katana
v1.1.1

Fonctionnalités • Installation • Utilisation • Portée • Configuration • Filtres • Rejoindre Discord
katana nécessite Go 1.18 pour s'installer avec succès. Pour installer, exécutez simplement la commande ci-dessous ou téléchargez le binaire précompilé à partir de la page de version.
CGO_ENABLED=1 go install github.com/projectdiscovery/katana/cmd/katana@latestPlus d'options pour installer/exécuter katana-
Pour installer/mettre à jour Docker avec la dernière balise -
docker pull projectdiscovery/katana:latestPour exécuter Katana en mode standard à l'aide de Docker -
docker run projectdiscovery/katana:latest -u https://tesla.comPour exécuter Katana en mode sans tête à l'aide de Docker -
docker run projectdiscovery/katana:latest -u https://tesla.com -system-chrome -headlessIl est recommandé d'installer les prérequis suivants :
sudo apt update
sudo snap refresh
sudo apt install zip curl wget git
sudo snap install golang --classic
wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
sudo sh -c ' echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list '
sudo apt update
sudo apt install google-chrome-stableinstaller Katana -
go install github.com/projectdiscovery/katana/cmd/katana@latest katana -hCela affichera l’aide de l’outil. Voici tous les commutateurs qu’il prend en charge.
Katana is a fast crawler focused on execution in automation
pipelines offering both headless and non-headless crawling.
Usage:
./katana [flags]
Flags:
INPUT:
-u, -list string[] target url / list to crawl
-resume string resume scan using resume.cfg
-e, -exclude string[] exclude host matching specified filter ('cdn', 'private-ips', cidr, ip, regex)
CONFIGURATION:
-r, -resolvers string[] list of custom resolver (file or comma separated)
-d, -depth int maximum depth to crawl (default 3)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-jsl, -jsluice enable jsluice parsing in javascript file (memory intensive)
-ct, -crawl-duration value maximum duration to crawl the target for (s, m, h, d) (default s)
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml), a minimum depth of 3 is required to ensure all known files are properly crawled.
-mrs, -max-response-size int maximum response size to read (default 9223372036854775807)
-timeout int time to wait for request in seconds (default 10)
-aff, -automatic-form-fill enable automatic form filling (experimental)
-fx, -form-extraction extract form, input, textarea & select elements in jsonl output
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom header/cookie to include in all http request in header:value format (file)
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file
-flc, -field-config string path to custom field configuration file
-s, -strategy string Visit strategy (depth-first, breadth-first) (default "depth-first")
-iqp, -ignore-query-params Ignore crawling same path with different query-param values
-tlsi, -tls-impersonate enable experimental client hello (ja3) tls randomization
-dr, -disable-redirects disable following redirects (default false)
DEBUG:
-health-check, -hc run diagnostic check up
-elog, -error-log string file to write sent requests error log
HEADLESS:
-hl, -headless enable headless hybrid crawling (experimental)
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless mode
-ho, -headless-options string[] start headless chrome with additional options
-nos, -no-sandbox start headless chrome in --no-sandbox mode
-cdd, -chrome-data-dir string path to store chrome browser data
-scp, -system-chrome-path string use specified chrome browser for headless crawling
-noi, -no-incognito start headless chrome without incognito mode
-cwu, -chrome-ws-url string use chrome browser instance launched elsewhere with the debugger listening at this URL
-xhr, -xhr-extraction extract xhr request url,method in jsonl output
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) or custom regex (e.g., '(company-staging.io|company.com)') (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawling
FILTER:
-mr, -match-regex string[] regex or list of regex to match on output url (cli, file)
-fr, -filter-regex string[] regex or list of regex to filter on output url (cli, file)
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,ufile,key,value,kv,dir,udir)
-sf, -store-field string field to store in per-host output (url,path,fqdn,rdn,rurl,qurl,qpath,file,ufile,key,value,kv,dir,udir)
-em, -extension-match string[] match output for given extension (eg, -em php,html,js)
-ef, -extension-filter string[] filter output for given extension (eg, -ef png,css)
-mdc, -match-condition string match response with dsl based condition
-fdc, -filter-condition string filter response with dsl based condition
RATE-LIMIT:
-c, -concurrency int number of concurrent fetchers to use (default 10)
-p, -parallelism int number of concurrent inputs to process (default 10)
-rd, -delay int request delay between each request in seconds
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minute
UPDATE:
-up, -update update katana to latest version
-duc, -disable-update-check disable automatic katana update check
OUTPUT:
-o, -output string file to write output to
-sr, -store-response store http requests/responses
-srd, -store-response-dir string store http requests/responses to custom directory
-sfd, -store-field-dir string store per-host field to custom directory
-or, -omit-raw omit raw requests/responses from jsonl output
-ob, -omit-body omit response body from jsonl output
-j, -jsonl write output in jsonl format
-nc, -no-color disable output content coloring (ANSI escape codes)
-silent display output only
-v, -verbose display verbose output
-debug display debug output
-version display project version katana nécessite l'analyse d'une URL ou d'un point de terminaison et accepte une ou plusieurs entrées.
