lightllm
1.0.0
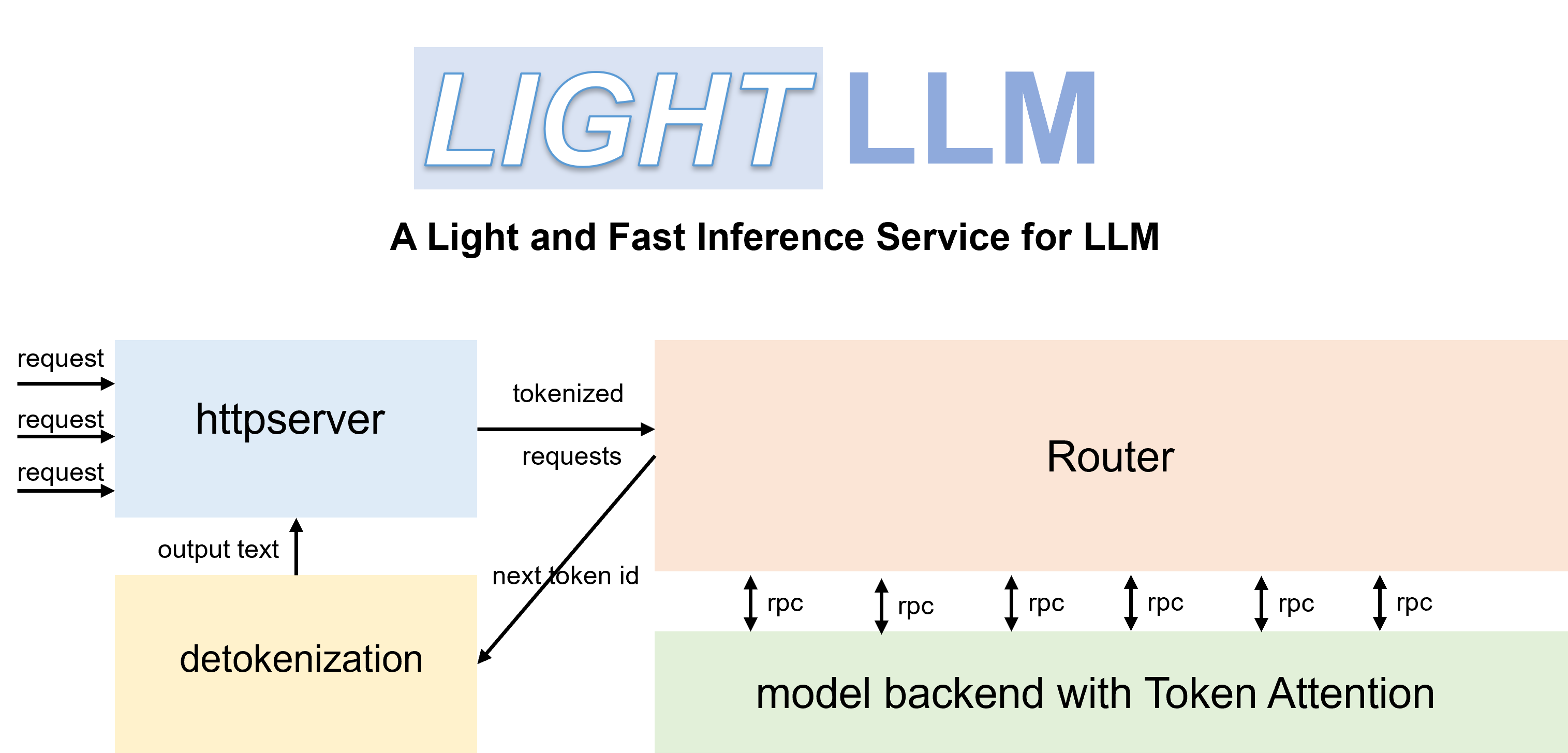
LightLLM est un framework d'inférence et de service LLM (Large Language Model) basé sur Python, remarquable par sa conception légère, son évolutivité facile et ses performances à grande vitesse. LightLLM exploite les atouts de nombreuses implémentations open source réputées, notamment, mais sans s'y limiter, FasterTransformer, TGI, vLLM et FlashAttention.
Documents en anglais | 中文文档
Lorsque vous démarrez Qwen-7b, vous devez définir le paramètre '--eos_id 151643 --trust_remote_code'.
ChatGLM2 doit définir le paramètre '--trust_remote_code'.
