LLM PuzzleTest
1.0.0
PuzzleVQA, notre nouvel ensemble de données révèle de sérieux défis des LLM multimodaux dans la compréhension de modèles abstraits simples. Papier | Site web
Nous publions AlgoPuzzleVQA, un ensemble de données nouveau et stimulant pour le raisonnement multimodal ! Bientôt, nous publierons davantage d’ensembles de données de puzzle multimodaux. Restez à l'écoute! Papier | Site web
Nous sommes ravis d'annoncer la sortie de deux nouveaux ensembles de données VQA centrés sur les énigmes :
Les performances des MLLM sur les deux ensembles de données sont particulièrement déficientes, soulignant le besoin urgent d'améliorations substantielles de leurs capacités de raisonnement multimodal.
Les grands modèles multimodaux étendent les capacités impressionnantes des grands modèles de langage en intégrant des capacités de compréhension multimodales. Cependant, il n’est pas clair comment ils peuvent imiter l’intelligence générale et la capacité de raisonnement des humains. Comme la reconnaissance de modèles et l’abstraction de concepts sont essentielles à l’intelligence générale, nous présentons PuzzleVQA, une collection de puzzles basés sur des modèles abstraits. Avec cet ensemble de données, nous évaluons de grands modèles multimodaux avec des motifs abstraits basés sur des concepts fondamentaux, notamment les couleurs, les nombres, les tailles et les formes. Grâce à nos expériences sur de grands modèles multimodaux de pointe, nous constatons qu’ils ne sont pas capables de bien se généraliser à de simples modèles abstraits. Notamment, même GPT-4V ne peut pas résoudre plus de la moitié des énigmes. Pour diagnostiquer les défis de raisonnement