L'URL d'entrée peut être fournie à l'aide de l'option -u , et plusieurs valeurs peuvent être fournies à l'aide d'une entrée séparée par des virgules. De même, l'entrée de fichier est prise en charge à l'aide de l'option -list et l'entrée canalisée (stdin) est également prise en charge.
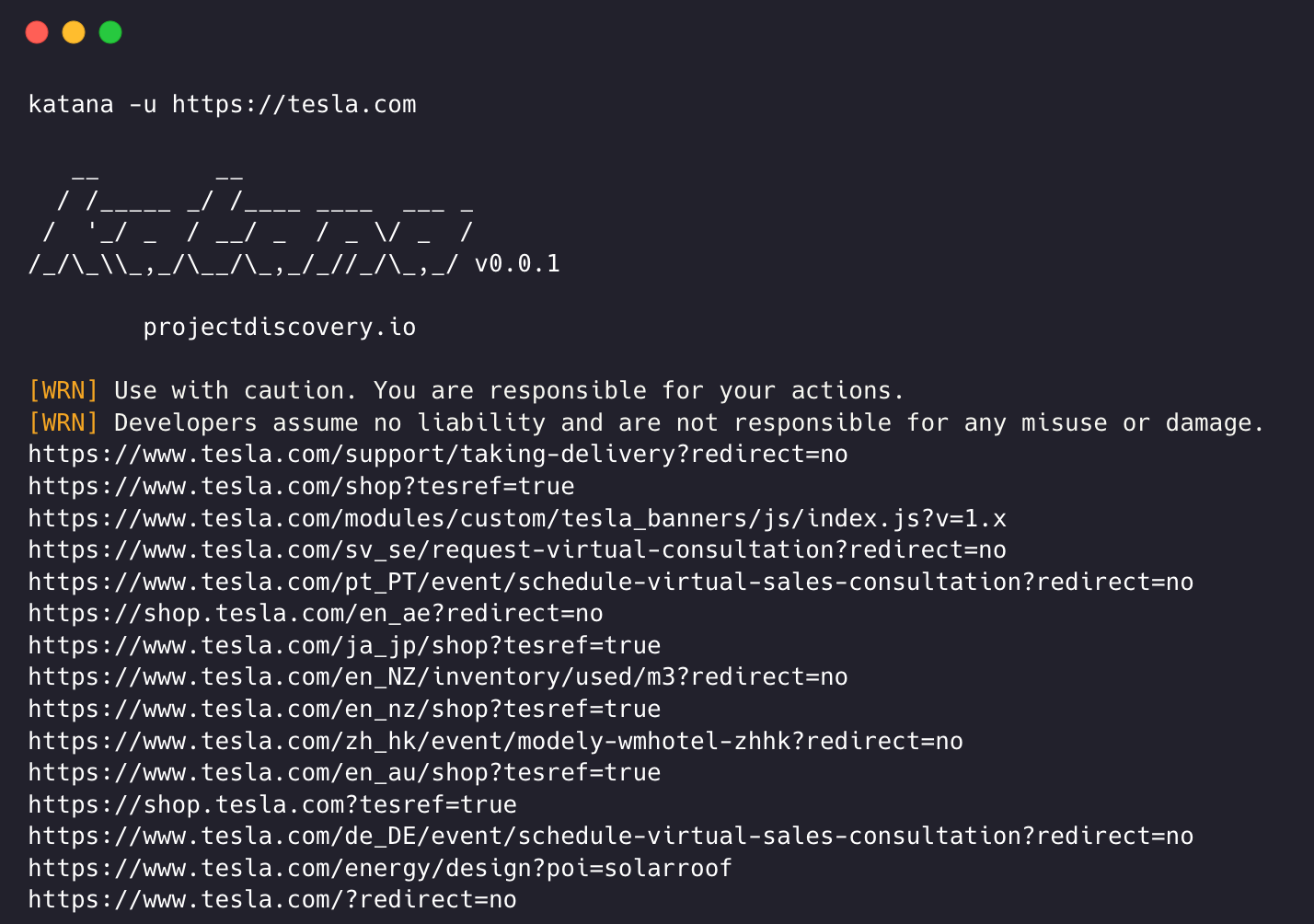
katana -u https://tesla.comkatana -u https://tesla.com,https://google.com$ cat url_list.txt
https://tesla.com
https://google.com katana -list url_list.txt
echo https://tesla.com | katanacat domains | httpx | katanaExemple d'exécution d'un katana -
katana -u https://youtube.com
__ __
/ /_____ _/ /____ ____ ___ _
/ '_/ _ / __/ _ / _ / _ /
/_/_\_,_/__/_,_/_//_/_,_/ v0.0.1
projectdiscovery.io
[WRN] Use with caution. You are responsible for your actions.
[WRN] Developers assume no liability and are not responsible for any misuse or damage.
https://www.youtube.com/
https://www.youtube.com/about/
https://www.youtube.com/about/press/
https://www.youtube.com/about/copyright/
https://www.youtube.com/t/contact_us/
https://www.youtube.com/creators/
https://www.youtube.com/ads/
https://www.youtube.com/t/terms
https://www.youtube.com/t/privacy
https://www.youtube.com/about/policies/
https://www.youtube.com/howyoutubeworks?utm_campaign=ytgen&utm_source=ythp&utm_medium=LeftNav&utm_content=txt&u=https%3A%2F%2Fwww.youtube.com%2Fhowyoutubeworks%3Futm_source%3Dythp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen
https://www.youtube.com/new
https://m.youtube.com/
https://www.youtube.com/s/desktop/4965577f/jsbin/desktop_polymer.vflset/desktop_polymer.js
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-home-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/cssbin/www-onepick.css
