tout-ai
Votre assistant chatbot local pleinement compétent, alimenté par l’IA ?
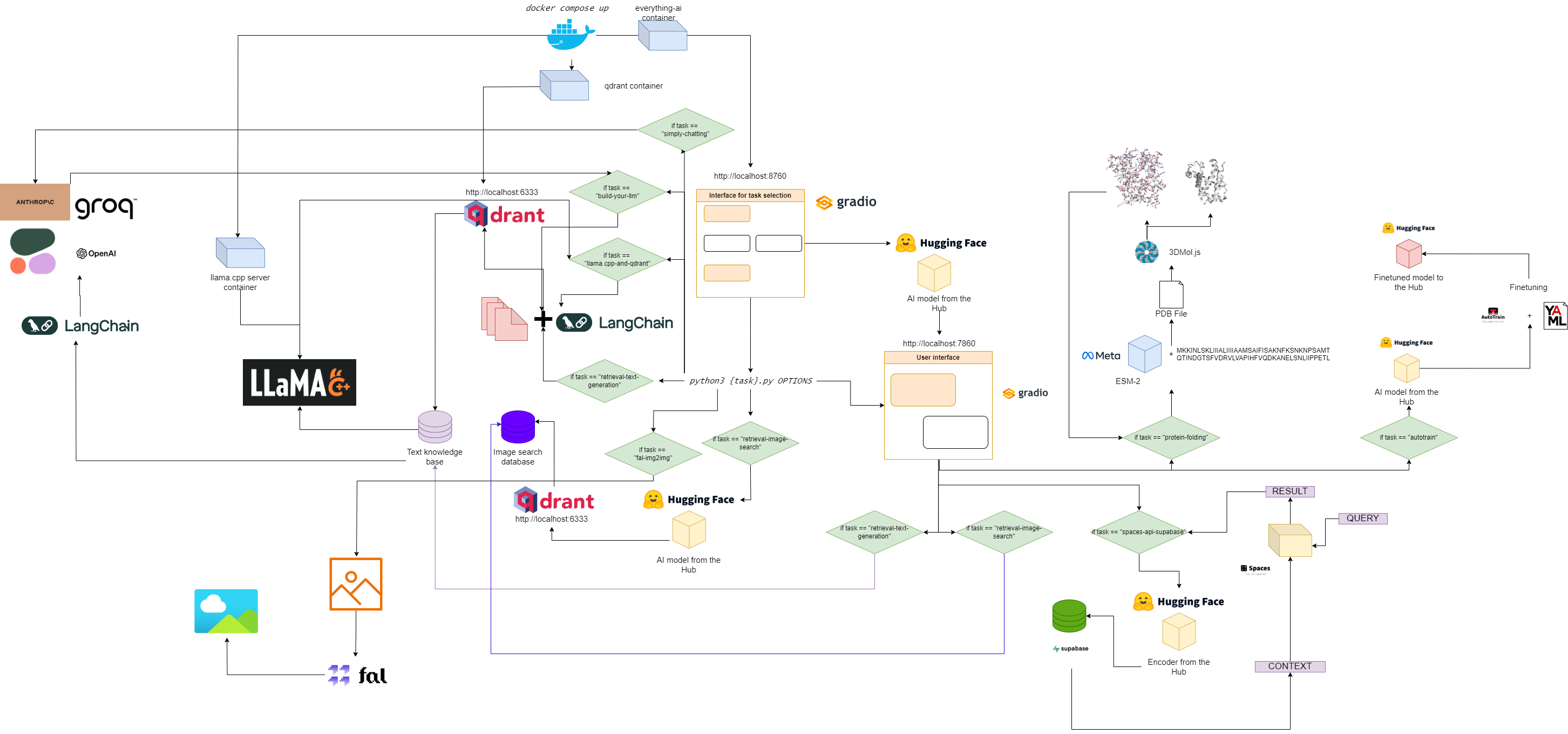
Organigramme pour tout-ai
Démarrage rapide
1. Clonez ce référentiel
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Définissez votre fichier .env
Modifier:
- Variable
VOLUME dans le fichier .env afin que vous puissiez monter votre système de fichiers local dans le conteneur Docker. -
MODELS_PATH dans le fichier .env afin que vous puissiez indiquer à llama.cpp où vous avez stocké les modèles GGUF que vous avez téléchargés. - Variable
MODEL dans le fichier .env afin que vous puissiez indiquer à llama.cpp quel modèle utiliser (utilisez le nom réel du fichier gguf et n'oubliez pas l'extension .gguf !) -
MAX_TOKENS dans le fichier .env afin que vous puissiez indiquer à llama.cpp combien de nouveaux jetons il peut générer en sortie.
