RWKV LM
v5
Page d'accueil du RWKV : https://www.rwkv.com
Papier RWKV-5/6 Eagle/Finch : https://arxiv.org/abs/2404.05892
Super RWKV dans Vision : https://github.com/Yaziwel/Awesome-RWKV-in-Vision
Démo RWKV-6 3B : https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Démo RWKV-6 7B : https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
Code de démonstration RWKV-6 en mode GPT (avec commentaires et explications) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
Démo du mode RNN RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
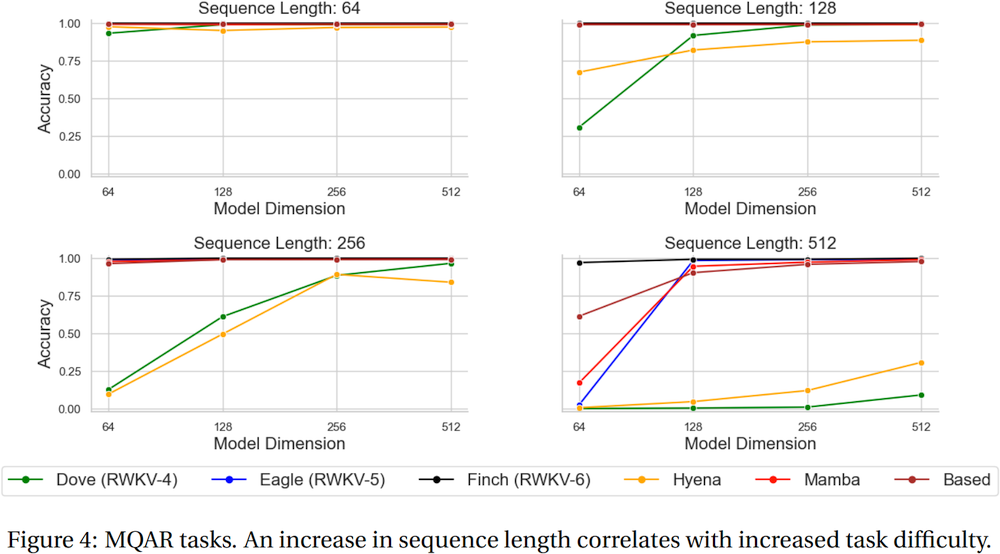
Pour référence, utilisez python 3.10+, torch 2.5+, cuda 12.5+, dernière vitesse profonde, mais gardez pytorch-lightning==1.9.5
Entraînez RWKV-6 : utilisez /RWKV-v5/ et utilisez --my_testing "x060" dans demo-training-prepare.sh et demo-training-run.sh
Entraînez RWKV-7 : utilisez /RWKV-v5/ et utilisez --my_testing "x070" dans demo-training-prepare.sh et demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
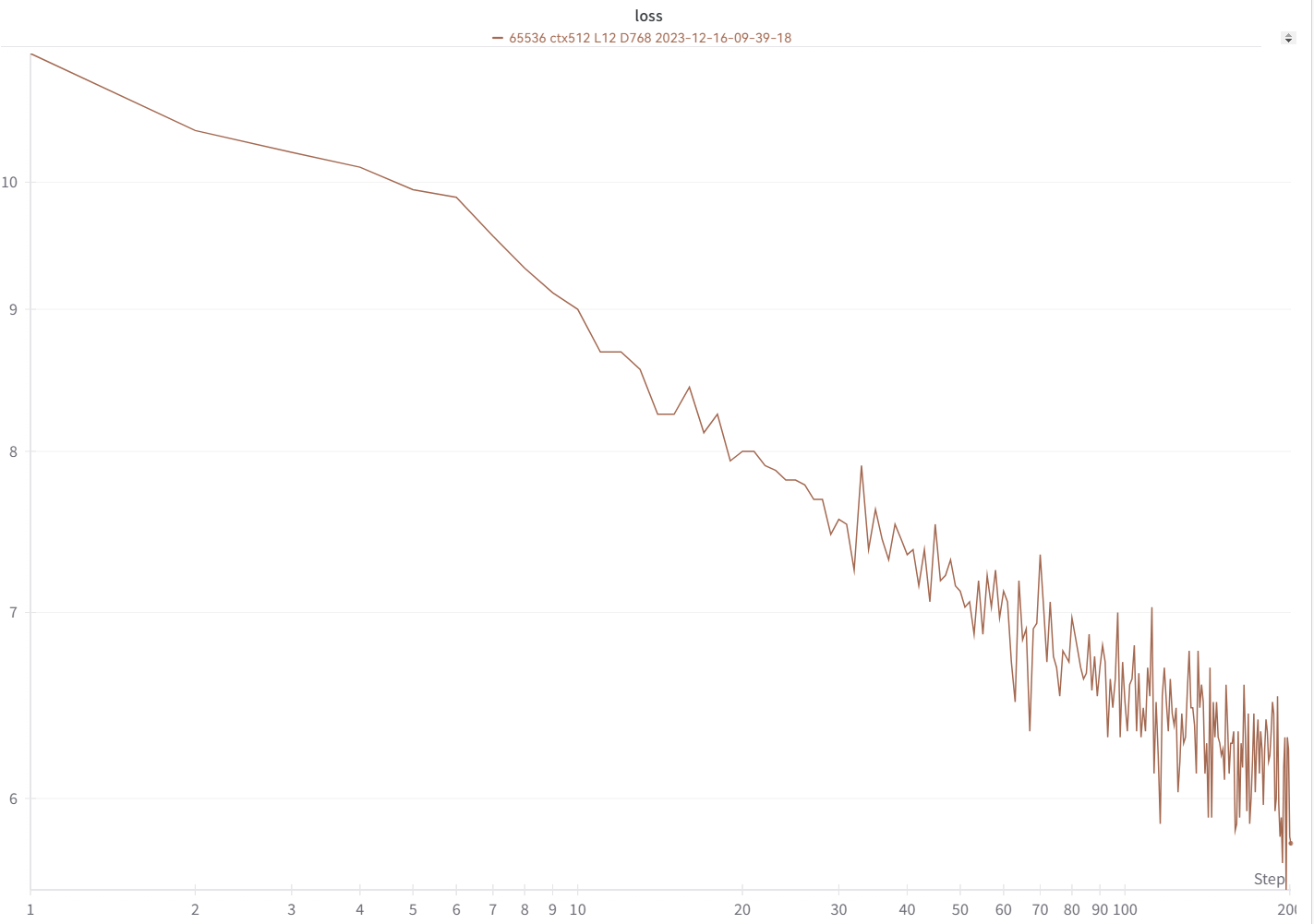
Votre courbe de perte devrait ressembler presque exactement à celle-ci, avec les mêmes hauts et bas (si vous utilisez le même bsz et la même configuration) :
Vous pouvez exécuter votre modèle en utilisant https://pypi.org/project/rwkv/ (utilisez "rwkv_vocab_v20230424" au lieu de "20B_tokenizer.json")
Utilisez https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py pour préparer les données binidx à partir de jsonl et calculer "--my_exit_tokens" et "--magic_prime".
