BinaryVectorDB
1.0.0
Ce référentiel contient une base de données de vecteurs binaires pour une recherche efficace sur de grands ensembles de données, destinée à des fins éducatives.
La plupart des modèles d'intégration représentent leurs vecteurs sous la forme float32 : ceux-ci consomment beaucoup de mémoire et la recherche sur ceux-ci est très lente. Chez Cohere, nous avons introduit le premier modèle d'intégration avec prise en charge native de int8 et binaire, qui vous offre une excellente qualité de recherche pour une fraction du coût :
| Modèle | Rechercher la qualité MIRACL | Il est temps de rechercher 1 million de documents | Mémoire nécessaire 250 millions d'intégrations Wikipédia | Prix sur AWS (instance x2 Go) |
|---|---|---|---|---|
| Intégration de texte OpenAI-3-small | 44,9 | 680 ms | 1431 Go | 65 231 $ / an |
| Intégration de texte OpenAI-3-large | 54,9 | 1240 ms | 2861 Go | 130 463 $/an |
| Cohere Embed v3 (multilingue) | ||||
| Intégrer la v3 - float32 | 66,3 | 460 ms | 954 Go | 43 488 $ / an |
| Intégrer v3 - binaire | 62,8 | 24 ms | 30 Go | 1 359 $ / an |
| Intégrer v3 - binaire + rescore int8 | 66,3 | 28 ms | 30 Go de mémoire + 240 Go de disque | 1 589 $ / an |
Nous avons créé une démo qui vous permet de rechercher sur 100 millions d'intégrations Wikipédia une VM qui ne coûte que 15 $/mois : Démo - Recherchez sur 100 millions d'intégrations Wikipédia pour seulement 15 $/mois.
Vous pouvez facilement utiliser BinaryVectorDB sur vos propres données.
La configuration est simple :
pip install BinaryVectorDB
Pour utiliser certains des exemples ci-dessous, vous avez besoin d'une clé API Cohere (gratuite ou payante) de cohere.com. Vous devez définir cette clé API comme variable d'environnement : export COHERE_API_KEY=your_api_key
Nous montrerons plus tard comment construire une base de données vectorielle sur vos propres données. Pour commencer, utilisons une base de données vectorielles binaires pré-construite . Nous hébergeons diverses bases de données pré-construites sur https://huggingface.co/datasets/Cohere/BinaryVectorDB. Vous pouvez les télécharger et les utiliser localement.
Laissez-nous la version anglaise simple de Wikipédia pour commencer :
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
Et puis décompressez ce fichier :
unzip wikipedia-2023-11-simple.zip
Vous pouvez facilement charger la base de données en la pointant vers le dossier décompressé de l'étape précédente :
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )La base de données compte 646 424 intégrations et une taille totale de 962 Mo. Cependant, seuls 80 Mo pour les intégrations binaires sont chargés en mémoire. Les documents et leurs intégrations int8 sont conservés sur le disque et sont simplement chargés en cas de besoin.
Cette répartition des intégrations binaires en mémoire et des intégrations et documents int8 sur disque nous permet d'évoluer vers de très grands ensembles de données sans avoir besoin de tonnes de mémoire.
Il est assez simple de créer votre propre base de données de vecteurs binaires.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) Le document peut être n’importe quel objet sérialisable Python. Vous devez fournir une fonction pour docs2text qui mappe votre document à une chaîne. Dans l'exemple ci-dessus, nous concaténons le titre et le champ de texte. Cette chaîne est envoyée au modèle d'intégration pour produire les intégrations de texte nécessaires.
Ajouter/supprimer/mettre à jour des documents est simple. Voir examples/add_update_delete.py pour un exemple de script comment ajouter/mettre à jour/supprimer des documents dans la base de données.
Nous avons annoncé nos intégrations Cohere int8 et binaire Embeddings, qui offrent une réduction de 4x et 32x de la mémoire nécessaire. De plus, il permet d'accélérer jusqu'à 40 fois la recherche vectorielle.
Les deux techniques sont combinées dans BinaryVectorDB. À titre d'exemple, supposons que Wikipédia en anglais comporte 42 millions d'intégrations. Les intégrations float32 normales auraient besoin 42*10^6*1024*4 = 160 GB de mémoire pour simplement héberger les intégrations. Comme la recherche sur float32 est plutôt lente (environ 45 secondes sur 42 Mo d'intégrations), nous devons ajouter un index comme HNSW, qui ajoute 20 Go de mémoire supplémentaires, vous avez donc besoin d'un total de 180 Go.
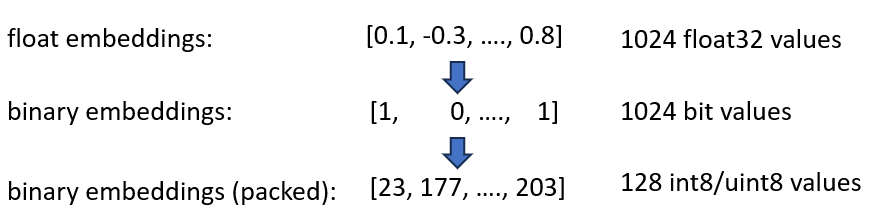
Les intégrations binaires représentent chaque dimension sous forme de 1 bit. Cela réduit le besoin en mémoire à 160 GB / 32 = 5GB . De plus, comme la recherche dans l’espace binaire est 40 fois plus rapide, vous n’avez plus besoin de l’index HNSW dans de nombreux cas. Vous avez réduit vos besoins en mémoire de 180 Go à 5 Go, soit une belle économie de 36x.
