LLM4Decompile
1.0.0
![]()
Résultats | ? Modèles | Démarrage rapide | HumanEval-Décompiler | ? Citation | Papier | Colab |
Ingénierie inverse : décompilation de code binaire avec de grands modèles de langage
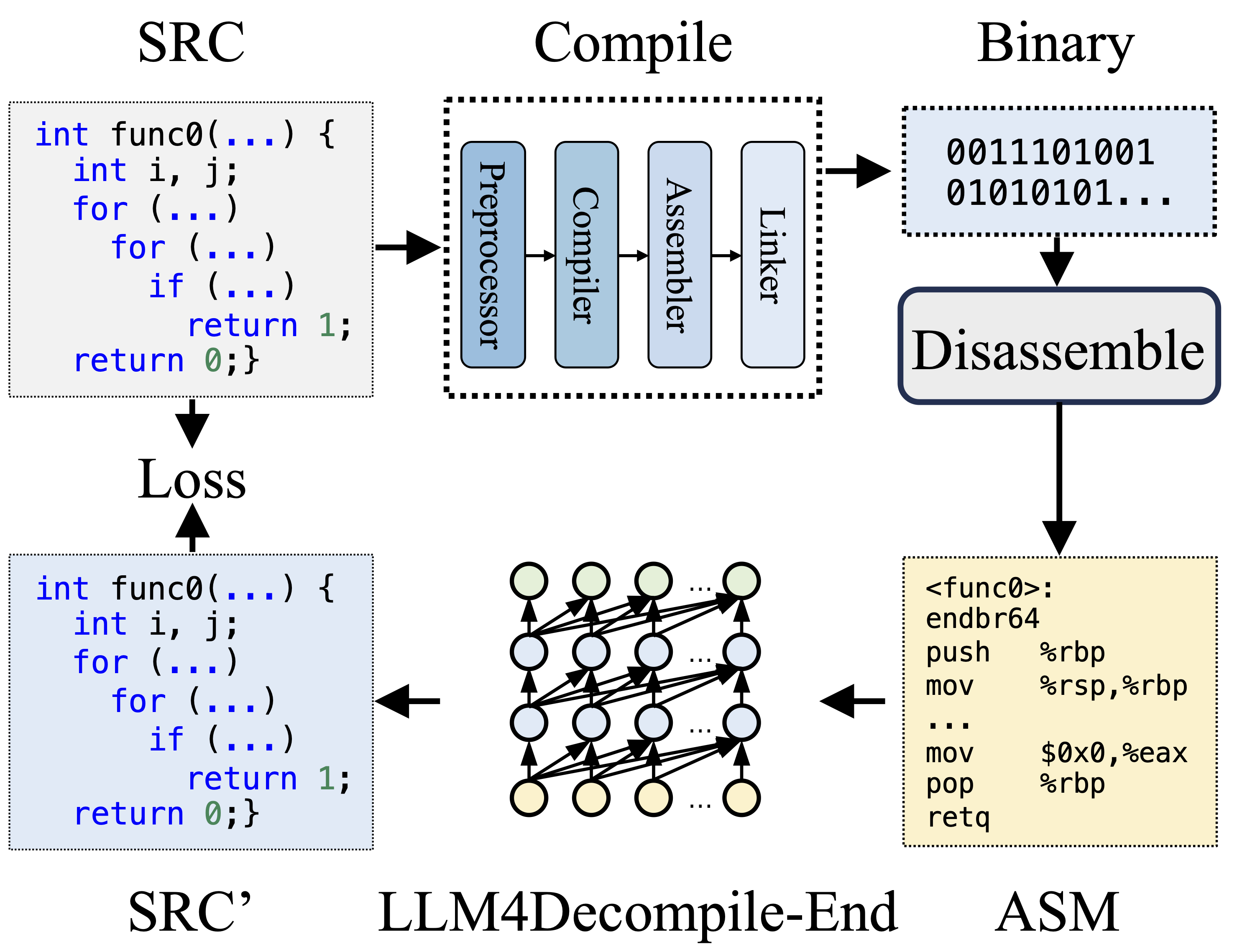
Lors de la compilation, le préprocesseur traite le code source (SRC) pour éliminer les commentaires et développer les macros ou les inclusions. Le code nettoyé est ensuite transmis au compilateur, qui le convertit en code assembleur (ASM). Cet ASM est transformé en code binaire (0 et 1) par l'Assembleur. Le Linker finalise le processus en reliant les appels de fonction pour créer un fichier exécutable. La décompilation, quant à elle, consiste à reconvertir le code binaire en fichier source. Les LLM, formés sur le texte, n'ont pas la capacité de traiter directement les données binaires. Par conséquent, les binaires doivent d’abord être désassemblés par Objdump en langage assembleur (ASM). Il convient de noter que les ASM binaires et désassemblés sont équivalents, ils peuvent être interconvertis et nous les appelons donc de manière interchangeable. Enfin, la perte est calculée entre le code décompilé et le code source pour guider la formation. Pour évaluer la qualité du code décompilé (SRC'), sa fonctionnalité est testée via des assertions de test (ré-exécutabilité).