https://www.youtube.com/s/_/ytmainappweb/_/ss/k=ytmainappweb.kevlar_base.0Zo5FUcPkCg.L.B1.O/am=gAE/d=0/rs=AGKMywG5nh5Qp-BGPbOaI1evhF5BVGRZGA
https://www.youtube.com/opensearch?locale=en_GB
https://www.youtube.com/manifest.webmanifest
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-watch-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/jsbin/web-animations-next-lite.min.vflset/web-animations-next-lite.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/custom-elements-es5-adapter.vflset/custom-elements-es5-adapter.js
https://www.youtube.com/s/desktop/4965577f/jsbin/webcomponents-sd.vflset/webcomponents-sd.js
https://www.youtube.com/s/desktop/4965577f/jsbin/intersection-observer.min.vflset/intersection-observer.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/scheduler.vflset/scheduler.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-i18n-constants-en_GB.vflset/www-i18n-constants.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-tampering.vflset/www-tampering.js
https://www.youtube.com/s/desktop/4965577f/jsbin/spf.vflset/spf.js
https://www.youtube.com/s/desktop/4965577f/jsbin/network.vflset/network.js
https://www.youtube.com/howyoutubeworks/
https://www.youtube.com/trends/
https://www.youtube.com/jobs/
https://www.youtube.com/kids/ La modalité d'exploration standard utilise la bibliothèque go http standard sous le capot pour gérer les requêtes/réponses HTTP. Cette modalité est beaucoup plus rapide car elle ne nécessite pas de surcharge du navigateur. Néanmoins, il analyse le corps des réponses HTTP tel quel, sans aucun rendu javascript ou DOM, sans aucun point de terminaison rendu post-dom ou sans appels de point de terminaison asynchrones pouvant survenir dans des applications Web complexes en fonction, par exemple, d'événements spécifiques au navigateur.