InternLM doit définir le paramètre '--trust_remote_code'.
InternVL-Chat(Phi3) doit définir le paramètre '--eos_id 32007 --trust_remote_code'.
InternVL-Chat (InternLM2) doit définir le paramètre '--eos_id 92542 --trust_remote_code'.
Qwen2-VL-7b doit définir le paramètre « --eos_id 151645 --trust_remote_code » et utiliser « pip install git+https://github.com/huggingface/transformers » pour mettre à niveau vers la dernière version.
Stablelm doit définir le paramètre '--trust_remote_code'.
Phi-3 ne prend en charge que Mini et Small.
DeepSeek-V2-Lite et DeepSeek-V2 doivent définir le paramètre '--data_type bfloat16'
Le code a été testé avec Pytorch>=1.3, CUDA 11.8 et Python 3.9. Pour installer les dépendances nécessaires, veuillez vous référer au fichierRequirements.txt fourni et suivez les instructions comme
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5Vous pouvez utiliser le conteneur Docker officiel pour exécuter le modèle plus facilement. Pour ce faire, suivez ces étapes :
Extrayez le conteneur du registre de conteneurs GitHub :
docker pull ghcr.io/modeltc/lightllm:mainExécutez le conteneur avec la prise en charge du GPU et le mappage des ports :
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashAlternativement, vous pouvez créer le conteneur vous-même :
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashVous pouvez également utiliser un script d'assistance pour lancer à la fois le conteneur et le serveur :
python tools/quick_launch_docker.py --help Remarque : Si vous utilisez plusieurs GPU, vous devrez peut-être augmenter la taille de la mémoire partagée en ajoutant --shm-size à la commande docker run .
python setup.py installLe code a été testé sur une gamme de GPU, notamment V100, A100, A800, 4090 et H800. Si vous exécutez le code sur A100, A800, etc., nous vous recommandons d'utiliser triton==3.0.0.
pip install triton==3.0.0 --no-depsSi vous exécutez le code sur H800 ou V100., vous pouvez essayer triton-nightly pour obtenir de meilleures performances.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsAvec des routeurs efficaces et TokenAttention, LightLLM peut être déployé en tant que service et atteindre des performances de débit de pointe.
Lancez le serveur :
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 Le paramètre max_total_token_num est influencé par la mémoire GPU de l'environnement de déploiement. Vous pouvez également spécifier --mem_faction pour qu'il soit calculé automatiquement.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9Pour lancer une requête dans le shell :
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'Pour interroger depuis Python :
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )Paramètres de lancement supplémentaires :
--enable_multimodal,--cache_capacity, plus grand--cache_capacitynécessiteshm-sizeplus grande
Prise en charge
--tp > 1, lorsquetp > 1, modèle visuel exécuté sur le GPU 0
La balise d'image spéciale pour Qwen-VL est
<img></img>(<image>pour Llava), la longueur desdata["multimodal_params"]["images"]doit être la même que le nombre de balises, le nombre peut être 0, 1, 2, ...
Format des images d'entrée : liste de dict comme
{'type': 'url'/'base64', 'data': xxx}
Nous avons comparé les performances de service de LightLLM et vLLM==0.1.2 sur LLaMA-7B en utilisant un A800 avec 80G de mémoire GPU.
Pour commencer, préparez les données comme suit :
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonLancez le service :
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoÉvaluation:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200Les résultats de la comparaison des performances sont présentés ci-dessous :
| vLLM | LumièreLLM |
|---|---|
| Temps total : 361,79 s Débit : 5,53 requêtes/s | Temps total : 188,85 s Débit : 10,59 requêtes/s |
Pour le débogage, nous proposons des scripts de tests de performances statiques pour différents modèles. Par exemple, vous pouvez évaluer les performances d'inférence du modèle LLaMA en
cd test/model
python test_llama.pypip install protobuf==3.20.0 .error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... Si vous avez un projet qui doit être incorporé, veuillez nous contacter par e-mail ou créer une pull request.
Une fois que vous avez installé lightllm et lazyllm , vous pouvez utiliser le code suivant pour créer votre propre chatbot :
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()Documents : https://lazyllm.readthedocs.io/
Pour plus d’informations et de discussion, rejoignez notre serveur Discord.
Ce référentiel est publié sous la licence Apache-2.0.
Nous avons beaucoup appris des projets suivants lors du développement de LightLLM.


