EasyInstruct
1.0.0

Un cadre de traitement d'instructions facile à utiliser pour les grands modèles de langage.
Projet • Document • Démo • Présentation • Installation • Démarrage rapide • Comment utiliser • Documents • Vidéo • Citation • Contributeurs
Ce référentiel est un sous-projet de KnowLM.
EasyInstruct est un package Python proposé comme cadre de traitement d'instructions facile à utiliser pour les grands modèles linguistiques (LLM) comme GPT-4, LLaMA, ChatGLM dans vos expériences de recherche. EasyInstruct modularise la génération, la sélection et les invites d'instructions, tout en prenant également en compte leur combinaison et leur interaction.
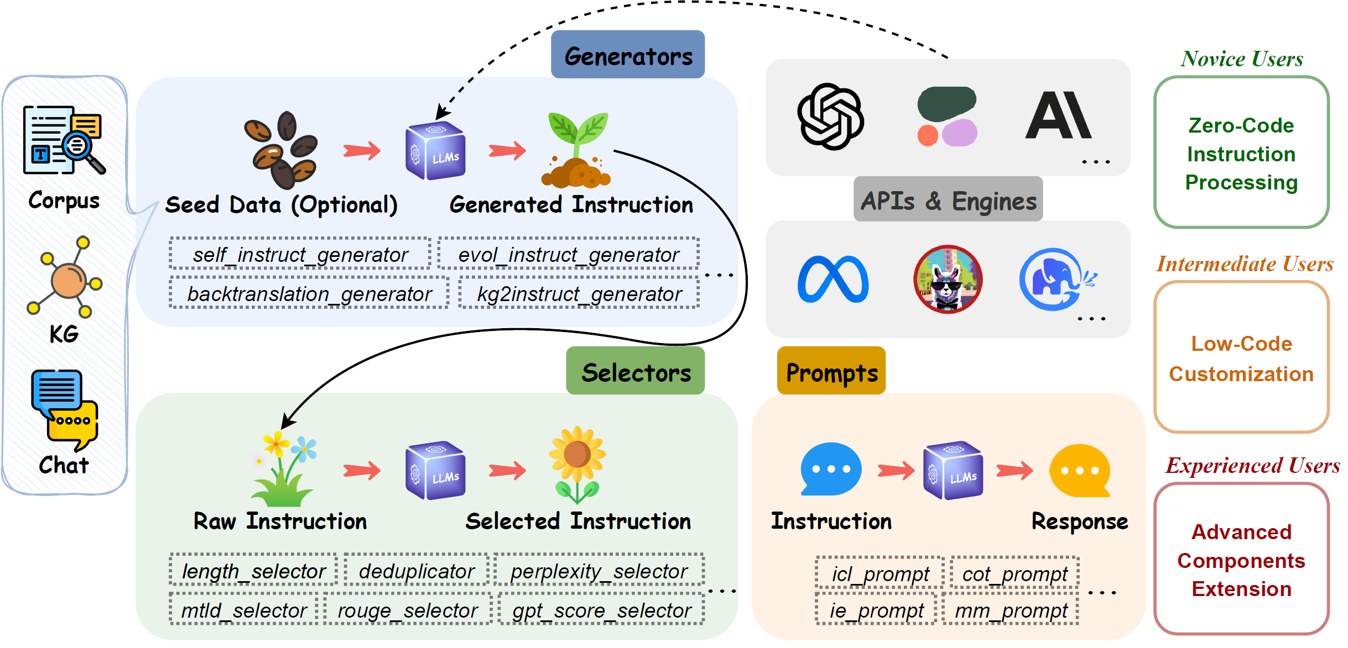
Les techniques de génération d'instructions actuellement prises en charge sont les suivantes :
| Méthodes | Description |
|---|---|
| Auto-instruction | La méthode qui échantillonne de manière aléatoire quelques instructions d'un pool de tâches de départ annotées par l'homme à titre de démonstration et invite un LLM à générer plus d'instructions et les paires entrée-sortie correspondantes. |
| Evol-Instruire | Méthode qui met progressivement à niveau un ensemble initial d'instructions en instructions plus complexes en invitant un LLM avec des invites spécifiques. |
| Rétrotraduction | Méthode qui crée une instruction suite à une instance de formation en prédisant une instruction à laquelle une partie d'un document du corpus répondrait correctement. |
| KG2Instruire | Méthode qui crée une instruction suite à une instance de formation en prédisant une instruction à laquelle une partie d'un document du corpus répondrait correctement. |
Les métriques de sélection d'instructions actuellement prises en charge sont les suivantes :
| Métrique | Notation | Description |
|---|---|---|
| Longueur | La longueur limitée de chaque paire d’instructions et de réponses. | |
| Perplexité | Log-vraisemblance négative moyenne exponentiée de réponse. | |
| MTLD | Mesure de la diversité lexicale textuelle, la longueur moyenne des mots séquentiels dans un texte qui maintient un seuil minimum de score TTR. | |
| ROUGE | Étude orientée rappel pour l'évaluation Gisting, un ensemble de mesures utilisées pour évaluer les similitudes entre les phrases. | |
| Score GPT | Le score indiquant si le résultat est un bon exemple de la façon dont AI Assistant doit répondre aux instructions de l'utilisateur, fournies par ChatGPT. | |
