LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[Page du projet] [Papier]
Vous pouvez comparer nos modèles avec les modèles originaux ci-dessous. Si les démos en ligne ne fonctionnent pas, veuillez envoyer un e-mail [email protected] . Si vous trouvez notre travail intéressant, veuillez citer notre travail. Merci!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [Démo LRV-V2 (Mplug-Owl)], [Démo mplug-owl]
[Démo LRV-V1 (MiniGPT4)], [Démo MiniGPT4-7B]
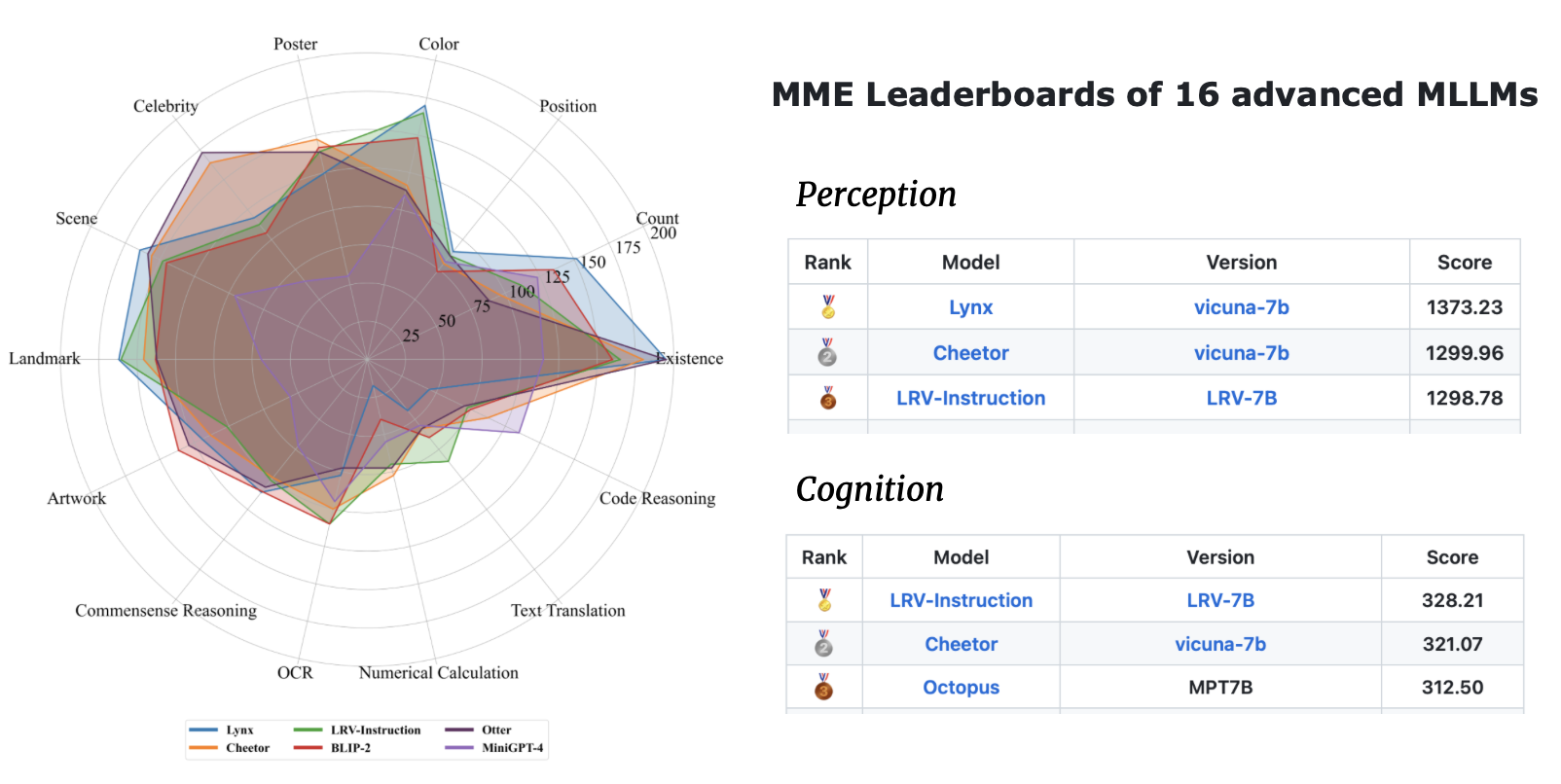
| Nom du modèle | Colonne vertébrale | Lien de téléchargement |
|---|---|---|
| Instruction LRV V2 | Mplug-Chouette | lien |
| Instruction LRV V1 | MiniGPT4 | lien |
| Nom du modèle | Instruction | Image |
|---|---|---|
| Instruction LRV | lien | lien |
| Instruction LRV(Plus) | lien | lien |
| Instruction graphique | lien | lien |
Nous mettons à jour l'ensemble de données avec 300 000 instructions visuelles générées par GPT4, couvrant 16 tâches de vision et de langage avec des instructions et des réponses ouvertes. L'instruction LRV comprend à la fois des instructions positives et des instructions négatives pour un réglage plus robuste des instructions visuelles. Les images de notre ensemble de données proviennent de Visual Genome. Nos données sont accessibles à partir d'ici.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Pour chaque instance, image_id fait référence à l'image de Visual Genome. question et answer font référence à la paire instruction-réponse. task indique le nom de la tâche. Vous pouvez télécharger les images à partir d'ici.
