AMchat
1.0.0
?CâlinVisage |
[2024.08.09] Nous avons publié le modèle de quantification Q8_0 AMchat-q8_0.gguf.
[2024.06.23] Mise au point du modèle InternLM2-Math-Plus-20B.
[2024.06.22] Ajustement du modèle InternLM2-Math-Plus-1.8B, ensemble de données open source à petite échelle.
[2024.06.21] Mise à jour du README, réglage fin du modèle InternLM2-Math-Plus-7B.
[2024.03.24] Top 12 du Défi Puyuan Large Model Series 2024 (Concours de printemps), Prix de l'innovation et de la créativité.
[2024.03.14] Le modèle est téléchargé sur HuggingFace.
[2024.03.08] README amélioré, ajout d'un catalogue et d'un parcours technique. Ajout de README_en-US.md.
[2024.02.06] Le déploiement Docker est pris en charge.
[2024.02.01] La première version d'AMchat est déployée en ligne https://openxlab.org.cn/apps/detail/youngdon/AMchat
Téléchargement du modèle de référence.
pip install modelscope from modelscope . hub . snapshot_download import snapshot_download
model_dir = snapshot_download ( 'yondong/AMchat' , cache_dir = './' )Voir modèle de téléchargement.
pip install openxlab from openxlab . model import download
download ( model_repo = 'youngdon/AMchat' ,
model_name = 'AMchat' , output = './' )git clone https://github.com/AXYZdong/AMchat.git
python start.pydocker run -t -i --rm --gpus all -p 8501:8501 guidonsdocker/amchat:latest bash start.shgit clone https://github.com/AXYZdong/AMchat.git
cd AMchatconda env create -f environment.yml
conda activate AMchat
pip install xtuner # 列出所有内置配置
xtuner list-cfg
mkdir -p /root/math/data
mkdir /root/math/config && cd /root/math/config
xtuner copy-cfg internlm2_chat_7b_qlora_oasst1_e3 .mkdir -p /root/math/model download.py
import torch
from modelscope import snapshot_download , AutoModel , AutoTokenizer
import os
model_dir = snapshot_download ( 'Shanghai_AI_Laboratory/internlm2-math-7b' , cache_dir = '/root/math/model' )Un fichier de configuration affiné a été fourni dans le dossier
configde l'entrepôt. Vous pouvez vous référer àinternlm_chat_7b_qlora_oasst1_e3_copy.py. Il peut être utilisé directement, veuillez faire attention à modifier les chemins depretrained_model_name_or_pathetdata_path.
cd /root/math/config
vim internlm_chat_7b_qlora_oasst1_e3_copy.py # 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm2-math-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './data'xtuner train /root/math/config/internlm2_chat_7b_qlora_oasst1_e3_copy.pymkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_chat_7b_qlora_oasst1_e3_copy.py
./work_dirs/internlm2_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
./hf # 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/math/model/Shanghai_AI_Laboratory/internlm2-math-7b
# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/math/config/hf
# 最终Merge后的参数存放的位置
mkdir /root/math/config/work_dirs/hf_merge
export SAVE_PATH=/root/math/config/work_dirs/hf_merge
# 执行参数Merge
xtuner convert merge
$NAME_OR_PATH_TO_LLM
$NAME_OR_PATH_TO_ADAPTER
$SAVE_PATH
--max-shard-size 2GBstreamlit run web_demo.py --server.address=0.0.0.0 --server.port 7860Il vous suffit de Fork ce référentiel, puis de créer un nouveau projet sur OpenXLab, d'associer le référentiel Fork au nouveau projet et vous pouvez déployer AMchat sur OpenXLab.