| CIRS | Le score utilise l'arbre de syntaxe abstraite pour coder les attributs structurels et logiques, afin de mesurer la corrélation entre le code et les capacités de raisonnement. |
Fournisseurs de services API et leurs produits LLM correspondants actuellement disponibles :
| Modèle | Description | Version par défaut |
|---|---|---|
| OpenAI | ||
| GPT-3.5 | Un ensemble de modèles qui améliorent GPT-3 et peuvent comprendre et générer du langage naturel ou du code. | gpt-3.5-turbo |
| GPT-4 | Un ensemble de modèles qui améliorent GPT-3.5 et peuvent comprendre et générer du langage naturel ou du code. | gpt-4 |
| Anthropique | ||
| Claude | Un assistant IA de nouvelle génération basé sur les recherches d'Anthropic sur la formation de systèmes d'IA utiles, honnêtes et inoffensifs. | claude-2.0 |
| Claude-Instant | Une option plus légère, moins chère et beaucoup plus rapide que Claude. | claude-instant-1.2 |
| Adhérer | ||
| Commande | Un modèle phare de génération de texte de Cohere, formé pour suivre les commandes de l'utilisateur et pour être instantanément utile dans des applications métiers pratiques. | command |
| Lumière de commande | Une version allégée des modèles Command qui sont plus rapides mais peuvent produire du texte généré de moindre qualité. | command-light |
Installation à partir de la branche du dépôt git :
pip install git+https://github.com/zjunlp/EasyInstruct@main
Installation pour le développement local :
git clone https://github.com/zjunlp/EasyInstruct
cd EasyInstruct
pip install -e .
Installation à l'aide de PyPI (pas la dernière version) :
pip install easyinstruct -i https://pypi.org/simple
Nous proposons aux utilisateurs deux façons de démarrer rapidement avec EasyInstruct. Vous pouvez utiliser le script shell ou l'application Gradio en fonction de vos besoins spécifiques.
Les utilisateurs peuvent facilement configurer les paramètres d'EasyInstruct dans un fichier de style YAML ou simplement utiliser rapidement les paramètres par défaut dans les fichiers de configuration que nous fournissons. Voici un exemple de fichier de configuration pour Self-Instruct :
generator :
SelfInstructGenerator :
target_dir : data/generations/
data_format : alpaca
seed_tasks_path : data/seed_tasks.jsonl
generated_instructions_path : generated_instructions.jsonl
generated_instances_path : generated_instances.jsonl
num_instructions_to_generate : 100
engine : gpt-3.5-turbo
num_prompt_instructions : 8D'autres exemples de fichiers de configuration peuvent être trouvés dans configs.
