Q Bench
1.0.0
Comment les LLM multimodalités fonctionnent-ils sur la vision par ordinateur de bas niveau ?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 Université technologique de Nanyang, 2 Université Jiaotong de Shanghai, 3 Sensetime Research
* Contribution égale. # Auteur correspondant.
Pleins feux sur l'ICLR2024
Papier | Page du projet | GitHub | Données (LLVisionQA) | Données (LLDescribe) |质衡 (chinois-Q-Bench)


Le Q-Bench proposé comprend trois domaines pour la vision de bas niveau : la perception (A1), la description (A2) et l'évaluation (A3).
Pour la perception (A1)/description (A2), nous collectons deux ensembles de données de référence LLVisionQA/LLDescribe.
Nous sommes ouverts à une évaluation basée sur les soumissions pour les deux tâches. Les détails de la soumission sont les suivants.
Pour l'évaluation (A3), comme nous utilisons des ensembles de données publics , nous fournissons un code d'évaluation abstrait pour les MLLM arbitraires que quiconque peut tester.
datasets Pour le Q-Bench-A1 (avec questions à choix multiples), nous les avons convertis en ensembles de données au format HF qui peuvent être automatiquement téléchargés et utilisés avec l'API datasets . Veuillez vous référer aux instructions suivantes :
ensembles de données d'installation pip
à partir des ensembles de données import load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id' : 0,### 'image' : <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'Comment est l'éclairage de ce bâtiment ?',### 'option0' : 'Élevé',### 'option1' : 'Faible',### 'option2' : 'Moyen',### 'option3' : 'N/A', ### 'question_type' : 2,### 'question_concern' : 3,### 'correct_choice' : 'B'} à partir des ensembles de données import load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id' : 0,### 'image1' : <PIL .Image.Image mode image=Taille RVB=4032x3024>,### 'image2' : <image PIL.JpegImagePlugin.JpegImageFile mode=Taille RVB=864x1152>,### 'question': 'Par rapport à la première image, quelle est la clarté de la deuxième image ?',### 'option0': 'Plus flou',### 'option1 ': 'Plus clair',### 'option2': 'À peu près pareil',### 'option3': 'N/A',### 'question_type' : 2,### 'question_concern' : 0,### 'correct_choice' : 'B'}[2024/8/8] La partie tâche de comparaison de vision de bas niveau de Q-bench+ (également appelée Q-Bench2) vient d'être acceptée par TPAMI ! Venez tester votre MLLM avec Q-bench+_Dataset.
[2024/8/1] Le Q-Bench est publié sur VLMEvalKit, venez tester votre LMM avec une commande comme `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
[2024/6/17] Les Q-Bench , Q-Bench2 (Q-bench+) et A-Bench ont désormais rejoint lmms-eval, ce qui facilite le test de LMM !!
[2024/6/3] Le dépôt Github pour A-Bench est en ligne. Voulez-vous savoir si votre LMM maîtrise parfaitement l’évaluation des images générées par l’IA ? Venez tester sur A-Bench !!
[3/1] Nous publions ici Co-instruct , Towards Open-ended Visual Quality Comparison . Plus de détails seront bientôt disponibles.
[2/27] Notre travail Q-Insturct a été accepté par le CVPR 2024, essayez d'apprendre les détails sur la façon d'instruire les MLLM sur la vision de bas niveau !
[2/23] La partie tâche de comparaison de vision de bas niveau de Q-bench+ est maintenant publiée sur Q-bench+ (Dataset) !
[2/10] Nous publions le Q-bench+ étendu, qui défie les MLLM avec à la fois des images uniques et des paires d'images sur la vision de bas niveau. Le LeaderBoard est sur place, découvrez la capacité de vision de bas niveau pour vos MLLM préférés !! Plus de détails à venir.
[1/16] Notre travail « Q-Bench : A Benchmark for General-Purpose Foundation Models on Low-level Vision » est accepté par l'ICLR2024 en tant que présentation Spotlight .

Nous testons sur trois modèles d'API proches, GPT-4V-Turbo ( gpt-4-vision-preview , remplaçant l' ancienne version des résultats GPT-4V, qui n'est plus disponible), Gemini Pro ( gemini-pro-vision ) et Qwen. -VL-Plus ( qwen-vl-plus ). Légèrement amélioré par rapport à l'ancienne version, le GPT-4V est toujours en tête de tous les MLLM et offre presque les performances d'un humain de niveau junior. Gemini Pro et Qwen-VL-Plus suivent derrière, toujours meilleurs que les meilleurs MLLM open source (0,65 au total).
