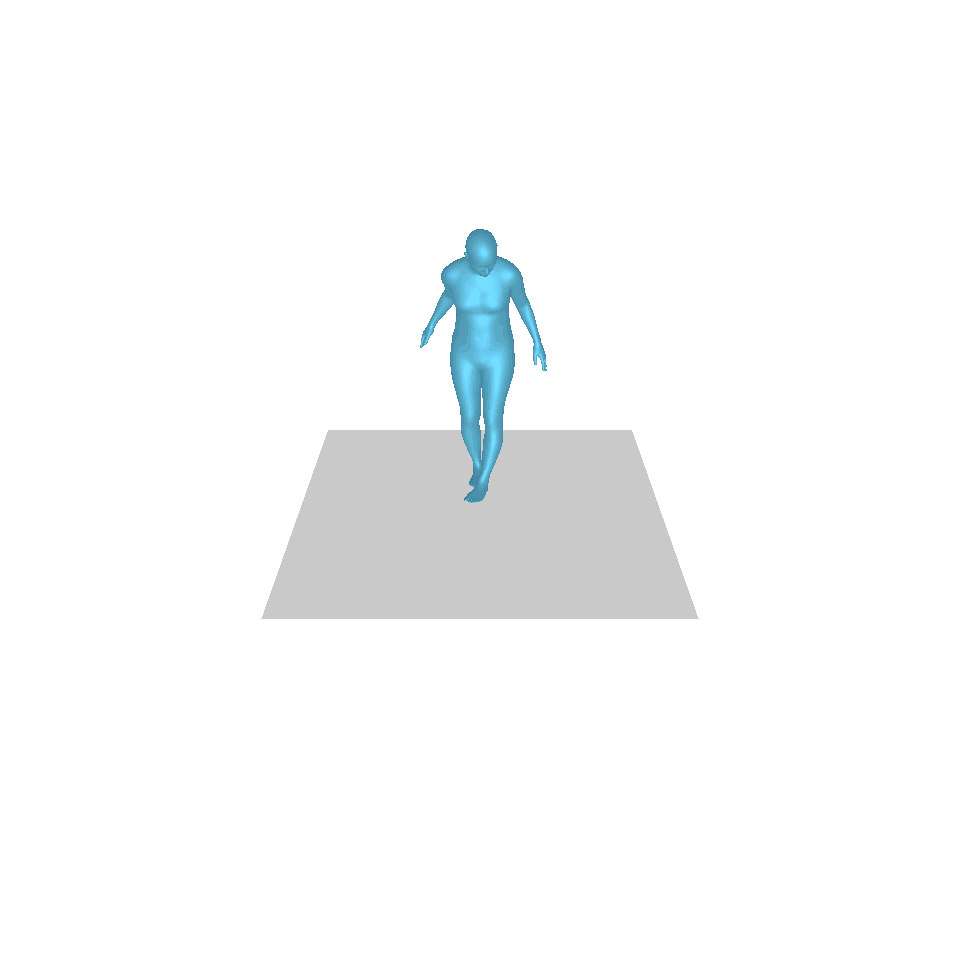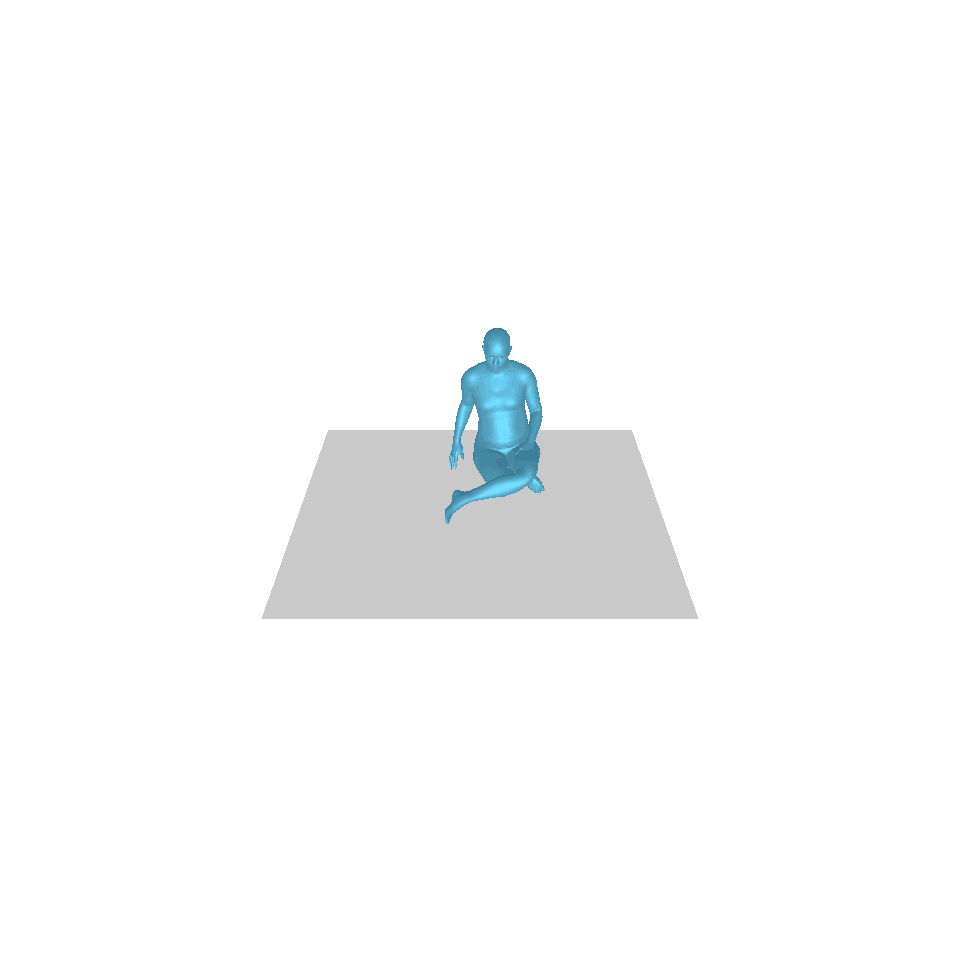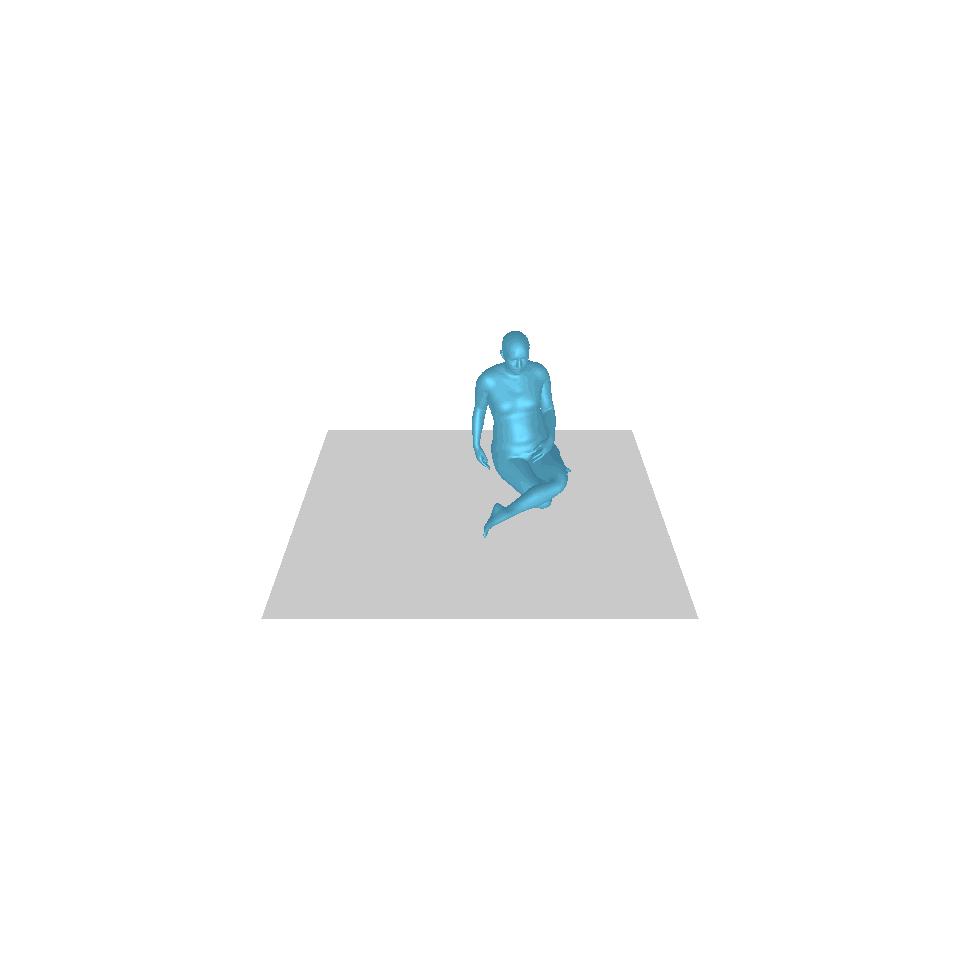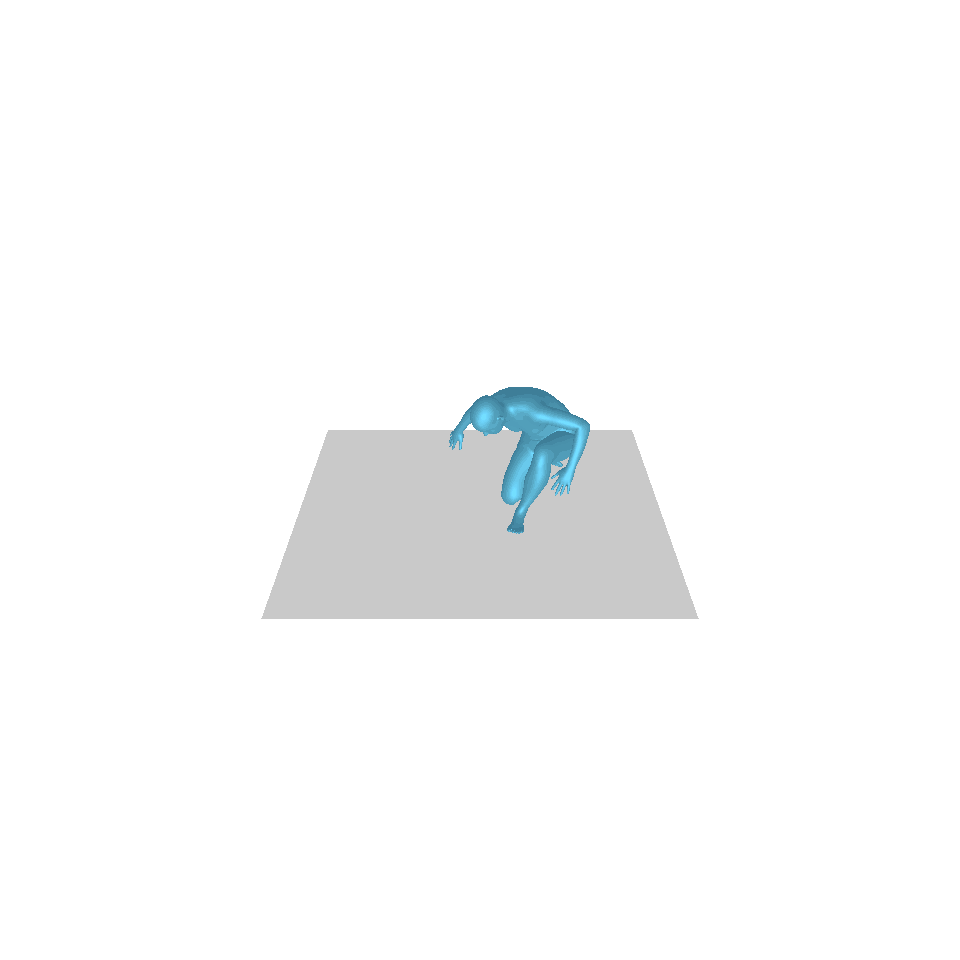 |  |  |
Notre modèle peut être appris dans un seul GPU V100-32G
conda env create -f environment.yml
conda activate T2M-GPTLe code a été testé sur Python 3.8 et PyTorch 1.8.1.
bash dataset/prepare/download_glove.shNous utilisons deux ensembles de données 3D sur le langage du mouvement humain : HumanML3D et KIT-ML. Pour les deux ensembles de données, vous pouvez trouver les détails ainsi qu'un lien de téléchargement [ici].