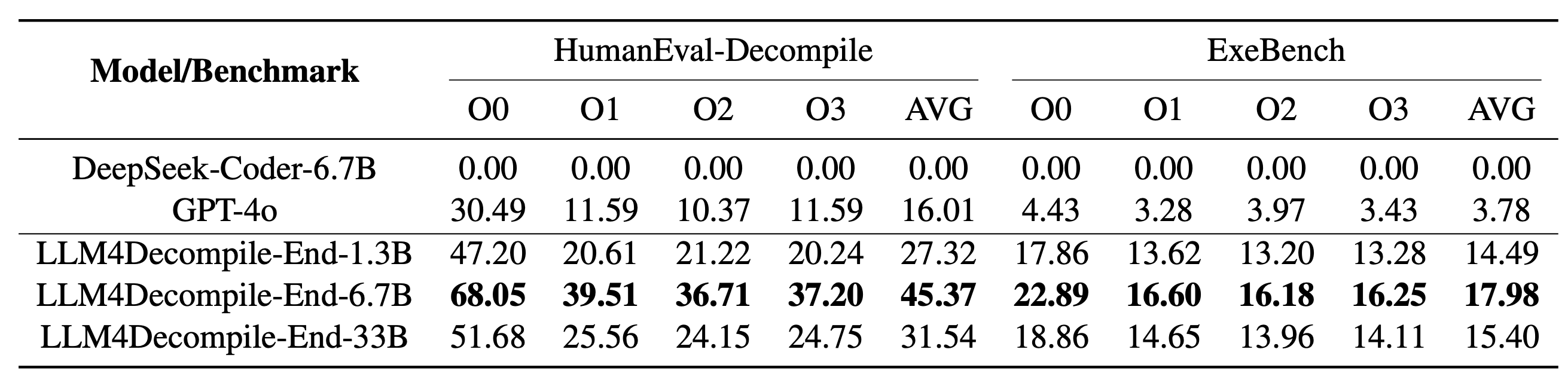
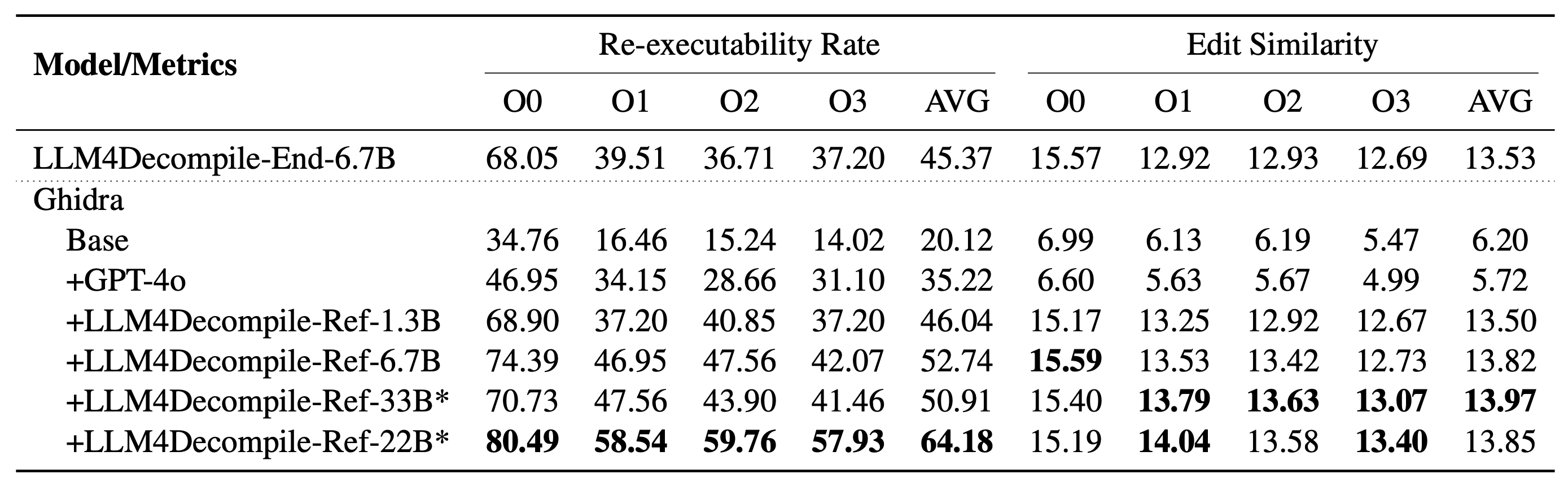
Notre LLM4Decompile comprend des modèles avec des tailles comprises entre 1,3 milliard et 33 milliards de paramètres, et nous avons rendu ces modèles disponibles sur Hugging Face.
| Modèle | Point de contrôle | Taille | Réexécutabilité | Note |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? Liaison HF | 1,3B | 27,3% | Remarque 3 |
| llm4decompile-6.7b-v1.5 | ? Liaison HF | 6,7B | 45,4% | Remarque 3 |
| llm4decompile-1.3b-v2 | ? Liaison HF | 1,3B | 46,0% | Remarque 4 |
| llm4decompile-6.7b-v2 | ? Liaison HF | 6,7B | 52,7% | Remarque 4 |
| llm4decompile-9b-v2 | ? Liaison HF | 9B | 64,9% | Remarque 4 |
| llm4decompile-22b-v2 | ? Liaison HF | 22B | 63,6% | Remarque 4 |
Remarque 3 : Les séries V1.5 sont entraînées avec un ensemble de données plus grand (15 B de jetons) et une taille maximale de jetons de 4 096, avec des performances remarquables (amélioration de plus de 100 %) par rapport au modèle précédent.
Remarque 4 : la série V2 est construite sur Ghidra et formée sur 2 milliards de jetons pour affiner le pseudo-code décompilé de Ghidra. Consultez le dossier ghidra pour plus de détails.