Tokeniseur de données volumineuses beaucoup plus rapide : https://github.com/cahya-wirawan/json2bin
L'"époque" dans train.py est "mini-époque" (pas la vraie époque. uniquement pour des raisons de commodité), et 1 mini-époque = 40320 * jetons ctx_len.
Par exemple, si votre binidx a 1498226207 jetons et ctxlen=4096, définissez "--my_exit_tokens 1498226207" (cela remplacera epoch_count), et ce sera 1498226207/(40320 * 4096) = 9,07 miniepochs. L'entraîneur se quittera automatiquement après les jetons "--my_exit_tokens". Définissez "--magic_prime" sur le plus grand 3n+2 premier plus petit que datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), qui est "--magic_prime 365759" dans ce cas.
simple : préparez SFT jsonl => répétez vos données SFT 3 ou 4 fois dans make_data.py. plus de répétition conduit à un surapprentissage.
avancé : répétez vos données SFT 3 ou 4 fois dans votre jsonl (notez que make_data.py mélangera tous les éléments jsonl) => ajoutez des données de base (telles que slimpajama) à votre jsonl => et répétez seulement 1 fois dans make_data.py.
Réparer les pics d'entraînement : voir la partie "Réparer les pics du RWKV-6" sur cette page.
Inférence simple pour RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Inférence simple pour RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Remarque : Dans [state = kv + w * state], tout doit être dans fp32 car w peut être très proche de 1. Nous pouvons donc conserver l'état et w dans fp32 et convertir kv en fp32.
lm_eval : https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
Démo de chat pour les développeurs : https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Conseils pour les petits modèles / petites données : lorsque j'entraîne des modèles musicaux RWKV, j'utilise des dimensions profondes et étroites (telles que L29-D512) et j'applique wd et dropout (telles que wd=2 dropout=0,02). Notez que l'abandon RWKV-LM est très efficace : utilisez 1/4 de votre valeur habituelle.
Utilisez le format .jsonl pour vos données (voir https://huggingface.co/BlinkDL/rwkv-5-world pour les formats).
Utilisez https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py pour le tokeniser à l'aide de World tokenizer dans binidx, adapté au réglage fin des modèles World.
Renommez le point de contrôle de base dans votre dossier modèle en rwkv-init.pth et modifiez les commandes d'entraînement pour utiliser --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 pour 7B.
0,1B = --n_layer 12 --n_embd 768 // 0,4B = --n_layer 24 --n_embd 1024 // 1,5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_layer 32 --n_embd 4096
Implémentation actuellement non optimisée, prend la même vram que SFT complet
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
utilisez rwkv 0.8.26+ pour charger automatiquement le "time_state" formé
Lorsque vous entraînez RWKV à partir de zéro, essayez mon initialisation pour obtenir de meilleures performances. Vérifiez generate_init_weight() de src/model.py :
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Si vous utilisez l'intégration positionnelle, il est peut-être préférable de supprimer block.0.ln0 et d'utiliser l'initialisation par défaut pour emb.weight au lieu de mon uniform_(a=-1e-4, b=1e-4) !!!
lors d'un entraînement à partir de zéro, ajoutez "k = k * torch.clamp(w, max=0).exp()" avant "RUN_CUDA_RWKV6(r, k, v, w, u)", et n'oubliez pas de modifier également votre code d'inférence . vous verrez une convergence plus rapide.
utilisez "--adam_eps 1e-18"
"--beta2 0.95" si vous voyez des pics
dans trainer.py, faites "lr = lr * (0,01 + 0,99 * trainer.global_step / w_step)" (à l'origine 0,2 + 0,8) et "--warmup_steps 20"
"--weight_decay 0.1" conduit à une meilleure perte finale si vous entraînez beaucoup de données. définissez lr_final sur 1/100 de lr_init en faisant cela.