Mise à jour le [2024/7/18], nous sommes heureux de publier la nouvelle performance SOTA de BlueImage-GPT (source proche).
Perception, A1-Single
| Nom du participant | oui ou non | quoi | comment | distorsion | autres | distorsion contextuelle | dans le contexte des autres | dans l'ensemble |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,7574 | 0,7325 | 0,5733 | 0,6488 | 0,7324 | 0,6867 | 0,7056 | 0,6893 |
BlueImage-GPT ( from VIVO Nouveau Champion ) | 0,8467 | 0,8351 | 0,7469 | 0,7819 | 0,8594 | 0,7995 | 0,8240 | 0,8107 |
Gemini-Pro ( gemini-pro-vision ) | 0,7221 | 0,7300 | 0,6645 | 0,6530 | 0,7291 | 0,7082 | 0,7665 | 0,7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0,7722 | 0,7839 | 0,6645 | 0,7101 | 0,7107 | 0,7936 | 0,7891 | 0,7410 |
| GPT-4V ( ancienne version ) | 0,7792 | 0,7918 | 0,6268 | 0,7058 | 0,7303 | 0,7466 | 0,7795 | 0,7336 |
| humain-1-junior | 0,8248 | 0,7939 | 0,6029 | 0,7562 | 0,7208 | 0,7637 | 0,7300 | 0,7431 |
| humain-2-senior | 0,8431 | 0,8894 | 0,7202 | 0,7965 | 0,7947 | 0,8390 | 0,8707 | 0,8174 |
Perception, paire A1
| Nom du participant | oui ou non | quoi | comment | distorsion | autres | comparer | articulation | dans l'ensemble |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,6685 | 0,5579 | 0,5991 | 0,6246 | 0,5877 | 0,6217 | 0,5920 | 0,6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0,6765 | 0,6756 | 0,6535 | 0,6909 | 0,6118 | 0,6865 | 0,6129 | 0,6699 |
BlueImage-GPT ( from VIVO Nouveau Champion ) | 0,8843 | 0,8033 | 0,7958 | 0,8464 | 0,8062 | 0,8462 | 0,7955 | 0,8348 |
Gemini-Pro ( gemini-pro-vision ) | 0,6578 | 0,5661 | 0,5674 | 0,6042 | 0,6055 | 0,6046 | 0,6044 | 0,6046 |
GPT-4V ( gpt-4-vision ) | 0,7975 | 0,6949 | 0,8442 | 0,7732 | 0,7993 | 0,8100 | 0,6800 | 0,7807 |
| Humain de niveau junior | 0,7811 | 0,7704 | 0,8233 | 0,7817 | 0,7722 | 0,8026 | 0,7639 | 0,8012 |
| Humain de niveau supérieur | 0,8300 | 0,8481 | 0,8985 | 0,8313 | 0,9078 | 0,8655 | 0,8225 | 0,8548 |
Nous avons également récemment évalué plusieurs nouveaux modèles open source et publierons bientôt leurs résultats.
Nous proposons désormais deux façons de télécharger les ensembles de données (LLVisionQA&LLDescribe)
via GitHub Release : veuillez consulter notre version pour plus de détails.
via les ensembles de données Huggingface : veuillez vous référer aux notes de publication des données pour télécharger les images.
Il est fortement recommandé de convertir votre modèle au format Huggingface pour tester ces données en douceur. Consultez les exemples de scripts pour IDEFICS-9B-Instruct de Huggingface à titre d'exemple et modifiez-les pour que votre modèle personnalisé puisse être testé sur votre modèle.
Veuillez envoyer un e-mail [email protected] pour soumettre votre résultat au format json.
Vous pouvez également nous soumettre votre modèle (il peut s'agir de Huggingface AutoModel ou ModelScope AutoModel), ainsi que vos scripts d'évaluation personnalisés. Vos scripts personnalisés peuvent être modifiés à partir des scripts modèles qui fonctionnent pour LLaVA-v1.5 (pour A1/A2) et ici (pour l'évaluation de la qualité de l'image).
Veuillez envoyer un e-mail [email protected] pour soumettre votre modèle si vous êtes en dehors de la Chine continentale. Veuillez envoyer un e-mail à [email protected] pour soumettre votre modèle si vous êtes en Chine continentale.
Un instantané de l'ensemble de données de référence LLVisionQA pour la capacité de perception de bas niveau MLLM est le suivant. Voir le classement ici.