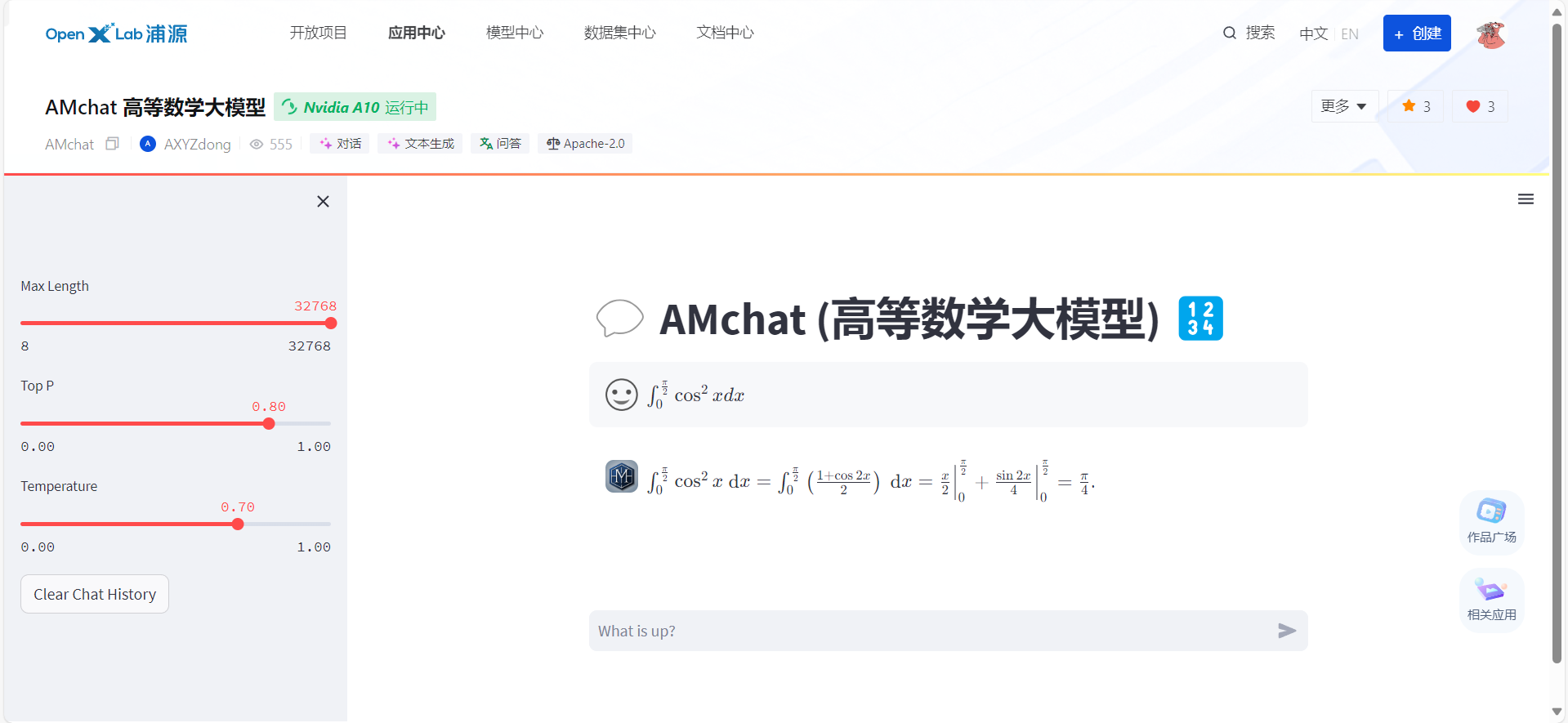

pip install -U lmdeployturbomind--dst-path : vous pouvez spécifier l'emplacement de stockage du modèle converti.
lmdeploy convert internlm2-chat-7b 要转化的模型地址 --dst-path 转换后的模型地址lmdeploy chat turbomind 转换后的turbomind模型地址git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zippython run.py
--datasets math_gen
--hf-path 模型地址
--tokenizer-path tokenizer地址
--tokenizer-kwargs padding_side= ' left ' truncation= ' left ' trust_remote_code=True
--model-kwargs device_map= ' auto ' trust_remote_code=True
--max-seq-len 2048
--max-out-len 16
--batch-size 2
--num-gpus 1
--debugW4 lmdeploy lite auto_awq 要量化的模型地址 --work-dir 量化后的模型地址TurbMind lmdeploy convert internlm2-chat-7b 量化后的模型地址 --model-format awq --group-size 128 --dst-path 转换后的模型地址config d'évaluation from mmengine . config import read_base
from opencompass . models . turbomind import TurboMindModel
with read_base ():
# choose a list of datasets
from . datasets . ceval . ceval_gen import ceval_datasets
# and output the results in a choosen format
# from .summarizers.medium import summarizer
datasets = [ * ceval_datasets ]
internlm2_chat_7b = dict (
type = TurboMindModel ,
abbr = 'internlm2-chat-7b-turbomind' ,
path = '转换后的模型地址' ,
engine_config = dict ( session_len = 512 ,
max_batch_size = 2 ,
rope_scaling_factor = 1.0 ),
gen_config = dict ( top_k = 1 ,
top_p = 0.8 ,
temperature = 1.0 ,
max_new_tokens = 100 ),
max_out_len = 100 ,
max_seq_len = 512 ,
batch_size = 2 ,
concurrency = 1 ,
# meta_template=internlm_meta_template,
run_cfg = dict ( num_gpus = 1 , num_procs = 1 ),
)
models = [ internlm2_chat_7b ]python run.py configs/eval_turbomind.py -w 指定结果保存路径TurbMind lmdeploy convert internlm2-chat-7b 模型路径 --dst-path 转换后模型路径 # 计算
lmdeploy lite calibrate 模型路径 --calib-dataset ' ptb ' --calib-samples 128 --calib-seqlen 2048 --work-dir 参数保存路径
# 获取量化参数
lmdeploy lite kv_qparams 参数保存路径 转换后模型路径/triton_models/weights/ --num-tp 1quant_policy par 4 et modifiez le chemin dans la config ci-dessuspython run.py configs/eval_turbomind.py -w 结果保存路径Merci au Laboratoire d'intelligence artificielle de Shanghai pour avoir organisé l'activité d'apprentissage du camp pratique Scholar Puyu ~
Merci à OpenXLab pour son support en puissance de calcul pour le déploiement de projets~
Merci à Puyu Assistant pour son soutien au projet~
Merci au Laboratoire d'intelligence artificielle de Shanghai pour le lancement du camp pratique Scholar·Puyu Large Model, qui fournit de précieux conseils techniques et un puissant support de puissance de calcul pour notre projet !
Tutoriel InternLM , InternStudio , xtuner , InternLM-Math
@misc { 2024AMchat ,
title = { AMchat: A large language model integrating advanced math concepts, exercises, and solutions } ,
author = { AMchat Contributors } ,
howpublished = { url{https://github.com/AXYZdong/AMchat} } ,
year = { 2024 }
}Ce projet adopte la licence open source Apache License 2.0. Veuillez respecter les licences des modèles et des ensembles de données utilisés.


