open_llama
1.0.0
TL;DR : nous publions notre aperçu public d'OpenLLaMA, une reproduction open source sous licence permissive de LLaMA de Meta AI. Nous publions une série de modèles 3B, 7B et 13B formés sur différents mélanges de données. Nos poids de modèle peuvent servir de remplacement de LLaMA dans les implémentations existantes.
Dans ce dépôt, nous présentons une reproduction open source sous licence permissive du grand modèle de langage LLaMA de Meta AI. Nous lançons une série de modèles 3B, 7B et 13B formés sur des tokens 1T. Nous fournissons des poids PyTorch et JAX des modèles OpenLLaMA pré-entraînés, ainsi que des résultats d'évaluation et une comparaison avec les modèles LLaMA d'origine. Le modèle v2 est meilleur que l'ancien modèle v1 formé sur un mélange de données différent.
Nous publions le modèle OpenLLaMA 3Bv3, qui est un modèle 3B formé pour les jetons 1T sur le même mélange d'ensembles de données que le modèle 7Bv2.
Nous sommes heureux de publier un modèle OpenLLaMA 7Bv2, qui est formé sur un mélange d'ensemble de données Web raffiné Falcon, mélangé à l'ensemble de données starcoder, et à wikipedia, arxiv et aux livres et stackexchange de RedPajama.
Nous sommes heureux de publier notre version finale du token 1T d'OpenLLaMA 13B. Nous avons mis à jour les résultats de l'évaluation. Pour la version actuelle des modèles OpenLLaMA, notre tokenizer est formé pour fusionner plusieurs espaces vides en un seul avant la tokenisation, similaire au tokenizer T5. Pour cette raison, notre tokenizer ne fonctionnera pas avec les tâches de génération de code (par exemple HumanEval) puisque le code implique de nombreux espaces vides. Pour les tâches liées au code, veuillez utiliser les modèles v2.
Nous sommes heureux de publier notre version finale du token 1T d'OpenLLaMA 3B et 7B. Nous avons mis à jour les résultats de l'évaluation. Nous sommes également heureux de publier un aperçu du jeton 600B du modèle 13B, formé en collaboration avec Stability AI.
Nous sommes heureux de publier notre point de contrôle de jeton 700B pour le modèle OpenLLaMA 7B et notre point de contrôle de jeton 600B pour le modèle 3B. Nous avons également mis à jour les résultats de l'évaluation. Nous prévoyons que la formation complète des jetons 1T se terminera à la fin de cette semaine.
Après avoir reçu les commentaires de la communauté, nous avons découvert que le tokenizer de notre précédente version de point de contrôle était mal configuré, de sorte que les nouvelles lignes ne sont pas préservées. Pour résoudre ce problème, nous avons recyclé notre tokenizer et redémarré la formation du modèle. Nous avons également observé une perte de formation moindre avec ce nouveau tokenizer.
Nous publions les poids dans deux formats : un format EasyLM à utiliser avec notre framework EasyLM et un format PyTorch à utiliser avec la bibliothèque de transformateurs Hugging Face. Notre cadre de formation EasyLM et les poids de point de contrôle sont sous licence permissive sous la licence Apache 2.0.
Les points de contrôle d’aperçu peuvent être directement chargés depuis Hugging Face Hub. Veuillez noter qu'il est conseillé d'éviter d'utiliser le tokenizer rapide Hugging Face pour l'instant, car nous avons observé que le tokenizer rapide auto-converti donne parfois des tokenisations incorrectes . Ceci peut être réalisé en utilisant directement la classe LlamaTokenizer ou en passant l'option use_fast=False pour la classe AutoTokenizer . Voir l'exemple suivant pour l'utilisation.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Pour une utilisation plus avancée, veuillez suivre la documentation des transformateurs LLaMA.
Le modèle peut être évalué avec lm-eval-harness. Cependant, en raison du problème du tokenizer mentionné ci-dessus, nous devons éviter d'utiliser le tokenizer rapide pour obtenir les bons résultats. Ceci peut être réalisé en passant use_fast=False à cette partie de lm-eval-harness, comme le montre l'exemple ci-dessous :
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Pour utiliser les poids dans notre framework EasyLM, veuillez vous référer à la documentation LLaMA d'EasyLM. Notez que contrairement au modèle LLaMA d'origine, notre tokenizer et nos poids OpenLLaMA sont entièrement formés à partir de zéro, il n'est donc plus nécessaire pour obtenir le tokenizer et nos poids LLaMA d'origine.