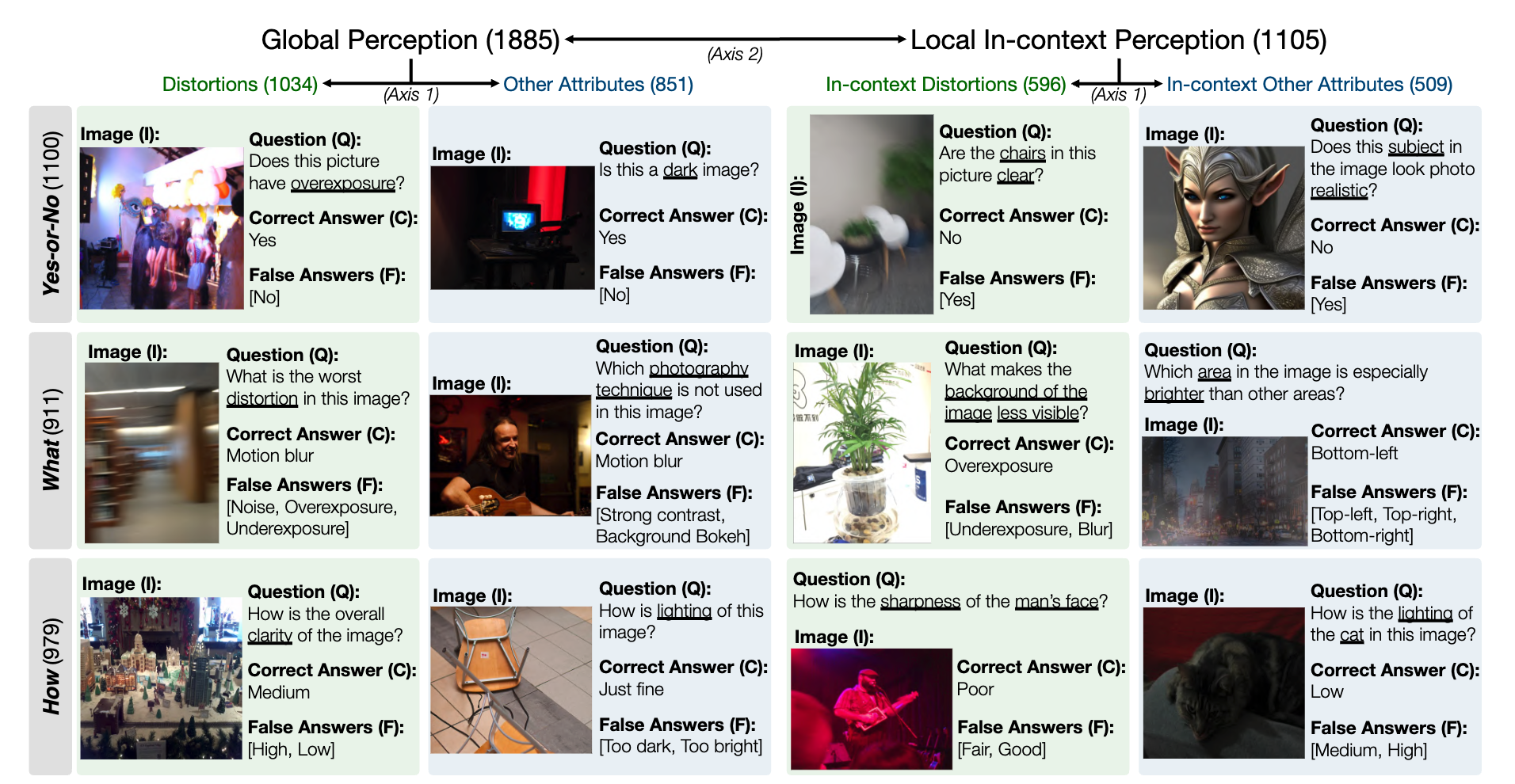
Nous mesurons l'exactitude des réponses des MLLM (fournis avec la question et tous les choix) comme métrique ici.
Un instantané de l'ensemble de données de référence LLDescribe pour la capacité de description de bas niveau MLLM est le suivant. Voir le classement ici.

Nous mesurons ici l' exhaustivité , la précision et la pertinence des descriptions MLLM.
Une capacité passionnante grâce à laquelle les MLLM sont capables de prédire les scores quantitatifs pour l’IQA !