dans les grands modèles multimodaux, nous guidons progressivement les modèles avec nos explications de raisonnement de vérité terrain pour la perception visuelle, le raisonnement inductif et le raisonnement déductif. Notre analyse systématique révèle que les principaux goulots d’étranglement du GPT-4V sont une perception visuelle plus faible et des capacités de raisonnement inductif. Grâce à ce travail, nous espérons faire la lumière sur les limites des grands modèles multimodaux et sur la manière dont ils pourront mieux imiter les processus cognitifs humains à l’avenir.
PuzzleVQA est disponible ici et également sur Huggingface.
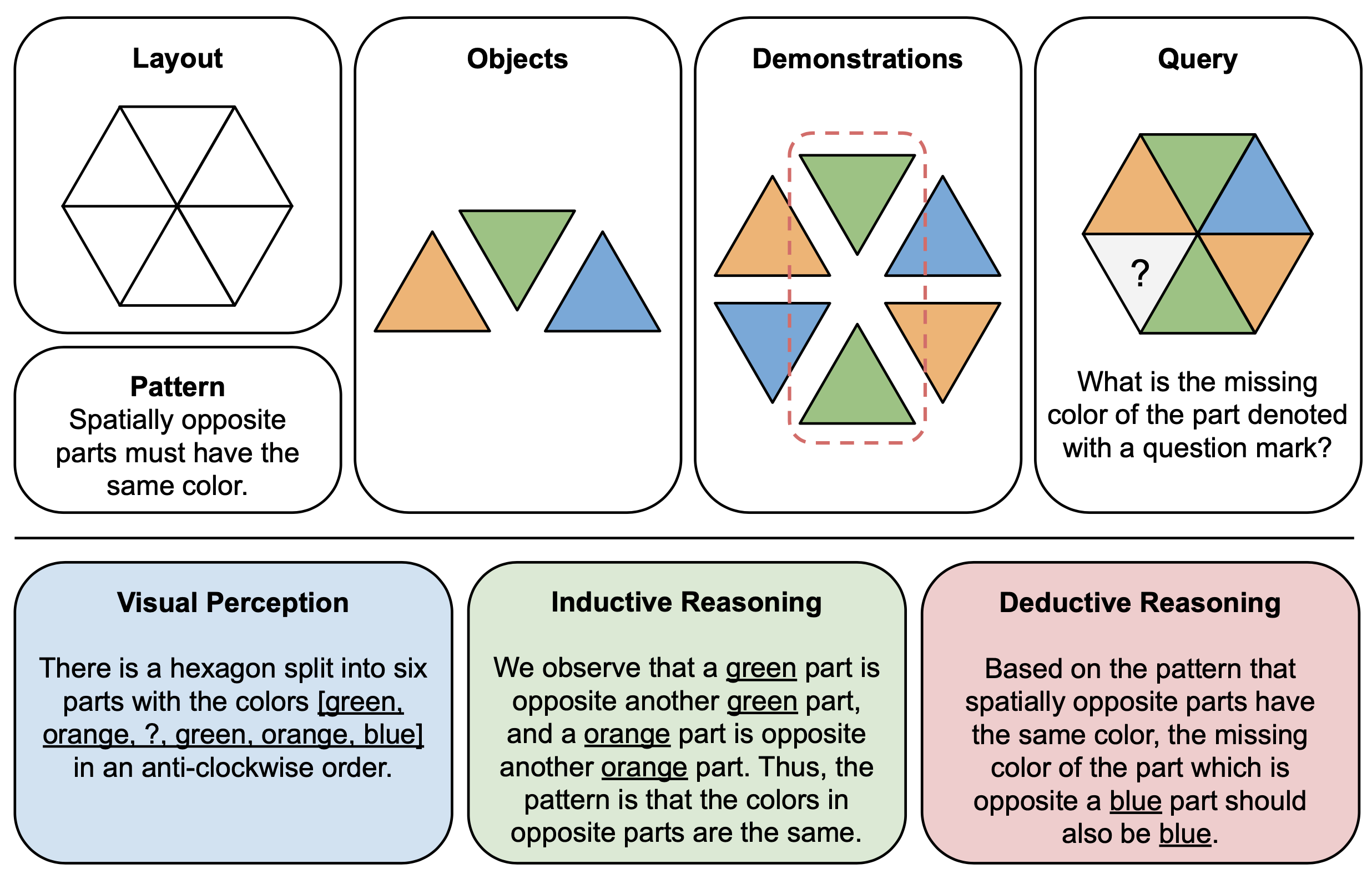
La figure ci-dessous montre un exemple de question qui implique le concept de couleur dans PuzzleVQA et une réponse incorrecte de GPT-4V. Il y a généralement trois étapes qui peuvent être observées dans le processus de résolution : la perception visuelle (bleu), le raisonnement inductif (vert) et le raisonnement déductif (rouge). Ici, la perception visuelle était incomplète, provoquant une erreur lors du raisonnement déductif.

La figure ci-dessous montre un exemple d'illustration des composants (en haut) et des explications de raisonnement (en bas) pour les puzzles abstraits dans PuzzleVQA. Pour construire chaque instance de puzzle, nous définissons d'abord la disposition et le modèle d'un modèle multimodal, puis remplissons le modèle avec des objets appropriés qui démontrent le modèle sous-jacent. Pour des raisons d'interprétabilité, nous construisons également des explications de raisonnement de vérité terrain pour interpréter le puzzle et expliquer les étapes générales de la solution.