RWKV est un RNN avec des performances LLM de niveau transformateur, qui peut également être directement entraîné comme un transformateur GPT (parallélisable). Et c'est 100% sans attention. Vous n'avez besoin que de l'état caché en position t pour calculer l'état en position t+1. Vous pouvez utiliser le mode "GPT" pour calculer rapidement l'état caché pour le mode "RNN".
Il combine donc le meilleur de RNN et du transformateur : excellentes performances, inférence rapide, sauvegarde de la VRAM, formation rapide, ctx_len "infini" et intégration de phrases gratuite (en utilisant l'état caché final).
Interface graphique de RWKV Runner https://github.com/josStorer/RWKV-Runner avec installation et API en un clic
Tous les derniers poids RWKV : https://huggingface.co/BlinkDL
Poids RWKV compatibles HF : https://huggingface.co/RWKV
Paquet pip RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (ne nécessite pas de noyau CUDA personnalisé pour s'entraîner, fonctionne pour n'importe quel GPU/CPU)
Twitter : https://twitter.com/BlinkDL_AI
Page d'accueil : https://www.rwkv.com
Projets RWKV communautaires sympas :
Tous (300+) projets RWKV : https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV Vision RWKV
https://github.com/feizc/Diffusion-RWKV Diffusion RWKV
https://github.com/cgisky1980/ai00_rwkv_server Inférence WebGPU la plus rapide (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv backend pour ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp CPU rapide/cuBLAS/CLBdernière inférence : int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Entraîneur Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Assistant numérique avec RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Inférence GPU rapide avec cuda/amd/vulkan
