serverless rag ynetnews bedrock demo
1.0.0
La réponse aux questions (AQ) est une tâche importante qui consiste à extraire des réponses à des requêtes factuelles posées en langage naturel. En règle générale, un système d'assurance qualité traite une requête sur une base de connaissances contenant des données structurées ou non structurées et génère une réponse avec des informations précises. Garantir une grande précision est essentiel pour développer un système de réponse aux questions utile, fiable et digne de confiance, en particulier pour les cas d’utilisation en entreprise.
Les modèles d'IA générative comme Amazon Titan, Anthropic Claude et AI21 Jurassic 2 utilisent des distributions de probabilité pour générer des réponses aux questions. Ces modèles sont formés sur de grandes quantités de données textuelles, ce qui leur permet de prédire ce qui va suivre dans une séquence ou quel mot pourrait suivre un mot particulier. Cependant, ces modèles ne sont pas en mesure de fournir des réponses précises ou déterministes à chaque question car il existe toujours un certain degré d’incertitude dans les données.
Les entreprises doivent interroger des données propriétaires et spécifiques à un domaine et utiliser ces informations pour répondre à des questions, et plus généralement des données sur lesquelles le modèle n'a pas été formé.
Dans ce référentiel, nous explorerons le modèle d'assurance qualité suivant :
Nous utilisons la génération augmentée de récupération qui améliore la première où nous concaténons nos questions avec autant de contexte pertinent que possible, susceptible de contenir les réponses ou les informations que nous recherchons. Le défi ici, il existe une limite à la quantité d'informations contextuelles pouvant être utilisées est déterminée par la limite de jetons du modèle. 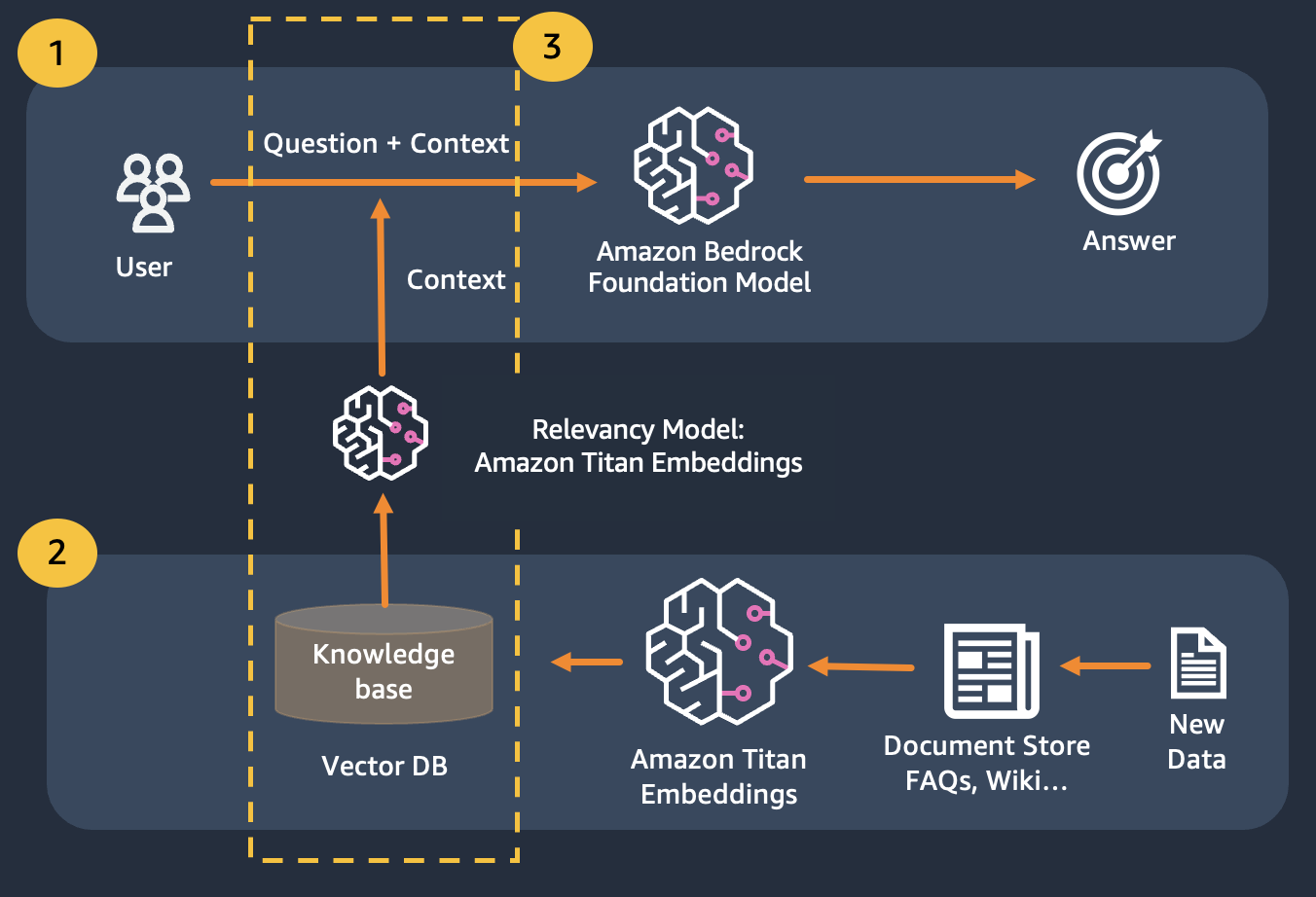
Ceci peut être surmonté en utilisant Retrival Augmented Generation (RAG)
RAG combine l'utilisation d'intégrations pour indexer le corpus des documents afin de construire une base de connaissances et l'utilisation d'un LLM pour extraire les informations d'un sous-ensemble de documents dans la base de connaissances.
En guise d'étape de préparation pour RAG, les documents constituant la base de connaissances sont divisés en morceaux d'une taille fixe (correspondant à la taille d'entrée maximale du modèle d'intégration sélectionné), puis transmis au modèle pour obtenir le vecteur d'intégration. L'intégration ainsi que le morceau d'origine du document et les métadonnées supplémentaires sont stockés dans une base de données vectorielle. La base de données vectorielles est optimisée pour effectuer efficacement une recherche de similarité entre les vecteurs.
Clients disposant de magasins de données qui peuvent être privés ou changer fréquemment. L'approche RAG résout 2 problèmes, les clients rencontrant les défis suivants peuvent bénéficier de ce laboratoire.
Après ce module, vous devriez avoir une bonne compréhension de :
Dans ce module, nous vous expliquerons comment implémenter le modèle d'assurance qualité avec Bedrock. De plus, nous avons préparé pour vous les intégrations à charger dans la base de données vectorielles.
Notez que vous pouvez utiliser Titan Embeddings pour obtenir les intégrations de la question de l'utilisateur, puis utiliser ces intégrations pour récupérer les documents les plus pertinents de la base de données vectorielle, créer une invite concaténant les 3 principaux documents et invoquer le modèle LLM via Bedrock.