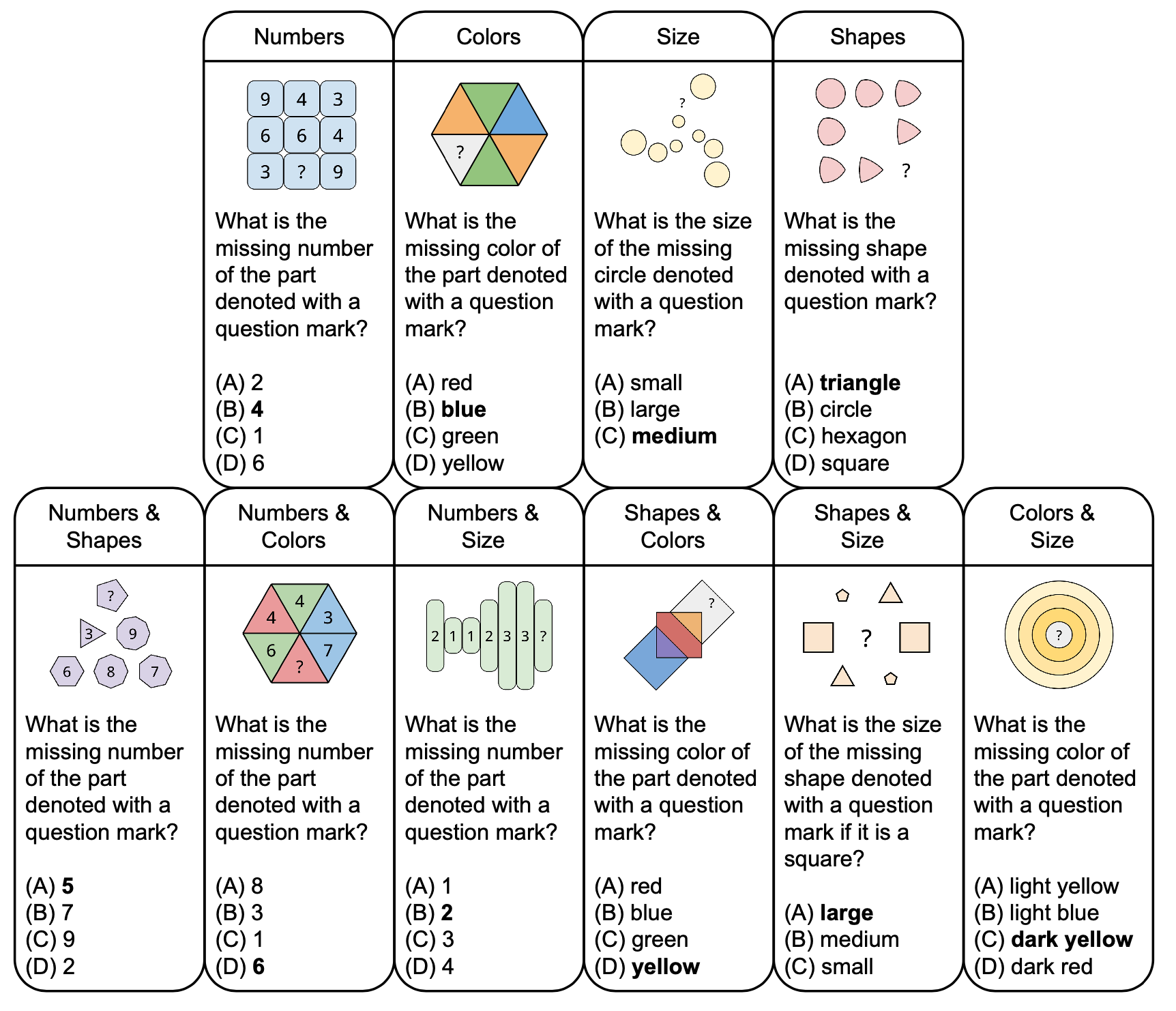
La figure ci-dessous montre la taxonomie des puzzles abstraits dans PuzzleVQA avec des exemples de questions, basées sur des concepts fondamentaux tels que les couleurs et la taille. Pour accroître la diversité, nous concevons des puzzles à un ou deux concepts.