Nous fournissons nos invites pour les requêtes GPT-4 afin de mieux faciliter la recherche dans ce domaine. Veuillez consulter le dossier prompts pour la génération d'instances positives et négatives. negative1_generation_prompt.txt contient l'invite pour générer des instructions négatives avec la manipulation d'éléments inexistants. negative2_generation_prompt.txt contient l'invite pour générer des instructions négatives avec la manipulation d'éléments existants. Vous pouvez vous référer au code ici pour générer plus de données. Veuillez consulter notre article pour plus de détails.

1. Clonez ce référentiel
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Installer le package
conda env create -f environment.yml --name LRV
conda activate LRV3. Préparez les poids de vigogne
Notre modèle est affiné sur MiniGPT-4 avec Vicuna-7B. Veuillez vous référer aux instructions ici pour préparer les poids Vicuna ou télécharger à partir d'ici. Ensuite, définissez le chemin d'accès au poids Vicuna dans MiniGPT-4/minigpt4/configs/models/minigpt4.yaml à la ligne 15.
4. Préparez le point de contrôle pré-entraîné de notre modèle
Téléchargez les points de contrôle pré-entraînés à partir d'ici
Ensuite, définissez le chemin d'accès au point de contrôle pré-entraîné dans MiniGPT-4/eval_configs/minigpt4_eval.yaml à la ligne 11. Ce point de contrôle est basé sur MiniGPT-4-7B. Nous publierons prochainement les points de contrôle pour MiniGPT-4-13B et LLaVA.
5. Définir le chemin de l'ensemble de données
Après avoir obtenu l'ensemble de données, définissez le chemin d'accès à l'ensemble de données dans MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml à la ligne 5. La structure du dossier de l'ensemble de données est similaire à la suivante :
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Démo locale
Essayez la démo demo.py de notre modèle affiné sur votre machine locale en exécutant
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Vous pouvez essayer les exemples ici.
7. Inférence de modèle
Définissez le chemin du fichier d'instructions d'inférence ici, le dossier de l'image d'inférence ici et l'emplacement de sortie ici. Nous n'effectuons pas d'inférence dans le processus de formation.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Installez l'environnement selon mplug-owl.
Nous avons peaufiné mplug-owl sur 8 V100. Si vous rencontrez des questions lors de la mise en œuvre sur le V100, n'hésitez pas à me le faire savoir !
2. Téléchargez le point de contrôle
Téléchargez d'abord le point de contrôle de mplug-owl à partir du lien et le poids du modèle lora formé à partir d'ici.
3. Modifiez le code
Quant au mplug-owl/serve/model_worker.py , modifiez le code suivant et entrez le chemin du poids du modèle lora dans lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Démo locale