RWKV v6 en 250 lignes (avec tokenizer également) : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 en 250 lignes (avec tokenizer également) : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 en 150 lignes (modèle, inférence, génération de texte) : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
Préimpression RWKV v4 https://arxiv.org/abs/2305.13048
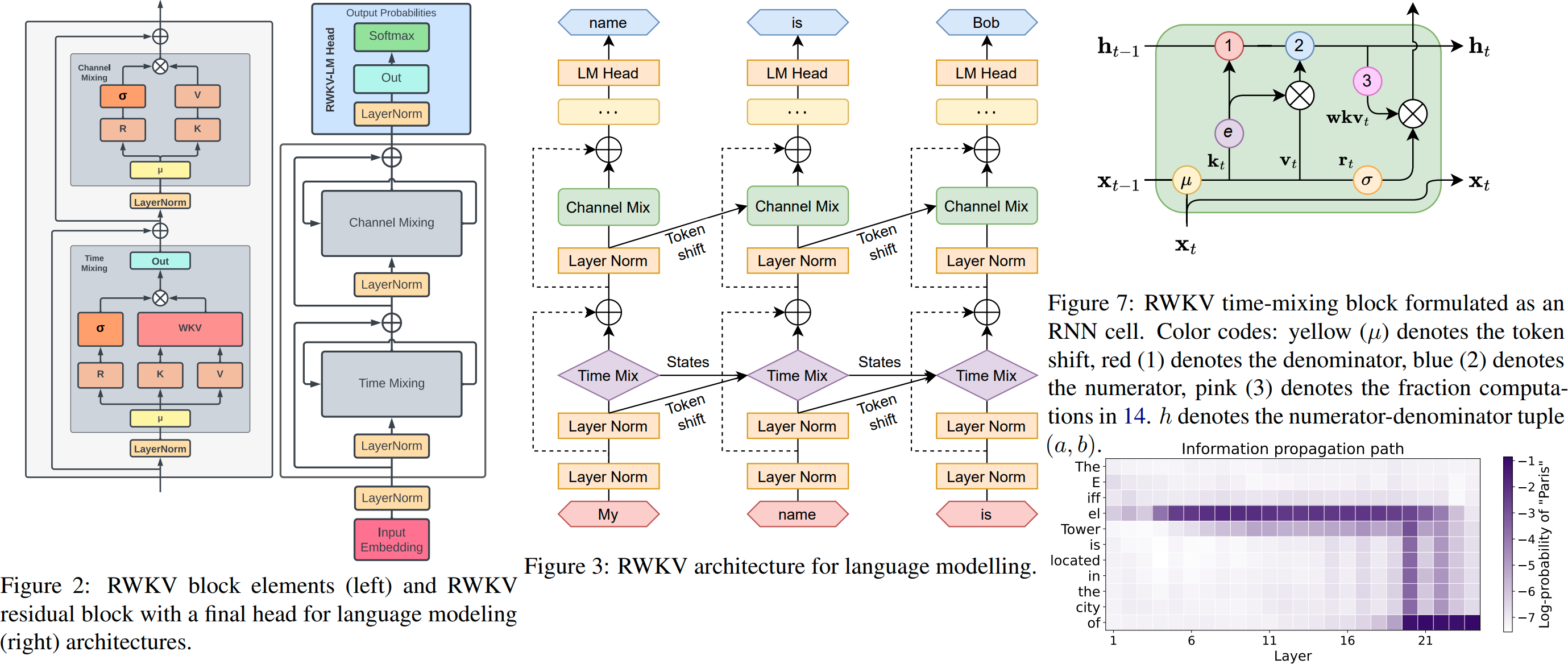
Introduction de RWKV v4, et en 100 lignes de numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
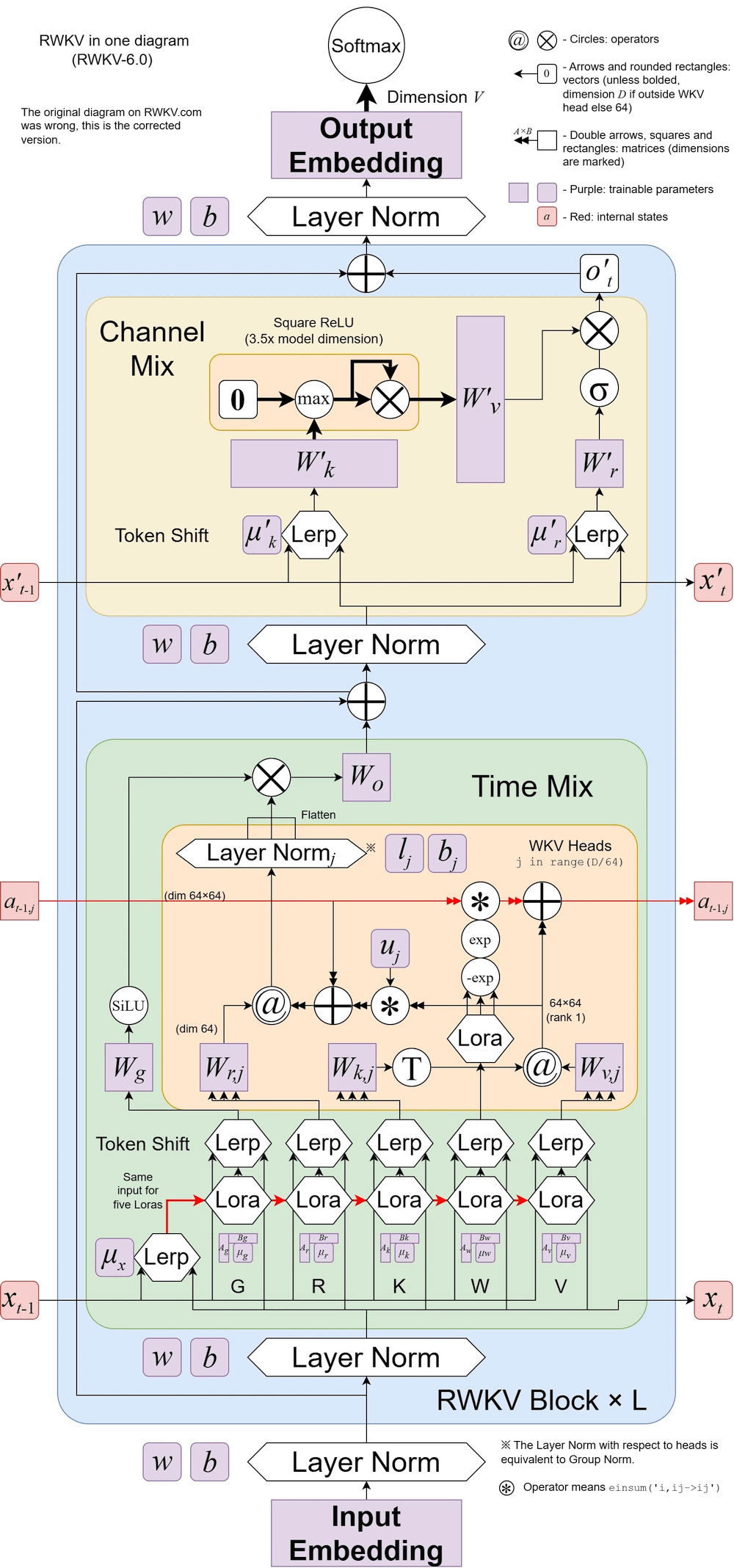
RWKV v6 illustré :
Un article sympa (Spiking Neural Network) utilisant RWKV : https://github.com/ridgerchu/SpikeGPT
Vous êtes invités à rejoindre le discord RWKV https://discord.gg/bDSBUMeFpc pour vous appuyer sur celui-ci. Nous avons maintenant beaucoup de calculs potentiels (A100 40G) (grâce à Stability et EleutherAI), donc si vous avez des idées intéressantes, je peux les exécuter.

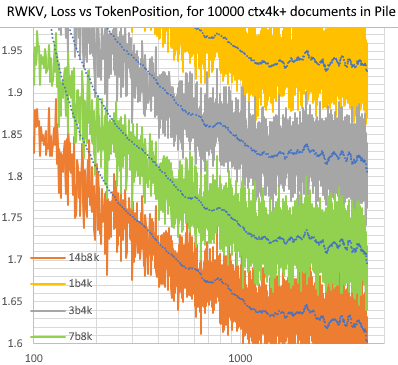
RWKV [perte vs position du jeton] pour 10 000 documents ctx4k+ dans Pile. RWKV 1B5-4k est généralement plat après ctx1500, mais 3B-4k, 7B-4k et 14B-4k ont quelques pentes, et elles s'améliorent. Cela démystifie l’ancienne vision selon laquelle les RNN ne peuvent pas modéliser de longues lentilles ctx. Nous pouvons prédire que le RWKV 100B sera génial, et le RWKV 1T est probablement tout ce dont vous avez besoin :)
ChatRWKV avec RWKV 14B ctx8192 :

Je pense que RNN est un meilleur candidat pour les modèles fondamentaux, car : (1) Il est plus convivial pour les ASIC (pas de cache kv). (2) C'est plus convivial pour RL. (3) Lorsque nous écrivons, notre cerveau ressemble davantage à RNN. (4) L'univers est également comme un RNN (en raison de la localité). Les transformateurs sont des modèles non locaux.