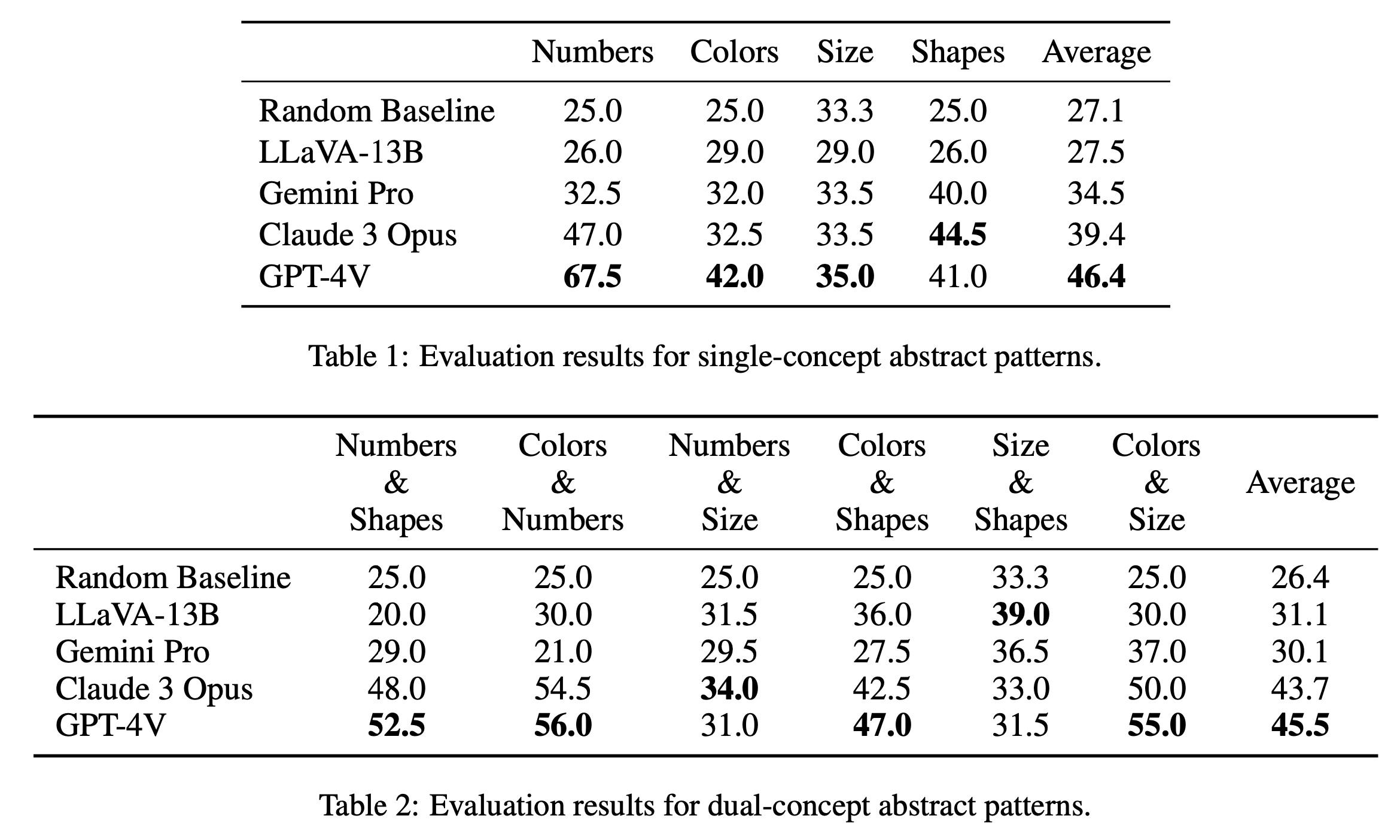
Nous rapportons les principaux résultats d'évaluation sur les puzzles à concept unique et à double concept dans le tableau 1 et le tableau 2 respectivement. Les résultats de l'évaluation des énigmes à concept unique, comme indiqué dans le tableau 1, révèlent des différences notables de performances entre les modèles open source et fermé. GPT-4V se démarque avec le score moyen le plus élevé de 46,4, démontrant un raisonnement abstrait supérieur sur des énigmes à concept unique telles que les nombres, les couleurs et la taille. Il excelle particulièrement dans la catégorie « Nombres » avec un score de 67,5, dépassant de loin les autres modèles, ce qui peut s'expliquer par son avantage dans les tâches de raisonnement mathématique (Yang et al., 2023). Claude 3 Opus suit avec une moyenne globale de 39,4, démontrant sa solidité dans la catégorie « Formes » avec une note maximale de 44,5. Les autres modèles, dont Gemini Pro et LLaVA-13B, sont à la traîne avec des moyennes de 34,5 et 27,5 respectivement, avec des performances similaires à la ligne de base aléatoire dans plusieurs catégories.