Le mode sans tête accroche les appels sans tête internes pour gérer les requêtes/réponses HTTP directement dans le contexte du navigateur. Cela offre deux avantages :
L'exploration sans tête est facultative et peut être activée à l'aide de l'option -headless .
Voici d'autres options CLI sans tête -
katana -h headless
Flags:
HEADLESS:
-hl, -headless enable headless hybrid crawling (experimental)
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless mode
-ho, -headless-options string[] start headless chrome with additional options
-nos, -no-sandbox start headless chrome in --no-sandbox mode
-cdd, -chrome-data-dir string path to store chrome browser data
-scp, -system-chrome-path string use specified chrome browser for headless crawling
-noi, -no-incognito start headless chrome without incognito mode
-cwu, -chrome-ws-url string use chrome browser instance launched elsewhere with the debugger listening at this URL
-xhr, -xhr-extraction extract xhr requests -no-sandboxExécute un navigateur Chrome sans tête avec option sans bac à sable , utile lors de l'exécution en tant qu'utilisateur root.
katana -u https://tesla.com -headless -no-sandbox -no-incognitoExécute le navigateur Chrome sans tête sans mode navigation privée, utile lors de l'utilisation du navigateur local.
katana -u https://tesla.com -headless -no-incognito -headless-options Lors de l'exploration en mode sans tête, des options Chrome supplémentaires peuvent être spécifiées à l'aide de -headless-options , par exemple -
katana -u https://tesla.com -headless -system-chrome -headless-options --disable-gpu,proxy-server=http://127.0.0.1:8080 L'exploration peut être sans fin si elle n'est pas étendue, car un tel katana est livré avec plusieurs supports pour définir la portée de l'exploration.
-field-scope Option la plus pratique pour définir la portée avec un nom de champ prédéfini, rdn étant l'option par défaut pour la portée du champ.
rdn - analyse étendue au nom de domaine racine et à tous les sous-domaines (par exemple *example.com ) (par défaut)fqdn - exploration limitée à un sous-domaine donné (par exemple, www.example.com ou api.example.com )dn - l'exploration s'étend au mot-clé du nom de domaine (par exemple, example ) katana -u https://tesla.com -fs dn -crawl-scope Pour un contrôle de portée avancé, l'option -cs peut être utilisée avec la prise en charge des expressions régulières .
katana -u https://tesla.com -cs loginPour les règles à portée multiple, l'entrée de fichier avec une chaîne multiligne/expression régulière peut être transmise.
$ cat in_scope.txt
login/
admin/
app/
wordpress/ katana -u https://tesla.com -cs in_scope.txt -crawl-out-scope Pour définir ce qui ne doit pas être exploré, l'option -cos peut être utilisée et prend également en charge la saisie d' expressions régulières .
katana -u https://tesla.com -cos logoutPour plusieurs règles hors de portée, l'entrée de fichier avec une chaîne multiligne/expression régulière peut être transmise.
$ cat out_of_scope.txt
/logout
/log_out katana -u https://tesla.com -cos out_of_scope.txt -no-scope Katana a par défaut la portée *.domain , pour désactiver cette option -ns peut être utilisée et également pour explorer Internet.
katana -u https://tesla.com -ns -display-out-scope Par défaut, lorsque l'option scope est utilisée, elle s'applique également aux liens à afficher en sortie, car ces URL externes sont par défaut pour exclure et écraser ce comportement, l'option -do peut être utilisée pour afficher toutes les URL externes qui existent dans les cibles. URL/point de terminaison limité.
katana -u https://tesla.com -do
Voici toutes les options CLI pour le contrôle de la portée -
katana -h scope
Flags:
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawling Katana est livré avec plusieurs options pour configurer et contrôler l'exploration comme nous le souhaitons.