Configuration : veuillez utiliser le script ci-dessous pour installer l'environnement nécessaire.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Voici un exemple d'utilisation de notre modèle (Révisé pour la V1.5. Pour les modèles précédents, veuillez consulter la page du modèle correspondant chez HF). Remarque : remplacez "func0" par le nom de la fonction que vous souhaitez décompiler .
Prétraitement : compilez le code C en binaire et désassemblez le binaire en instructions d'assemblage.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )Les instructions de montage doivent être au format :
<FUNCTION_NAME> :nOPÉRATIONSnOPÉRATIONSn
Les instructions de montage typiques peuvent ressembler à ceci :
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Décompilation : utilisez LLM4Decompile pour traduire les instructions d'assemblage en C :
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Les données sont stockées dans llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json , en utilisant le format de liste JSON. Il y a 164*4 (O0, O1, O2, O3) échantillons, chacun avec cinq touches :
task_id : indique l'ID du problème.type : l'étape d'optimisation, est l'une des [O0, O1, O2, O3].c_func : solution C pour le problème HumanEval.c_test : assertions de test C.input_asm_prompt : les instructions d'assemblage avec des invites, peuvent être dérivées comme dans notre exemple de prétraitement.Veuillez vérifier les scripts d'évaluation.
Ce référentiel de code est sous licence MIT et DeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


