LLM Alignment Project
1.0.0
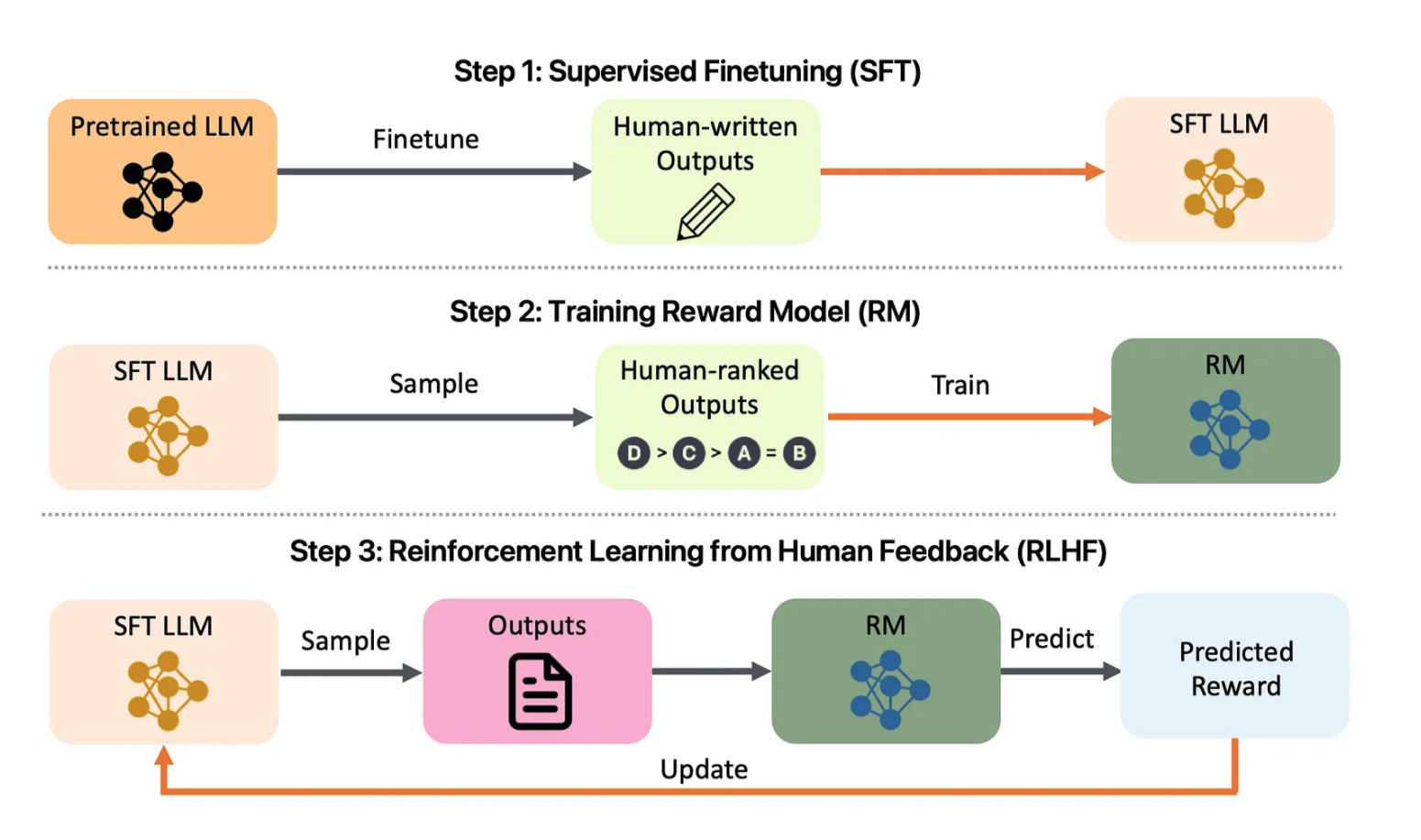
Figure 1 : Aperçu du projet d'alignement LLM. Jetez un œil à : arXiv:2308.05374
Le modèle d'alignement LLM n'est pas seulement un outil complet pour aligner de grands modèles de langage (LLM), mais sert également de modèle puissant pour créer votre propre application d'alignement LLM. Inspiré par des modèles de projet tels que PyTorch Project Template , ce référentiel est conçu pour fournir une pile complète de fonctionnalités, agissant comme un point de départ pour personnaliser et étendre vos propres besoins d'alignement LLM. Que vous soyez chercheur, développeur ou data scientist, ce modèle fournit une base solide pour créer et déployer efficacement des LLM adaptés aux valeurs et aux objectifs humains.