RWKV-3 1,5B sur A40 (tf32) = toujours 0,015 sec/jeton, testé à l'aide d'un simple code pytorch (pas de CUDA), utilisation du GPU 45 %, VRAM 7823M
GPT2-XL 1.3B sur A40 (tf32) = 0.032 sec/token (pour ctxlen 1000), testé en HF, utilisation GPU 45% également (intéressant), VRAM 9655M
Vitesse d'entraînement : (nouveau code d'entraînement) RWKV-4 14B BF16 ctxlen4096 = 114K tokens/s sur 8x8 A100 80G (ZERO2+CP). (ancien code de formation) RWKV-4 1,5B BF16 ctxlen1024 = 106K jetons/s sur 8xA100 40G.
Je fais aussi des expériences d'images (Par exemple : https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) et RWKV pourra faire de la diffusion txt2img :) Mon idée : image rgb 256x256 -> latents 32x32x13bit - > appliquer RWKV pour calculer la probabilité de transition pour chacune des grilles 32x32 -> faire comme si les grilles étaient indépendantes et "diffuses" en utilisant ces probabilités.
Entraînement fluide - pas de pics de perte ! (lr & bsz changent autour de 15G de jetons) 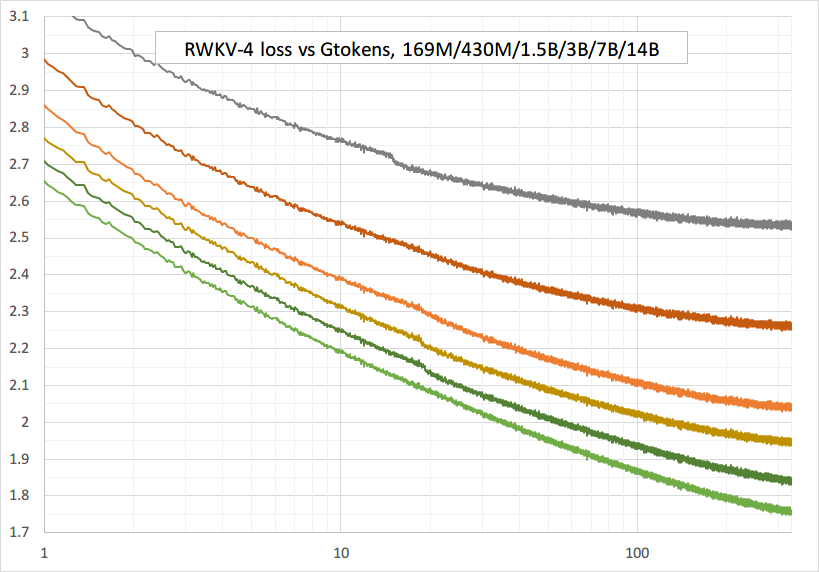
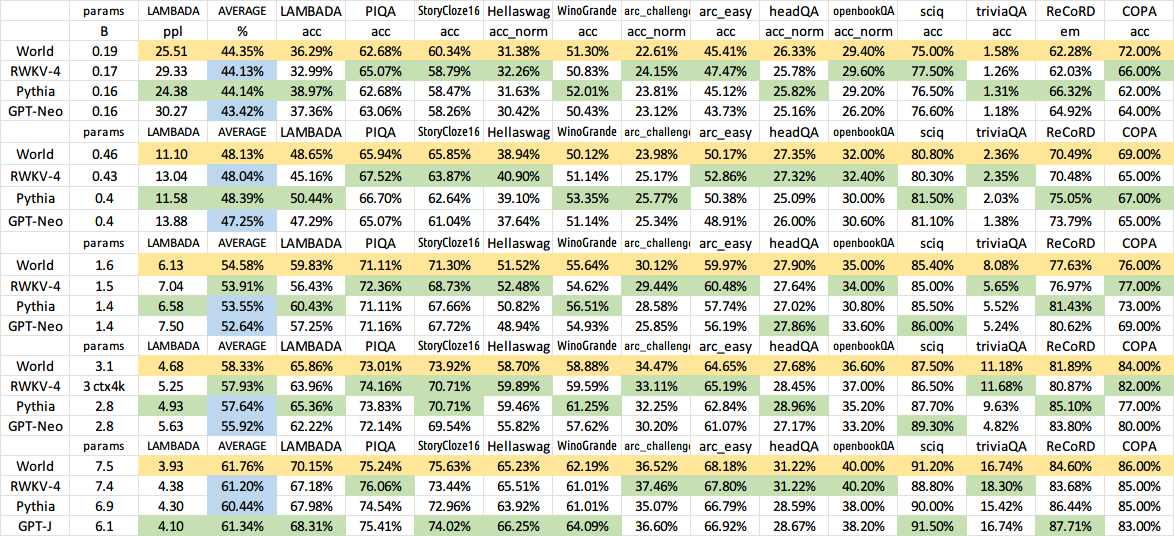
Tous les modèles formés seront open source. L'inférence est très rapide (uniquement des multiplications matrice-vecteur, pas de multiplications matrice-matrice) même sur les processeurs, vous pouvez donc même exécuter un LLM sur votre téléphone.
Comment ça marche : RWKV rassemble des informations sur un certain nombre de canaux, qui se désintègrent également à des vitesses différentes à mesure que vous passez au jeton suivant. C'est très simple une fois qu'on a compris.
RWKV est parallélisable car la décroissance temporelle de chaque canal est indépendante des données (et peut être entraînée) . Par exemple, dans RNN habituel, vous pouvez ajuster la décroissance temporelle d'un canal de, par exemple, 0,8 à 0,5 (ceux-ci sont appelés "portes"), tandis que dans RWKV, vous déplacez simplement les informations d'un canal W-0,8 vers un canal W-0,5. -canal pour obtenir le même effet. De plus, vous pouvez affiner RWKV en un RNN non parallélisable (vous pouvez ensuite utiliser les sorties des couches ultérieures du jeton précédent) si vous souhaitez des performances supplémentaires.