Prenons HumanML3D comme exemple, le répertoire de fichiers devrait ressembler à ceci :
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/
├── Mean.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── Std.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
Nous utilisons les mêmes extracteurs fournis par t2m pour évaluer nos mouvements générés. Veuillez télécharger les extracteurs.
bash dataset/prepare/download_extractor.shLes fichiers de modèle pré-entraînés seront stockés dans le dossier « pré-entraîné » :
bash dataset/prepare/download_model.shSi vous souhaitez restituer le mouvement généré, vous devez installer :
sudo sh dataset/prepare/download_smpl.sh
conda install -c menpo osmesa
conda install h5py
conda install -c conda-forge shapely pyrender trimesh mapbox_earcutUn guide de démarrage rapide sur la façon d'utiliser notre code est disponible dans demo.ipynb
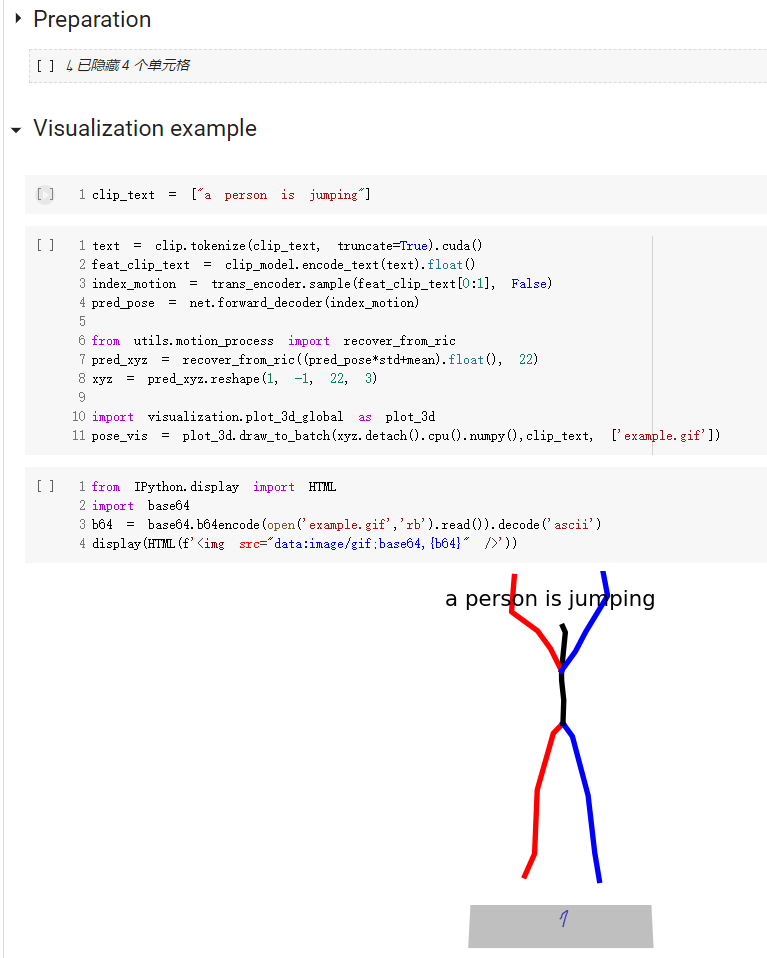
Notez que, pour l'ensemble de données de kit, il suffit de définir '--dataname kit'.
Les résultats sont enregistrés dans le dossier de sortie.
python3 train_vq.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name VQVAELes résultats sont enregistrés dans le dossier de sortie.
python3 train_t2m_trans.py
--exp-name GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relupython3 VQ_eval.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name TEST_VQVAE
--resume-pth output/VQVAE/net_last.pthSuivez le paramètre d'évaluation du texte en mouvement, nous évaluons notre modèle 20 fois et rapportons le résultat moyen. En raison de la partie multimodale où nous devons générer 30 motions à partir du même texte, l'évaluation prend beaucoup de temps.
python3 GPT_eval_multi.py
--exp-name TEST_GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relu
--resume-trans output/GPT/net_best_fid.pthVous devez saisir l'adresse du dossier npy et les noms de mouvement. Voici un exemple :
python3 render_final.py --filedir output/TEST_GPT/ --motion-list 000019 005485Nous apprécions l'aide de :