-depth Option permettant de définir la depth à laquelle suivre les URL pour l'exploration, plus la profondeur est grande, plus le nombre de points de terminaison analysés + le temps d'analyse sont importants.
katana -u https://tesla.com -d 5
-js-crawlOption pour activer l'analyse des fichiers JavaScript + l'exploration des points de terminaison découverts dans les fichiers JavaScript, désactivée par défaut.
katana -u https://tesla.com -jc
-crawl-durationOption de durée d'analyse prédéfinie, désactivée par défaut.
katana -u https://tesla.com -ct 2
-known-files Option pour activer l'exploration des fichiers robots.txt et sitemap.xml , désactivée par défaut.
katana -u https://tesla.com -kf robotstxt,sitemapxml
-automatic-form-fill Option permettant d'activer le remplissage automatique du formulaire pour les champs connus/inconnus, les valeurs des champs connus peuvent être personnalisées selon les besoins en mettant à jour le fichier de configuration du formulaire à $HOME/.config/katana/form-config.yaml .
Le remplissage automatique des formulaires est une fonctionnalité expérimentale.
katana -u https://tesla.com -aff
L'exploration authentifiée implique l'inclusion d'en-têtes personnalisés ou de cookies dans les requêtes HTTP pour accéder aux ressources protégées. Ces en-têtes fournissent des informations d'authentification ou d'autorisation, vous permettant d'explorer le contenu/point de terminaison authentifié. Vous pouvez spécifier les en-têtes directement dans la ligne de commande ou les fournir sous forme de fichier avec katana pour effectuer une analyse authentifiée.
Remarque : L'utilisateur doit effectuer manuellement l'authentification et exporter le cookie/en-tête de session dans un fichier à utiliser avec Katana.
-headersPossibilité d'ajouter un en-tête personnalisé ou un cookie à la demande.
Syntaxe des en-têtes dans la spécification HTTP
Voici un exemple d’ajout d’un cookie à la requête :
katana -u https://tesla.com -H 'Cookie: usrsess=AmljNrESo'
Il est également possible de fournir des en-têtes ou des cookies sous forme de fichier. Par exemple:
$ cat cookie.txt
Cookie: PHPSESSIONID=XXXXXXXXX
X-API-KEY: XXXXX
TOKEN=XX
katana -u https://tesla.com -H cookie.txt
Il y a plus d'options à configurer en cas de besoin, voici toutes les options CLI liées à la configuration -
katana -h config
Flags:
CONFIGURATION:
-r, -resolvers string[] list of custom resolver (file or comma separated)
-d, -depth int maximum depth to crawl (default 3)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-ct, -crawl-duration int maximum duration to crawl the target for
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml)
-mrs, -max-response-size int maximum response size to read (default 9223372036854775807)
-timeout int time to wait for request in seconds (default 10)
-aff, -automatic-form-fill enable automatic form filling (experimental)
-fx, -form-extraction enable extraction of form, input, textarea & select elements
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom header/cookie to include in request
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file
-flc, -field-config string path to custom field configuration file
-s, -strategy string Visit strategy (depth-first, breadth-first) (default "depth-first")Katana peut également se connecter à une session de navigateur active où l'utilisateur est déjà connecté et authentifié. et utilisez-le pour ramper. La seule condition requise est de démarrer le navigateur avec le débogage à distance activé.