Voici quelques-unes de mes TODO. Travaillons ensemble :)
Intégration de HuggingFace (vérifiez huggingface/transformers#17230) et inférence optimisée CPU & iOS & Android & WASM & WebGL. RWKV est un RNN très convivial pour les appareils Edge. Rendons possible l'exécution d'un LLM sur votre téléphone.
Testez-le sur des tâches bidirectionnelles et MLM, ainsi que sur des jetons image, audio et vidéo. Je pense que RWKV peut prendre en charge Encoder-Decoder via ceci : pour chaque jeton de décodeur, utilisez un mélange appris de [état caché précédent du décodeur] et [état caché final de l'encodeur]. Par conséquent, tous les jetons du décodeur auront accès à la sortie du codeur.
Entraînez maintenant le RWKV-4a avec une seule petite attention supplémentaire (juste quelques lignes supplémentaires par rapport au RWKV-4) pour améliorer encore certaines tâches difficiles de tir nul (telles que LAMBADA) pour les modèles plus petits. Voir https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
Commentaires des utilisateurs :
Jusqu'à présent, j'ai joué avec le modèle basé sur les caractères sur notre ensemble de données de pré-entraînement relativement petit (environ 10 Go de texte), et les résultats sont extrêmement bons - des personnes similaires aux modèles prenant beaucoup, beaucoup plus de temps à former.
cher dieu, rwkv est rapide. Je suis passé à un autre onglet après avoir commencé à l'entraîner à partir de zéro et quand je suis revenu, il émettait des mots anglais et maori plausibles, je suis parti aller prendre du café au micro-ondes et quand je suis revenu, il produisait des phrases entièrement grammaticalement correctes.
Tweet de Sepp Hochreiter (merci !) : https://twitter.com/HochreiterSepp/status/1524270961314484227
Vous pouvez également me trouver (BlinkDL) sur le Discord EleutherAI : https://www.eleuther.ai/get-involved/
IMPORTANT : utilisez deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 et cuda 11.7.1 ou 11.7 (notez que torch2 + deepspeed a des bugs étranges et nuit aux performances du modèle)
Utilisez https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (dernier code, compatible avec la v4).
Voici une excellente invite pour tester les questions et réponses des LLM. Fonctionne pour n'importe quel modèle : (trouvé en minimisant les personnes ChatGPT pour RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisExécutez les modèles de pile RWKV-4 : téléchargez les modèles depuis https://huggingface.co/BlinkDL. Définissez TOKEN_MODE = 'pile' dans run.py et exécutez-le. C'est rapide même sur CPU (le mode par défaut).
Colab pour RWKV-4 Pile 1,5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Exécutez les modèles de pile RWKV-4 dans votre navigateur (et la version onnx) : voir ce numéro 7
Démo Web RWKV-4 : https://josephrocca.github.io/rwkv-v4-web/demo/ (remarque : uniquement un échantillonnage gourmand pour l'instant)
Pour l'ancien RWKV-2 : voir la version ici pour un modèle de 27 M de paramètres sur enwik8 avec 0,72 BPC(dev). Exécutez run.py sur https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. Vous pouvez même l'exécuter dans votre navigateur : https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (ceci utilise tf.js WASM mode monothread).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // torch 1.13.1+cu117
REMARQUE : ajoutez la perte de poids (0,1 ou 0,01) et l'abandon (0,1 ou 0,01) lors de l'entraînement sur une petite quantité de données. essayez x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) etc.
Entraîner RWKV-4 à partir de zéro : exécutez train.py, qui utilise par défaut l'ensemble de données enwik8 (décompressez https://data.deepai.org/enwik8.zip).
Vous entraînerez la version "GPT" car elle est parallézisable et plus rapide à entraîner. RWKV-4 peut extrapoler, donc la formation avec ctxLen 1024 peut fonctionner pour ctxLen de 2500+. Vous pouvez affiner le modèle avec un ctxLen plus long et il peut s'adapter rapidement à un ctxLens plus long.
Affiner les modèles de pile RWKV-4 : utilisez « prepare-data.py » dans https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 pour tokeniser .txt dans le train. données npy. Utilisez ensuite https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py pour l'entraîner.
Lisez le code d'inférence dans src/model.py et essayez d'utiliser l'état caché final (.xx .aa .bb) comme phrase fidèle intégrée pour d'autres tâches. Vous devriez probablement commencer par .xx et .aa/.bb (.aa divisé par .bb).
Colab pour affiner les modèles de pile RWKV-4 : https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Corpus volumineux : utilisez https://github.com/Abel2076/json2binidx_tool pour convertir .jsonl en .bin et .idx
L'exemple de format jsonl (une ligne pour chaque document) :
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
généré par un code comme celui-ci :
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Formation infinie ctxlen (WIP) : https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Considérez le RWKV 14B. L'état dispose de 200 vecteurs, soit 5 vecteurs pour chaque bloc : fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx).
Ne faites pas de moyenne de pool car différents vecteurs (xx aa bb pp xx) dans l'état ont des significations et des plages très différentes. Vous pouvez probablement supprimer pp.
Je suggère d'abord de collecter les statistiques moyenne + stdev de chaque canal de chaque vecteur et de les normaliser toutes (remarque : la normalisation doit être indépendante des données et collectée à partir de divers textes). Entraînez ensuite un classificateur linéaire.