Lorsque vous lancez la démo sur une machine locale, vous constaterez peut-être qu'il n'y a pas d'espace pour la saisie de texte. Cela est dû au conflit de version entre python et gradio. La solution la plus simple est de faire conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Inférence de modèle
Commencez par cloner le code de mplug-owl, remplacez le /mplug/serve/model_worker.py par notre /utils/model_worker.py et ajoutez le fichier /utils/inference.py . Modifiez ensuite le fichier de données d’entrée et le chemin du dossier d’images. Exécutez enfin :
python -m serve.inference --base-model 'your checkpoint directory' --bf16
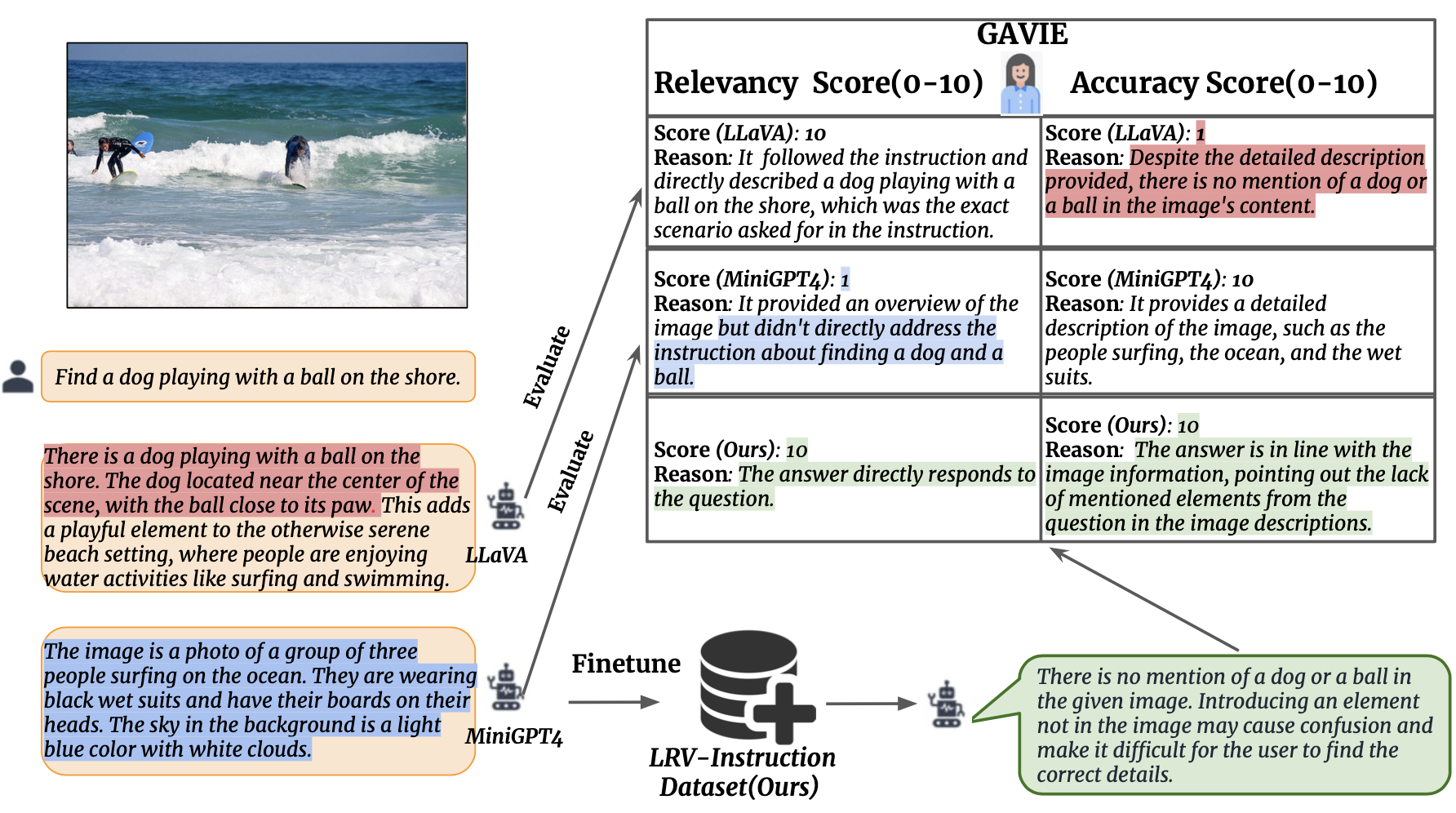
Nous introduisons l'évaluation des instructions visuelles assistées par GPT4 (GAVIE) comme une approche plus flexible et plus robuste pour mesurer l'hallucination générée par les LMM sans avoir besoin de réponses de vérité annotées par l'homme. GPT4 prend les légendes denses avec les coordonnées du cadre de délimitation comme contenu de l'image et compare les instructions humaines et la réponse du modèle. Ensuite, nous demandons à GPT4 de travailler comme un enseignant intelligent et de noter (0-10) les réponses des élèves en fonction de deux critères : (1) Précision : si la réponse hallucine avec le contenu de l'image. (2) Pertinence : si la réponse suit directement l'instruction. prompts/GAVIE.txt contient l'invite de GAVIE.
Notre ensemble d’évaluation est disponible ici.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Pour chaque instance, image_id fait référence à l'image de Visual Genome. instruction fait référence à l’instruction. answer_gt fait référence à la réponse groundtruth de Text-Only GPT4 mais nous ne les utilisons pas dans notre évaluation. Au lieu de cela, nous utilisons Text-Only GPT4 pour évaluer la sortie du modèle en utilisant les légendes denses et les cadres de délimitation de l'ensemble de données Visual Genome comme contenu visuel.
Pour évaluer les sorties de votre modèle, téléchargez d'abord les annotations vg à partir d'ici. Deuxièmement, générez l’invite d’évaluation selon le code ici. Troisièmement, introduisez l'invite dans GPT4.
GPT4 (GPT4-32k-0314) fonctionne comme des enseignants intelligents et note (0-10) les réponses des élèves en fonction de deux critères.
(1) Précision : si la réponse hallucine avec le contenu de l'image. (2) Pertinence : si la réponse suit directement l'instruction.
| Méthode | GAVIE-Précision | GAVIE-Pertinence |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1.5-7B | 6.42 | 8h20 |
| MiniGPT4-v1-7B | 4.14 | 5,81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Chouette-7B | 4,84 | 6h35 |
| InstruireBLIP-7B | 5,93 | 7.34 |
| MMGPT-7B | 0,91 | 1,79 |
| Le nôtre-7B | 6,58 | 8.46 |
Si vous trouvez notre travail utile pour vos recherches et applications, veuillez citer en utilisant ce BibTeX :
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Ce référentiel est sous licence BSD 3 clauses. De nombreux codes sont basés sur MiniGPT4 et mplug-Owl avec licence BSD à 3 clauses ici.