Voici un exemple de démarrage du navigateur Chrome avec le débogage à distance activé et de son utilisation avec Katana :
étape 1) Commencez par localiser le chemin de l'exécutable Chrome
| Système opérateur | Emplacement de l'exécutable Chromium | Emplacement de l'exécutable Google Chrome |
|---|---|---|
| Windows (64 bits) | C:Program Files (x86)GoogleChromiumApplicationchrome.exe | C:Program Files (x86)GoogleChromeApplicationchrome.exe |
| Windows (32 bits) | C:Program FilesGoogleChromiumApplicationchrome.exe | C:Program FilesGoogleChromeApplicationchrome.exe |
| macOS | /Applications/Chromium.app/Contents/MacOS/Chromium | /Applications/Google Chrome.app/Contents/MacOS/Google Chrome |
| Linux | /usr/bin/chromium | /usr/bin/google-chrome |
étape 2) Démarrez Chrome avec le débogage à distance activé et il renverra l'URL de Websocker. Par exemple, sur MacOS, vous pouvez démarrer Chrome avec le débogage à distance activé à l'aide de la commande suivante :
$ /Applications/Google Chrome.app/Contents/MacOS/Google Chrome --remote-debugging-port=9222
DevTools listening on ws://127.0.0.1:9222/devtools/browser/c5316c9c-19d6-42dc-847a-41d1aeebf7d6Connectez-vous maintenant au site Web que vous souhaitez explorer et laissez le navigateur ouvert.
étape 3) Utilisez maintenant l'URL du websocket avec katana pour vous connecter à la session de navigateur active et explorer le site Web.
katana -headless -u https://tesla.com -cwu ws://127.0.0.1:9222/devtools/browser/c5316c9c-19d6-42dc-847a-41d1aeebf7d6 -no-incognitoRemarque : vous pouvez utiliser l'option
-cddpour spécifier un répertoire de données Chrome personnalisé afin de stocker les données du navigateur et les cookies, mais cela n'enregistre pas les données de session si le cookie est défini surSessionuniquement ou expire après un certain temps.
-field Katana est livré avec des champs intégrés qui peuvent être utilisés pour filtrer la sortie pour les informations souhaitées, l'option -f peut être utilisée pour spécifier l'un des champs disponibles.
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
Voici un tableau avec des exemples de chaque champ et le résultat attendu lorsqu'il est utilisé -
| CHAMP | DESCRIPTION | EXEMPLE |
|---|---|---|
url | Point de terminaison de l'URL | https://admin.projectdiscovery.io/admin/login?user=admin&password=admin |
qurl | URL incluant le paramètre de requête | https://admin.projectdiscovery.io/admin/login.php?user=admin&password=admin |
qpath | Chemin incluant le paramètre de requête | /login?user=admin&password=admin |
path | Chemin de l'URL | https://admin.projectdiscovery.io/admin/login |
fqdn | Nom de domaine pleinement qualifié | admin.projectdiscovery.io |
rdn | Nom de domaine racine | projectdiscovery.io |
rurl | URL racine | https://admin.projectdiscovery.io |
ufile | URL avec fichier | https://admin.projectdiscovery.io/login.js |
file | Nom du fichier dans l'URL | login.php |
key | Clés de paramètre dans l'URL | user,password |
value | Valeurs des paramètres dans l'URL | admin,admin |
kv | Clés = valeurs dans l'URL | user=admin&password=admin |
dir | Nom du répertoire URL | /admin/ |
udir | URL avec répertoire | https://admin.projectdiscovery.io/admin/ |
Voici un exemple d'utilisation de l'option de champ pour afficher uniquement toutes les URL contenant un paramètre de requête :
katana -u https://tesla.com -f qurl -silent
https://shop.tesla.com/en_au?redirect=no
https://shop.tesla.com/en_nz?redirect=no
https://shop.tesla.com/product/men_s-raven-lightweight-zip-up-bomber-jacket?sku=1740250-00-A
https://shop.tesla.com/product/tesla-shop-gift-card?sku=1767247-00-A
https://shop.tesla.com/product/men_s-chill-crew-neck-sweatshirt?sku=1740176-00-A
https://www.tesla.com/about?redirect=no
https://www.tesla.com/about/legal?redirect=no
https://www.tesla.com/findus/list?redirect=no
Vous pouvez créer des champs personnalisés pour extraire et stocker des informations spécifiques à partir des réponses de page à l'aide de règles regex. Ces champs personnalisés sont définis à l'aide d'un fichier de configuration YAML et sont chargés à partir de l'emplacement par défaut à $HOME/.config/katana/field-config.yaml . Vous pouvez également utiliser l'option -flc pour charger un fichier de configuration de champ personnalisé à partir d'un emplacement différent. Voici un exemple de champ personnalisé.