Le RWKV-5 est multi-têtes et montre ici une seule tête. Il existe également un LayerNorm pour chaque tête (donc en fait GroupNorm).
Mélange dynamique et décroissance dynamique. Exemple (faites ceci pour TimeMix et ChannelMix) :
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Utilisez le mode parallélisé pour générer rapidement l'état, puis utilisez un RNN complet affiné (les couches du jeton n peuvent utiliser les sorties de toutes les couches du jeton n-1) pour la génération séquentielle.
Maintenant, la décroissance du temps est de l'ordre de 0,999 ^ T (0,999 est apprenable). Remplacez-le par quelque chose comme (0,999 ^ T + 0,1) où 0,1 peut également être appris. La partie 0.1 sera conservée pour toujours. Ou, A^T + B^T + C = décroissance rapide + décroissance lente + constante. Peut même utiliser différentes formules (par exemple, K^2 au lieu de e^K pour un composant de désintégration, ou sans normalisation).
Utilisez une décroissance à valeurs complexes (donc une rotation au lieu d'une décroissance) dans certains canaux.
Injecter un codage positionnel entraînable et extrapolable ?
Outre la rotation 2D, nous pouvons essayer d'autres groupes de Lie tels que la rotation 3D ( SO(3) ). RWKV non abélien mdr.
RWKV pourrait être idéal sur les appareils analogiques (recherchez la multiplication analogique-matrice-vecteur et la multiplication photonique-matrice-vecteur). Le mode RNN est très convivial (traitement en mémoire). Peut également être un SNN (https://github.com/ridgerchu/SpikeGPT). Je me demande s'il peut être optimisé pour le calcul quantique.
État caché initial entraînable (xx aa bb pp xx).
LR par couche (ou même par ligne/colonne, par élément) et testez l'optimiseur Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Peut-être pouvons-nous améliorer la mémorisation en répétant simplement le contexte (je suppose que 2 fois suffisent). Exemple : Référence -> Référence (encore) -> Question -> Réponse
L'idée est de s'assurer que chaque jeton du vocabulaire comprend sa longueur et ses octets UTF-8 bruts.
Soit a = max(len(token)) pour tous les jetons du vocabulaire. Définir AA : float[a][d_emb]
Soit b = max(len_in_utf8_bytes(token)) pour tous les jetons du vocabulaire. Définir BB : float[b][256][d_emb]
Pour chaque jeton X du vocabulaire, soit [x0, x1, ..., xn] ses octets UTF-8 bruts. Nous ajouterons quelques valeurs supplémentaires à son intégration EMB(X) :
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (remarque : AA BB sont des poids apprenables)
J'ai une idée pour améliorer la tokenisation. Nous pouvons coder en dur certains canaux pour qu'ils aient une signification. Exemple:
Canal 0 = "espace"
Canal 1 = "mettre la première lettre en majuscule"
Canal 2 = "mettre toutes les lettres en majuscule"
Donc:
Intégration de "abc": [0, 0, 0, x0, x1, x2 , ..]
Intégration de " abc " : [1, 0, 0, x0, x1, x2, ..]
Intégration de " Abc " : [1, 1, 0, x0, x1, x2, ..]
Intégration de "ABC": [0, 0, 1, x0, x1, x2, ...]
......
ils partageront donc la majeure partie de l’intégration. Et nous pouvons calculer rapidement la probabilité de sortie de toutes les variations de « abc ».
Remarque : la méthode ci-dessus suppose que p(" xyz ") / p (" xyz ") est le même pour tout " xyz ", ce qui peut être faux.
Mieux : définissez emb_space emb_capitalize_first emb_capitalize_all comme étant une fonction d'emb.
Peut-être le meilleur : laissez 'abc' 'abc' etc. partager les derniers 90 % de leurs intégrations.
À l'heure actuelle, tous nos tokeniseurs dépensent trop d'éléments pour représenter toutes les variantes de « abc », « abc », « Abc », etc. De plus, le modèle ne peut pas découvrir qu'ils sont réellement similaires si certaines de ces variations sont rares dans l'ensemble de données. La méthode ici peut améliorer cela. Je prévois de tester cela dans une nouvelle version de RWKV.
Exemple (questions et réponses en un seul tour) :
Générez l'état final de tous les documents wiki.
Pour tout utilisateur Q, recherchez le meilleur document wiki et utilisez son état final comme état initial.
Entraîner un modèle pour générer directement l'état initial optimal pour tout utilisateur Q.
Cependant, cela peut être un peu plus délicat pour les questions et réponses à plusieurs tours :)
RWKV s'inspire de l'AFT d'Apple (https://arxiv.org/abs/2105.14103).
De plus, il utilise un certain nombre de mes astuces, telles que :
SmallInitEmb : https://github.com/BlinkDL/SmallInitEmb (applicable à tous les transformateurs) qui améliore la qualité de l'intégration et stabilise Post-LN (c'est ce que j'utilise).
Token-shift : https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (applicable à tous les transformateurs), particulièrement utile pour les modèles au niveau des caractères.
Head-QK : https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (applicable à tous les transformateurs). Remarque : c'est utile, mais je l'ai désactivé dans le modèle Pile pour le conserver à 100 % RNN.
R-gate supplémentaire dans le FFN (applicable à tous les transformateurs). J'utilise également reluSquared de Primer.
Meilleure initialisation : j'initialise la plupart des matrices à ZÉRO (voir RWKV_Init dans https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Vous pouvez transférer certains paramètres d'un petit modèle vers un grand modèle (remarque : je les trie et les lisse également), pour une convergence plus rapide et meilleure (voir https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizing_rnn_with /).