Le modèle d'alignement LLM fournit une pile complète de fonctionnalités, notamment la formation, le réglage fin, le déploiement et la surveillance des LLM à l'aide de l'apprentissage par renforcement à partir de la rétroaction humaine (RLHF). Ce projet intègre également des mesures d'évaluation pour garantir une utilisation éthique et efficace des modèles de langage. L'interface offre une expérience conviviale pour gérer l'alignement, visualiser les mesures de formation et déployer à grande échelle.
app/ : contient le code de l'API et de l'interface utilisateur.
auth.py , feedback.py , ui.py : points de terminaison d'API pour l'interaction utilisateur, la collecte de commentaires et la gestion générale de l'interface.app.js , chart.js ), CSS ( styles.css ) et documentation de l'API Swagger ( swagger.json ).chat.html , feedback.html , index.html ) pour le rendu de l'interface utilisateur. src/ : Logique de base et utilitaires pour le prétraitement et la formation.
preprocessing/ ):preprocess_data.py : combine des ensembles de données originaux et augmentés et applique le nettoyage du texte.tokenization.py : gère la tokenisation.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : Scripts pour la formation et le recyclage des modèles.rlhf.py , reward_model.py : Scripts pour la formation de modèles de récompense à l'aide de RLHF.utils/ ) : utilitaires courants ( config.py , logging.py , validation.py ). dashboards/ : tableaux de bord de performances et d'explicabilité pour la surveillance et les informations sur les modèles.
performance_dashboard.py : affiche les métriques d'entraînement, la perte de validation et la précision.explainability_dashboard.py : visualise les valeurs SHAP pour fournir un aperçu des décisions du modèle. tests/ : Tests unitaires, d'intégration et de bout en bout.
test_api.py , test_preprocessing.py , test_training.py : Divers tests unitaires et d'intégration.e2e/ ) : tests d'interface utilisateur basés sur Cypress ( ui_tests.spec.js ).load_testing/ ) : utilise Locust ( locustfile.py ) pour les tests de charge. deployment/ : fichiers de configuration pour le déploiement et la surveillance.
kubernetes/ ) : configurations de déploiement et d'entrée pour la mise à l'échelle et les versions Canary.monitoring/ ) : Prometheus ( prometheus.yml ) et Grafana ( grafana_dashboard.json ) pour la surveillance des performances et de l'état du système. Cloner le référentiel :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-TemplateDépendances d'installation :
pip install -r requirements.txt cd app/static
npm installCréer des images Docker :
docker-compose up --buildAccédez à l'application :
http://localhost:5000 . kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml pour déployer de nouvelles versions en toute sécurité.deployment/monitoring/ pour activer les tableaux de bord de surveillance.docker-compose.logging.yml pour les journaux centralisés. Le module de formation ( src/training/transfer_learning.py ) utilise des modèles pré-entraînés comme BERT pour s'adapter aux tâches personnalisées, offrant ainsi une amélioration significative des performances.
Le script data_augmentation.py ( src/data/ ) applique des techniques d'augmentation telles que la rétro-traduction et la paraphrase pour améliorer la qualité des données.
rlhf.py et reward_model.py pour affiner les modèles en fonction des commentaires humains.feedback.html ) et le modèle se recycle avec retrain_model.py . Le script explainability_dashboard.py utilise les valeurs SHAP pour aider les utilisateurs à comprendre pourquoi un modèle a effectué des prédictions spécifiques.
tests/ , couvrant les fonctionnalités d'API, de prétraitement et de formation.tests/load_testing/locustfile.py ) pour garantir la stabilité sous charge. Les contributions sont les bienvenues ! Veuillez soumettre des demandes d'extraction ou des problèmes pour des améliorations ou de nouvelles fonctionnalités.
Ce projet est sous licence MIT. Voir le fichier LICENSE pour plus d'informations.
Développé avec ❤️ par Amirsina Torfi