Les modèles v1 sont formés sur l'ensemble de données RedPajama. Les modèles v2 sont formés sur un mélange de l'ensemble de données Web raffiné Falcon, de l'ensemble de données StarCoder et de la partie wikipedia, arxiv, book et stackexchange de l'ensemble de données RedPajama. Nous suivons exactement les mêmes étapes de prétraitement et hyperparamètres de formation que l'article LLaMA original, y compris l'architecture du modèle, la longueur du contexte, les étapes de formation, le calendrier de taux d'apprentissage et l'optimiseur. La seule différence entre notre paramètre et celui d'origine est l'ensemble de données utilisé : OpenLLaMA utilise des ensembles de données ouverts plutôt que celui utilisé par le LLaMA d'origine.
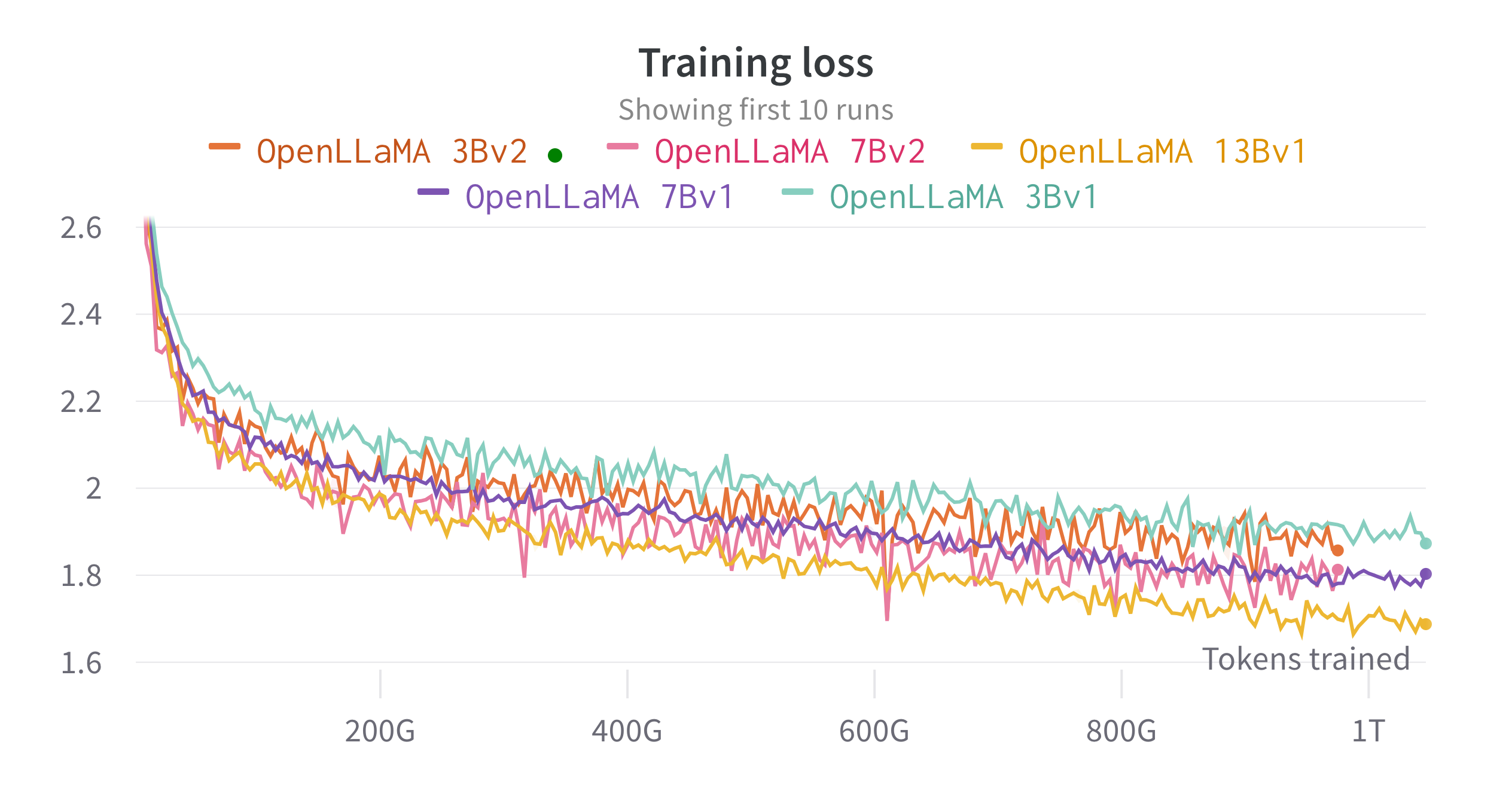
Nous formons les modèles sur des Cloud TPU-v4 à l'aide d'EasyLM, un pipeline de formation basé sur JAX que nous avons développé pour former et affiner de grands modèles de langage. Nous utilisons une combinaison de parallélisme de données normal et de parallélisme de données entièrement fragmentées (également connu sous le nom de ZeRO stage 3) pour équilibrer le débit de formation et l'utilisation de la mémoire. Au total, nous atteignons un débit de plus de 2 200 jetons/seconde/puce TPU-v4 pour notre modèle 7B. La perte de formation est visible dans la figure ci-dessous.