Dans l'évaluation des puzzles à double concept, comme le montre le tableau 2, GPT-4V se démarque à nouveau avec le score moyen le plus élevé de 45,5. Il s'est particulièrement bien comporté dans des catégories telles que « Couleurs et chiffres » et « Couleurs et taille » avec un score de 56,0 et 55,0 respectivement. Claude 3 Opus suit de près avec une moyenne de 43,7, affichant une belle performance dans « Nombres & Tailles » avec la note la plus élevée de 34,0. Il est intéressant de noter que LLaVA-13B, malgré sa moyenne globale inférieure de 31,1, obtient le score le plus élevé dans la catégorie « Taille et formes » avec 39,0. Gemini Pro, en revanche, affiche des performances plus équilibrées dans toutes les catégories, mais avec une moyenne globale légèrement inférieure de 30,1. Dans l’ensemble, nous constatons que les modèles fonctionnent en moyenne de manière similaire pour les modèles à un seul concept et à deux concepts, ce qui suggère qu’ils sont capables de relier plusieurs concepts tels que les couleurs et les nombres.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Nous introduisons la nouvelle tâche de résolution d’énigmes multimodales, encadrée dans le contexte de la réponse visuelle aux questions. Nous présentons un nouvel ensemble de données, AlgoPuzzleVQA, conçu pour contester et évaluer les capacités des modèles de langage multimodaux à résoudre des énigmes algorithmiques qui nécessitent à la fois une compréhension visuelle, une compréhension du langage et un raisonnement algorithmique complexe. Nous créons des énigmes pour englober un large éventail de sujets mathématiques et algorithmiques tels que la logique booléenne, la combinatoire, la théorie des graphes, l'optimisation, la recherche, etc., dans le but d'évaluer l'écart entre l'interprétation visuelle des données et les compétences algorithmiques en résolution de problèmes. L'ensemble de données est généré automatiquement à partir de code créé par des humains. Tous nos puzzles ont des solutions exactes qui peuvent être trouvées à partir de l'algorithme sans calculs humains fastidieux. Cela garantit que notre ensemble de données peut être agrandi arbitrairement en termes de complexité de raisonnement et de taille de l'ensemble de données. Notre enquête révèle que les grands modèles de langage (LLM) tels que GPT4V et Gemini présentent des performances limitées dans les tâches de résolution d'énigmes. Nous constatons que leurs performances sont presque aléatoires dans une configuration de questions-réponses à choix multiples pour un nombre important d’énigmes. Les résultats mettent l’accent sur les défis liés à l’intégration des connaissances visuelles, linguistiques et algorithmiques pour résoudre des problèmes de raisonnement complexes.