- name : email
type : regex
regex :
- ' ([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+.[a-zA-Z0-9_-]+) '
- ' ([a-zA-Z0-9+._-]+@[a-zA-Z0-9._-]+.[a-zA-Z0-9_-]+) '
- name : phone
type : regex
regex :
- ' d{3}-d{8}|d{4}-d{7} 'Lors de la définition de champs personnalisés, les attributs suivants sont pris en charge :
La valeur de l'attribut name est utilisée comme valeur de l'option cli
-field.
Le type d'attribut personnalisé, option actuellement prise en charge -
regex
Partie de la réponse à partir de laquelle extraire les informations. La valeur par défaut est
response, qui inclut à la fois l'en-tête et le corps. Les autres valeurs possibles sontheaderetbody.
Vous pouvez utiliser cet attribut pour sélectionner un groupe correspondant spécifique dans l'expression régulière, par exemple :
group: 1
katana -u https://tesla.com -f email,phone -store-field Pour compléter l'option field qui est utile pour filtrer la sortie au moment de l'exécution, il existe l'option -sf, -store-fields qui fonctionne exactement comme l'option field sauf qu'au lieu de filtrer, elle stocke toutes les informations sur le disque dans le répertoire katana_field triées par URL cible. . Utilisez -sfd ou -store-field-dir pour stocker les données dans un emplacement différent.
katana -u https://tesla.com -sf key,fqdn,qurl -silent
$ ls katana_field/
https_www.tesla.com_fqdn.txt
https_www.tesla.com_key.txt
https_www.tesla.com_qurl.txt L'option -store-field peut être utile pour collecter des informations afin de créer une liste de mots ciblée à diverses fins, y compris, mais sans s'y limiter :
-extension-match La sortie de l'analyse peut être facilement adaptée à une extension spécifique à l'aide de l'option -em pour garantir l'affichage uniquement de la sortie contenant l'extension donnée.
katana -u https://tesla.com -silent -em js,jsp,json
-extension-filter La sortie de l'analyse peut être facilement filtrée pour une extension spécifique à l'aide de l'option -ef qui garantit la suppression de toutes les URL contenant l'extension donnée.
katana -u https://tesla.com -silent -ef css,txt,md
-match-regex L'indicateur -match-regex ou -mr vous permet de filtrer les URL de sortie à l'aide d'expressions régulières. Lors de l'utilisation de cet indicateur, seules les URL correspondant à l'expression régulière spécifiée seront imprimées dans la sortie.
katana -u https://tesla.com -mr 'https://shop.tesla.com/*' -silent
-filter-regex L'indicateur -filter-regex ou -fr vous permet de filtrer les URL de sortie à l'aide d'expressions régulières. Lors de l'utilisation de cet indicateur, les URL qui correspondent à l'expression régulière spécifiée seront ignorées.
katana -u https://tesla.com -fr 'https://www.tesla.com/*' -silent
Katana prend en charge les expressions basées sur DSL pour des capacités avancées de correspondance et de filtrage :
katana -u https://www.hackerone.com -mdc ' status_code == 200 'katana -u https://www.hackerone.com -mdc ' contains(endpoint, "default") && status_code != 403 'katana -u https://www.hackerone.com -mdc ' contains(to_lower(technologies), "php") 'katana -u https://www.hackerone.com -fdc ' contains(to_lower(technologies), "cloudflare") 'Les fonctions DSL peuvent être appliquées à n'importe quelle clé de la sortie jsonl. Pour plus d'informations sur les fonctions DSL disponibles, veuillez visiter le projet DSL.
Voici des options de filtrage supplémentaires -