Un exemple de fichier .env pourrait être :
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Cela signifie que maintenant tout ce qui se trouve sous "c:/Users/User/" sur votre ordinateur local se trouve sous "/User/" dans votre conteneur Docker, que llama.cpp sait où chercher les modèles et quel modèle rechercher, ainsi que le maximum de nouveaux jetons pour sa sortie.
3. Extrayez les images nécessaires
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Exécutez l'application multi-conteneurs
5. Allez sur localhost:8670 et choisissez votre assistant
Vous verrez quelque chose comme ceci :
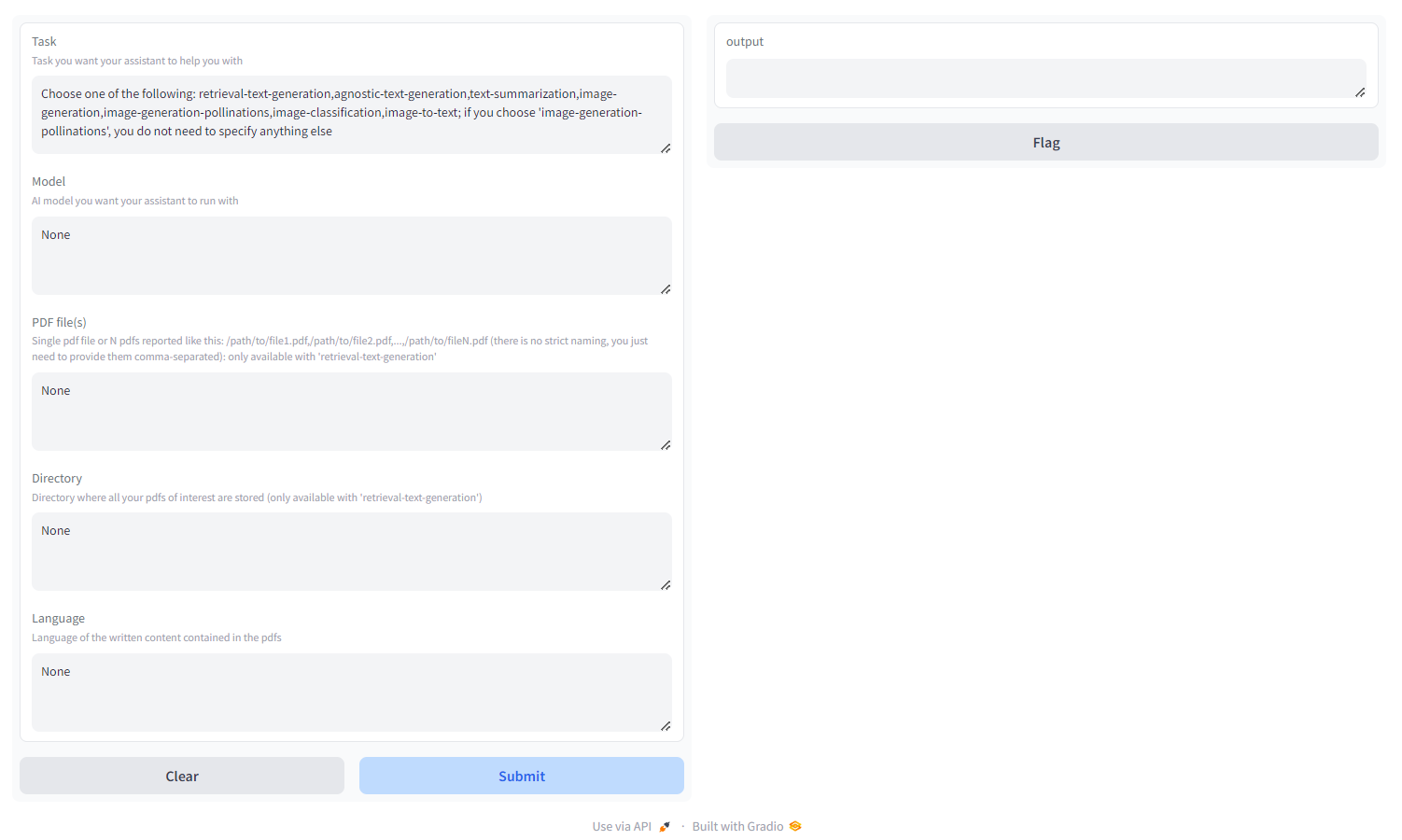
Choisissez la tâche parmi :
- retrieval-text-generation : utilisez le backend
qdrant pour créer une base de connaissances conviviale pour la récupération, sur laquelle vous pouvez interroger et ajuster la réponse de votre modèle. Vous devez transmettre soit un fichier PDF/un groupe de fichiers PDF spécifiés sous forme de chemins séparés par des virgules, soit un répertoire dans lequel tous les fichiers PDF qui vous intéressent sont stockés ( NE fournissez PAS les deux) ; vous pouvez également spécifier la langue dans laquelle le PDF est écrit, en utilisant la nomenclature ISO - MULTILINGUE - agnostic-text-Generation : génération de texte de type ChatGPT (pas d'architecture de récupération), mais prend en charge tous les modèles de génération de texte sur HF Hub (tant que votre matériel le prend en charge !) - MULTILINGUE
- text-sumarization : résume le texte et les fichiers PDF, prend en charge tous les modèles de résumé de texte sur HF Hub - ANGLAIS UNIQUEMENT
- génération d'images : diffusion stable, prend en charge tous les modèles texte-image sur HF Hub - MULTILINGUE
- image-genération-pollinisations : diffusion stable, utiliser l'API Pollinations AI ; si vous choisissez 'génération d'images-pollinisations', vous n'avez rien d'autre à préciser en dehors de la tâche - MULTILINGUE
- image-classification : classifie une image, prend en charge tous les modèles de classification d'images sur HF Hub - ANGLAIS UNIQUEMENT
- image-to-text : décrit une image, prend en charge tous les modèles image-to-text sur HF Hub - ANGLAIS UNIQUEMENT
- classification audio : classifie les fichiers audio ou les enregistrements de microphone, prend en charge les modèles de classification audio sur le hub HF
- reconnaissance vocale : transcrivez des fichiers audio ou des enregistrements de microphone, prend en charge les modèles de reconnaissance vocale automatique sur le hub HF.