PuzzleVQA est disponible ici et également sur Huggingface.
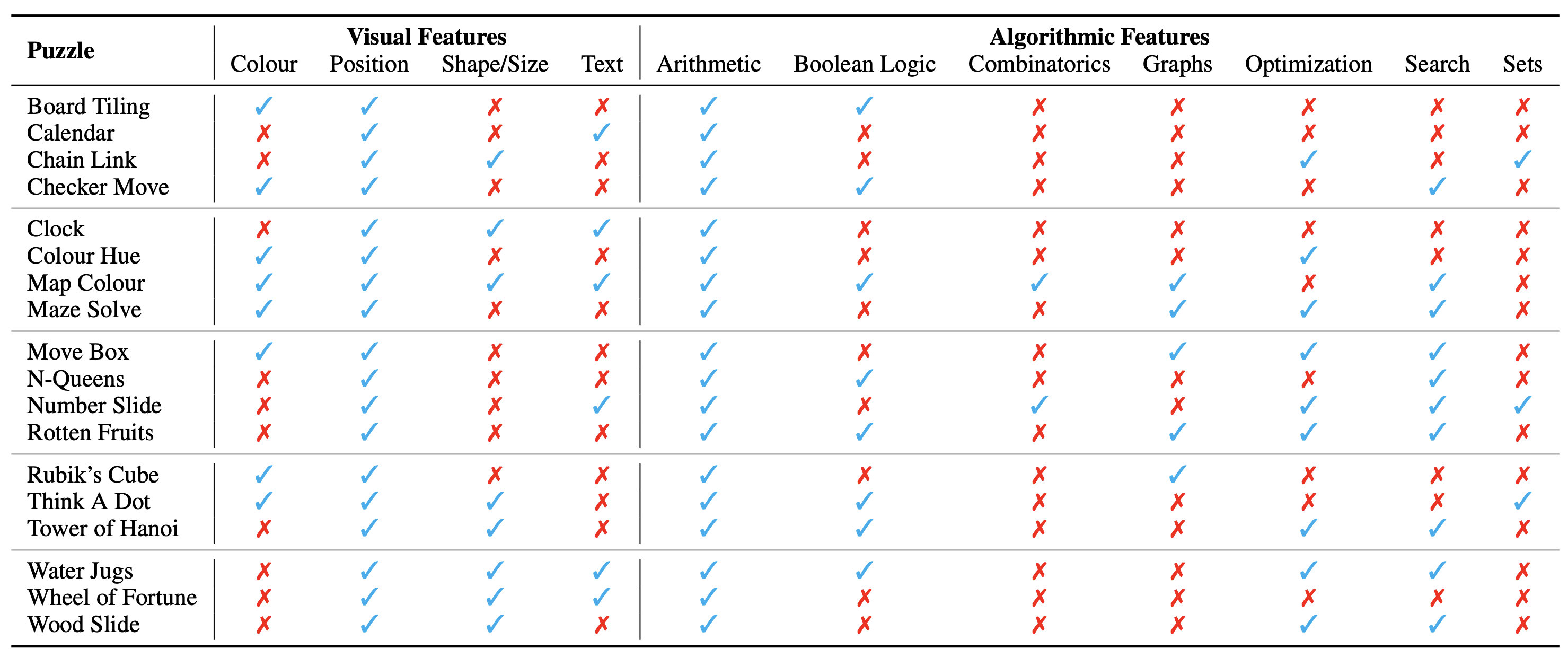
La configuration du puzzle/problème est présentée sous forme d'image, qui constitue son contexte visuel. Nous identifions les aspects fondamentaux suivants du contexte visuel qui influencent la nature des énigmes :

Nous identifions également les concepts algorithmiques requis pour résoudre les énigmes, c'est-à-dire pour répondre aux questions des instances de puzzle. Ils sont les suivants :

Les catégories algorithmiques ne s’excluent pas mutuellement, car nous devons utiliser deux catégories ou plus pour obtenir la réponse à la plupart des énigmes.
L'ensemble de données est disponible ici dans ces formats. Nous avons créé un total de 18 puzzles différents couvrant divers sujets algorithmiques et mathématiques. Beaucoup de ces puzzles sont populaires dans divers contextes récréatifs ou académiques.
Au total, nous disposons de 1 800 instances provenant des 18 puzzles différents. Ces instances sont analogues aux différents cas de test du puzzle, c'est-à-dire qu'elles ont différentes combinaisons d'entrées, états initiaux et objectifs, etc. Pour résoudre de manière fiable toutes les instances, il faudrait trouver l'algorithme exact à utiliser, puis l'appliquer avec précision. Cela s'apparente à la façon dont nous vérifions l'exactitude d'un programme informatique visant à résoudre une tâche particulière à travers un large éventail de cas de test.
Nous considérons actuellement l’ensemble de données complet comme une référence uniquement pour l’évaluation . Les exemples détaillés de tous les puzzles sont présentés ici.
Les instructions pour générer l’ensemble de données peuvent être trouvées ici. Le nombre d'instances et la difficulté des énigmes peuvent être arbitrairement adaptés à n'importe quelle taille ou niveau souhaité.
La catégorisation ontologique des énigmes est la suivante :
La configuration expérimentale et les scripts se trouvent dans le répertoire AlgoPuzzleVQA.
Veuillez envisager de citer l'article suivant si vous avez trouvé notre travail utile :
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