Nous avons évalué OpenLLaMA sur un large éventail de tâches à l'aide de lm-evaluation-harness. Les résultats LLaMA sont générés en exécutant le modèle LLaMA original sur les mêmes métriques d'évaluation. Nous notons que nos résultats pour le modèle LLaMA diffèrent légèrement de l'article original de LLaMA, qui, selon nous, est le résultat de protocoles d'évaluation différents. Des différences similaires ont été signalées dans ce numéro de lm-evaluation-harness. De plus, nous présentons les résultats de GPT-J, un modèle de paramètres 6B formé sur l'ensemble de données Pile par EleutherAI.
Le modèle LLaMA original a été formé pour 1 000 milliards de jetons et GPT-J a été formé pour 500 milliards de jetons. Nous présentons les résultats dans le tableau ci-dessous. OpenLLaMA présente des performances comparables à celles des LLaMA et GPT-J d'origine dans une majorité de tâches et les surpasse dans certaines tâches.
| Tâche/métrique | GPT-J6B | LLaMA 7B | LLaMA 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OuvrirLLaMA 3B | OuvrirLLaMA 7B | OuvrirLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/acc | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/acc | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/acc | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arc_easy/acc | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/acc | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/acc | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| livre ouvertqa/acc | 0,29 | 0,29 | 0,31 | 0,26 | 0,30 | 0,27 | 0,30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| piqa/acc | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| enregistrer/em | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| enregistrement/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| rte/acc | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| véridiqueqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| véridiqueqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| wic/acc | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| winogrande/acc | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Moyenne | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Nous avons supprimé les tâches CB et WSC de notre benchmark, car notre modèle a des performances suspectes sur ces deux tâches. Nous émettons l’hypothèse qu’il pourrait y avoir une contamination des données de référence dans l’ensemble de formation.
Nous serions ravis d’avoir des commentaires de la communauté. Si vous avez des questions, veuillez ouvrir un problème ou nous contacter.
OpenLLaMA est développé par : Xinyang Geng* et Hao Liu* de Berkeley AI Research. *Contribution égale
Nous remercions le programme Google TPU Research Cloud pour avoir fourni une partie des ressources de calcul. Nous tenons à remercier spécialement Jonathan Caton de TPU Research Cloud pour nous avoir aidé à organiser les ressources de calcul, Rafi Witten de l'équipe Google Cloud et James Bradbury de l'équipe Google JAX pour nous avoir aidés à optimiser notre débit de formation. Nous souhaitons également remercier Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng et notre communauté d'utilisateurs pour les discussions et les commentaires.
Le modèle OpenLLaMA 13B v1 est formé en collaboration avec Stability AI, et nous remercions Stability AI d'avoir fourni les ressources de calcul. Nous tenons à remercier particulièrement David Ha et Shivanshu Purohit pour la coordination de la logistique et le soutien technique.
Si vous avez trouvé OpenLLaMA utile dans votre recherche ou vos applications, veuillez citer en utilisant le BibTeX suivant :
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