Lorsque nous interrogeons cet index, nous codons également la requête en binaire et utilisons la distance de Hamming. La distance de Hamming mesure les différences de 1 bit entre 2 vecteurs. Il s'agit d'une opération extrêmement rapide : pour comparer deux vecteurs binaires, vous n'avez besoin que de 2 cycles CPU : popcount(xor(vector1, vector2)) . XOR est l’opération la plus fondamentale sur les processeurs, elle s’exécute donc extrêmement rapidement. popcount compte le nombre 1 dans le registre, qui n'a également besoin que d'un cycle CPU.
Globalement, cela nous donne une solution qui conserve environ 90 % de la qualité de la recherche.
Nous pouvons augmenter la qualité de la recherche par rapport à l'étape précédente de 90 % à 95 % en effectuant une nouvelle notation <float, binary> .
Nous prenons par exemple les 100 meilleurs résultats de l'étape 1 et calculons dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Supposons que notre intégration de requêtes soit [0.1, -0.3, 0.4] et que notre intégration de documents binaires soit [1, 0, 1] . Cette étape calcule alors :
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Nous utilisons ces scores et réévaluons nos résultats. Cela fait passer la qualité de la recherche de 90 % à 95 %. Cette opération peut être effectuée extrêmement rapidement : nous obtenons l'intégration flottante de la requête à partir du modèle d'intégration, les intégrations binaires sont en mémoire, nous avons donc juste besoin de faire 100 opérations de somme.
Pour améliorer encore la qualité de la recherche, de 95 % à 99,99 %, nous utilisons la réévaluation int8 à partir du disque.
Nous enregistrons toutes les intégrations de documents int8 sur le disque. Nous prenons ensuite le top 30 de l'étape ci-dessus, chargeons les intégrations int8 à partir du disque et calculons cossim(query_float_embedding, int8_doc_embedding_from_disk)
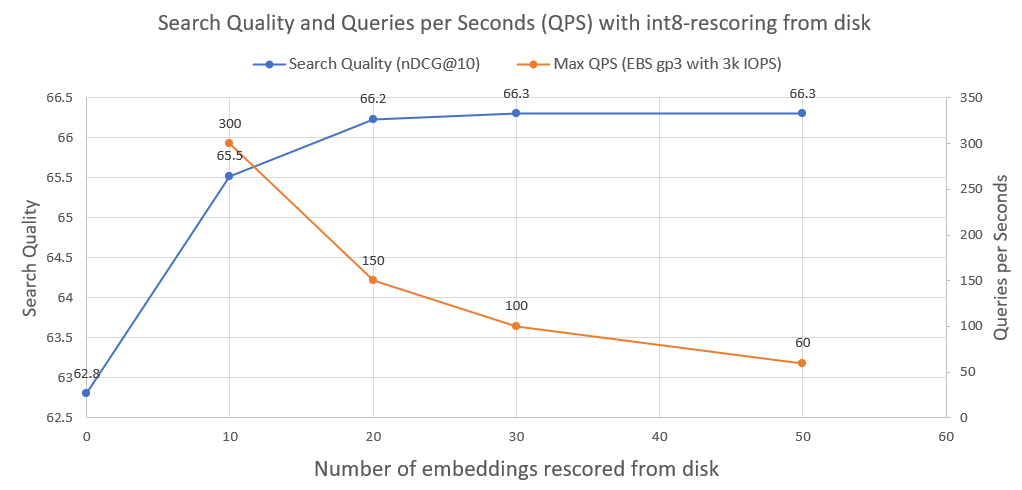
Dans l'image suivante, vous pouvez voir le degré de notation int8 et améliorer les performances de recherche :
Nous avons également tracé les requêtes par seconde qu'un tel système peut réaliser lorsqu'il est exécuté sur un lecteur réseau AWS EBS normal avec 3 000 IOPS. Comme nous le voyons, plus nous devons charger d'intégrations int8 à partir du disque, moins il y a de QPS.
Pour effectuer la recherche binaire, nous utilisons l'index IndexBinaryFlat de faiss. Il stocke simplement les intégrations binaires, permet une indexation ultra rapide et une recherche ultra rapide.
Pour stocker les documents et les intégrations int8, nous utilisons RocksDict, un stockage clé-valeur sur disque pour Python basé sur RocksDB.
Voir BinaryVectorDB pour l'implémentation complète de la classe.
Pas vraiment. Le référentiel est principalement destiné à des fins éducatives pour montrer les techniques permettant d'évoluer vers de grands ensembles de données. L'accent a été davantage mis sur la facilité d'utilisation et certains aspects critiques manquent dans la mise en œuvre, comme la sécurité multi-processus, les restaurations, etc.
Si vous souhaitez réellement vous lancer en production, utilisez une base de données vectorielles appropriée comme Vespa.ai, qui vous permet d'obtenir des résultats similaires.
Chez Cohere, nous avons aidé nos clients à exécuter la recherche sémantique sur des dizaines de milliards d'intégrations, pour une fraction du coût. N'hésitez pas à contacter Nils Reimers si vous avez besoin d'une solution évolutive.