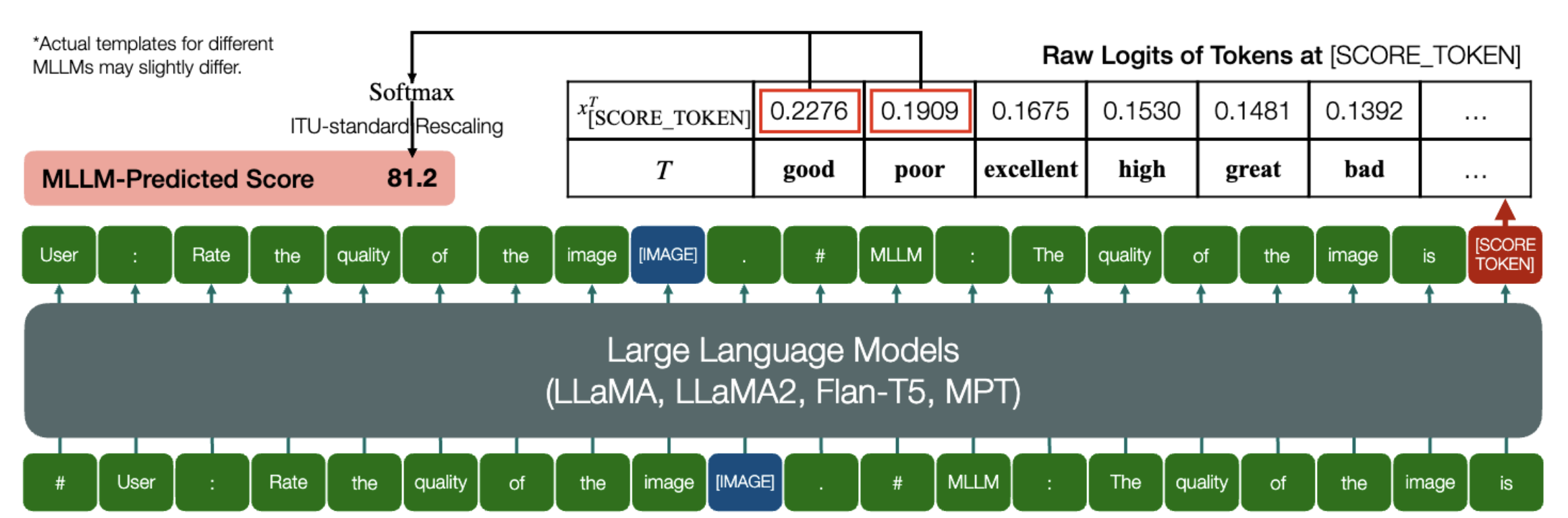
De la même manière que ci-dessus, tant qu'un modèle (basé sur des modèles de langage causal) dispose des deux méthodes suivantes : embed_image_and_text (pour permettre des entrées multimodales) et forward (pour le calcul des logits), l'évaluation de la qualité de l'image (IQA) avec le modèle peut être réalisé comme suit :
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User : Évaluez la qualité de l'image.n"
"##Assistant : La qualité de l'image est" ### Cette ligne peut être modifiée en fonction du comportement par défaut de MLLM.good_idx, Poor_idx = tokenizer(["good","poor"]).tolist()image = Image. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(image, prompt)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, Poor_idx]] / 100).softmax(0)[0]*Notez que vous pouvez modifier la deuxième ligne en fonction du format par défaut de votre modèle, par exemple pour Shikra, le "##Assistant : La qualité de l'image est" est modifié par "##Assistant : La réponse est". Ce n'est pas grave si votre MLLM répond d'abord "Ok, j'aimerais vous aider ! La qualité de l'image est", remplacez simplement ceci dans la ligne 2 de l'invite.
Nous proposons en outre une implémentation complète d'IDEFICS sur IQA. Voir l'exemple sur la façon d'exécuter IQA avec ce MLLM. D'autres MLLM peuvent également être modifiés de la même manière pour être utilisés dans IQA.
Nous avons préparé des scores d'opinion humaine (MOS) au format JSON pour les sept bases de données IQA telles qu'évaluées dans notre benchmark.
Veuillez consulter IQA_databases pour plus de détails.
Déplacé vers les classements. Veuillez cliquer pour voir les détails.
Veuillez contacter l'un des premiers auteurs de cet article pour toute question.
Haoning Wu, [email protected] , @teowu
Zicheng Zhang, [email protected] , @zzc-1998
Erli Zhang, [email protected] , @ZhangErliCarl
Si vous trouvez notre travail intéressant, n’hésitez pas à citer notre article :
@inproceedings{wu2024qbench,author = {Wu, Haoning et Zhang, Zicheng et Zhang, Erli et Chen, Chaofeng et Liao, Liang et Wang, Annan et Li, Chunyi et Sun, Wenxiu et Yan, Qiong et Zhai, Guangtao et Lin, Weisi},title = {Q-Bench : une référence pour les modèles de base à usage général sur la vision de bas niveau},booktitle = {ICLR},year = {2024}} 