Mon noyau CUDA : https://github.com/BlinkDL/RWKV-CUDA pour accélérer la formation.

Les facteurs abcd fonctionnent ensemble pour construire une courbe de décroissance temporelle : [X, 1, W, W^2, W^3, ...].
Écrivez les formules pour « jeton en pos 2 » et « jeton en pos 3 » et vous aurez l'idée :
kv/k est le mécanisme de mémoire. Le jeton avec un k élevé peut être mémorisé pendant une longue durée, si W est proche de 1 dans le canal.
La R-gate est importante pour les performances. k = force d'information de ce jeton (à transmettre aux futurs jetons). r = s'il faut appliquer les informations à ce jeton.
Utilisez différents facteurs TimeMix entraînables pour R/K/V dans les couches SA et FF. Exemple:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Utilisez preLN au lieu de postLN (convergence plus stable et plus rapide) :
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Les éléments de base du mode RWKV-3 GPT sont similaires à ceux d’un GPT préLN habituel.
La seule différence est un LN supplémentaire après l'intégration. Notez que vous pouvez absorber ce LN dans l'intégration après avoir terminé la formation.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsIl est important d'initialiser emb avec des valeurs minuscules, telles que nn.init.uniform_(a=-1e-4, b=1e-4), pour utiliser mon astuce https://github.com/BlinkDL/SmallInitEmb.
Pour le 1,5B RWKV-3, j'utilise l'optimiseur Adam (pas de wd, pas de décrochage) sur 8*A100 40G.
batchSz = 32 * 896, ctxLen = 896. J'utilise tf32 donc le batchSz est un peu petit.
Pour les 15 premiers jetons, LR est fixé à 3e-4 et bêta = (0,9, 0,99).
Ensuite, je définis bêta = (0,9, 0,999) et j'effectue une décroissance exponentielle de LR, atteignant 1e-5 à 332 milliards de jetons.
Le RWKV-3 n'a aucune attention au sens habituel du terme, mais nous appellerons quand même ce bloc ATT.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionLes matrices self.key, self.receptance, self.output sont toutes initialisées à zéro.
Les vecteurs time_mix, time_decay, time_first sont transférés à partir d'un modèle entraîné plus petit (remarque : je les trie et les lisse également).
Le bloc FFN a trois astuces par rapport au GPT habituel :
Mon astuce time_mix.
Le sqReLU du papier Primer.
Une porte de réception supplémentaire (similaire à la porte de réception du bloc ATT).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvLes matrices de valeur de soi et de réception de soi sont toutes initialisées à zéro.

Soit F[t] l'état du système à t.
Soit x[t] la nouvelle entrée externe en t.
En GPT, prédire F[t+1] nécessite de considérer F[0], F[1], .. F[t]. Il faut donc O(T^2) pour générer une séquence de longueur T.
La formule simplifiée pour GPT :
Il est très performant en théorie, mais cela ne signifie pas que nous pouvons utiliser pleinement ses capacités avec les optimiseurs habituels . Je soupçonne que le paysage des pertes est trop difficile pour nos méthodes actuelles.
Comparez avec la formule simplifiée pour RWKV (le mode parallèle ressemble à l'AFT d'Apple) :
Les R, K, V sont des matrices entraînables et W est un vecteur entraînable (facteur de décroissance temporelle pour chaque canal).
Dans GPT, la contribution de F[i] à F[t+1] est pondérée par .
Dans RWKV-2, la contribution de F[i] à F[t+1] est pondérée par .
Voici la punchline : nous pouvons la réécrire dans un RNN (formule récursive). Note:
Il est donc simple de vérifier :
où A[t] et B[t] sont respectivement le numérateur et le dénominateur de l’étape précédente.
Je pense que RWKV est performant car W revient à appliquer à plusieurs reprises une matrice diagonale. Notez (P^{-1} DP)^n = P^{-1} D^n P, cela revient donc à appliquer à plusieurs reprises une matrice diagonalisable générale.
De plus, il est possible de le transformer en une ODE continue (un peu similaire aux State Space Models). J'en parlerai plus tard.
J'ai une idée pour [texte --> image RVB 32x32] en utilisant un LM (transformateur, RWKV, etc.). Je vais le tester bientôt.
Premièrement, la perte LM (au lieu de la perte L2), donc l'image ne sera pas floue.
Deuxièmement, la quantification des couleurs. Par exemple, n'autoriser que 8 niveaux pour R/G/B. Ensuite, la taille du vocabulaire de l'image est de 8x8x8 = 512 (pour chaque pixel), au lieu de 2^24. Par conséquent, une image RVB 32x32 = une séquence len1024 de vocabulaire512 (jetons d'image), ce qui est une entrée typique pour les LM habituels. (Plus tard, nous pourrons utiliser des modèles de diffusion pour suréchantillonner et générer des images RGB888. Nous pourrons peut-être également utiliser un LM pour cela.)
Troisièmement, des intégrations positionnelles 2D faciles à comprendre pour le modèle. Par exemple, ajoutez des coordonnées X et Y uniques aux 64 premiers canaux (= 32 + 32). Disons que si le pixel est à x=8, y=20, alors nous ajouterons 1 au canal 8 et au canal 52 (=32+20). De plus, nous pouvons probablement ajouter les coordonnées flottantes X et Y (normalisées sur la plage 0 ~ 1) à 2 autres canaux. Et autres pos. périodiques. l'encodage pourrait également aider (je testerai).
Enfin, RandRound quand