- génération vidéo : génère une vidéo à l'invite du texte, prend en charge les modèles texte-vidéo sur le hub HF - ANGLAIS UNIQUEMENT
- repliement des protéines : obtenez la structure 3D d'une protéine à partir de sa séquence d'acides aminés, en utilisant le modèle de squelette ESM-2 - GPU UNIQUEMENT
- autotrain : affinez un modèle sur une tâche spécifique en aval avec autotrain-advanced, en spécifiant simplement votre nom d'utilisateur HF, votre jeton d'écriture HF et le chemin d'accès à un fichier de configuration yaml pour la formation
- space-api-supabase : utilisez l'API HF Spaces en combinaison avec les bases de données Supabase PostgreSQL afin de libérer des LLM plus puissants et des bases de données vectorielles plus volumineuses orientées RAG - MULTILINGUE
- llama.cpp-and-qdrant : identique à retrieval-text-generation , mais utilise llama.cpp comme moteur d'inférence, vous NE DEVEZ donc PAS spécifier de modèle - MULTILINGUE
- build-your-llm : Construisez un LLM de chat personnalisable combinant une base de données Qdrant avec vos PDF et la puissance des modèles Anthropic, OpenAI, Cohere ou Groq : vous avez juste besoin d'une clé API ! Pour créer la base de données Qdrant, vous devez transmettre soit un fichier PDF/un groupe de fichiers PDF spécifiés sous forme de chemins séparés par des virgules, soit un répertoire dans lequel tous les fichiers PDF qui vous intéressent sont stockés ( NE fournissez PAS les deux) ; vous pouvez également spécifier la langue dans laquelle le PDF est écrit, en utilisant la nomenclature ISO - MULTILINGUE , LANGFUSE INTEGRATION
- Simply-Chatting : Créez un LLM de chat personnalisable avec la puissance des modèles Anthropic, OpenAI, Cohere ou Groq (pas de pipeline RAG) : vous avez juste besoin d'une clé API ! - MULTILINGUE , INTÉGRATION LANGFUSE
- fal-img2img : Utilisez l'API fal.ai ComfyUI pour générer des images à partir de vos images PNG et JPEG : vous avez juste besoin d'une clé API ! Vous pouvez également personnaliser la génération en utilisant des invites et des graines - ANGLAIS UNIQUEMENT
- image-retrieval-search : recherche dans une base de données d'images en téléchargeant un dossier comme entrée de base de données. Le dossier doit avoir la structure suivante :
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Vous pouvez interroger la base de données à partir de vos propres images.
6. Accédez à localhost:7860 et commencez à utiliser votre assistant
Une fois que tout est prêt, vous pouvez vous rendre sur localhost:7860 et commencer à utiliser votre assistant :