Les utilisateurs doivent d'abord spécifier le fichier de configuration et fournir leur propre clé API OpenAI. Ensuite, exécutez le script shell suivant pour lancer le processus de génération ou de sélection d’instructions.
config_file= " "
openai_api_key= " "
python demo/run.py
--config $config_file
--openai_api_key $openai_api_key Nous fournissons une application Gradio permettant aux utilisateurs de démarrer rapidement avec EasyInstruct. Vous pouvez exécuter la commande suivante pour lancer l'application Gradio localement sur le port 8080 (si disponible).
python demo/app.pyNous hébergeons également une application gradio en cours d'exécution dans HuggingFace Spaces. Vous pouvez l'essayer ici.
Veuillez vous référer à nos documentations pour plus de détails.
Le module Generators rationalise le processus de génération de données d'instruction, permettant la génération de données d'instruction basées sur des données de départ. Vous pouvez choisir le générateur approprié en fonction de vos besoins spécifiques.
BaseGeneratorest la classe de base pour tous les générateurs.
Vous pouvez également facilement hériter de cette classe de base pour personnaliser votre propre classe génératrice. Remplacez simplement la méthode
__init__etgenerate.
SelfInstructGeneratorest la classe de la méthode de génération d'instructions de Self-Instruct. Voir Auto-instruction : aligner le modèle de langage avec les instructions auto-générées pour plus de détails.
Exemple
from easyinstruct import SelfInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = SelfInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate self-instruct data
generator . generate ()
BacktranslationGeneratorest la classe pour la méthode de génération d’instructions d’Instruction Backtranslation. Voir Auto-alignement avec traduction inverse des instructions pour plus de détails.
from easyinstruct import BacktranslationGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = BacktranslationGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate backtranslation data
generator . generate ()
EvolInstructGeneratorest la classe de la méthode de génération d'instructions d'EvolInstruct. Voir WizardLM : Permettre aux grands modèles de langage de suivre des instructions complexes pour plus de détails.
from easyinstruct import EvolInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = EvolInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate evolution data
generator . generate ()
KG2InstructGeneratorest la classe de la méthode de génération d'instructions de KG2Instruct. Voir InstructIE : un ensemble de données d'extraction d'informations basées sur des instructions chinoises pour plus de détails.
Le module Selectors standardise le processus de sélection des instructions, permettant l'extraction d'ensembles de données d'instructions de haute qualité à partir de données d'instructions brutes et non traitées. Les données brutes peuvent provenir d’ensembles de données d’instructions accessibles au public ou être générées par le framework lui-même. Vous pouvez choisir le sélecteur approprié en fonction de vos besoins spécifiques.
BaseSelectorest la classe de base pour tous les sélecteurs.
Vous pouvez également facilement hériter de cette classe de base pour personnaliser votre propre classe de sélecteur. Remplacez simplement les méthodes
__init__et__process__.
Deduplicatorest la classe permettant d'éliminer les échantillons d'instructions en double qui pourraient nuire à la fois à la stabilité avant la formation et aux performances des LLM.Deduplicatorpeut également permettre une utilisation et une optimisation efficaces de l'espace de stockage.
LengthSelectorest la classe permettant de sélectionner des échantillons d'instructions en fonction de la longueur de l'instruction. Les instructions trop longues ou trop courtes peuvent affecter la qualité des données et ne sont pas propices au réglage des instructions.
RougeSelectorest la classe de sélection d'échantillons d'instructions basée sur la métrique ROUGE qui est souvent utilisée pour évaluer la qualité de la génération automatisée de texte.
GPTScoreSelectorest la classe permettant de sélectionner des échantillons d'instructions en fonction du score GPT, qui indique si le résultat est un bon exemple de la façon dont AI Assistant doit répondre aux instructions de l'utilisateur, fournies par ChatGPT.
PPLSelectorest la classe permettant de sélectionner des échantillons d'instructions en fonction de la perplexité, qui est la probabilité logarithmique négative moyenne exponentiée de réponse.
MTLDSelectorest la classe permettant de sélectionner des échantillons d'instructions basés sur le MTLD, qui est l'abréviation de Measure of Textual Lexical Diversity.
CodeSelectorest la classe permettant de sélectionner des échantillons d'instructions de code basées sur le score de raisonnement impacté par la complexité (CIRS), qui combine des attributs structurels et logiques, pour mesurer la corrélation entre le code et les capacités de raisonnement. Voir Quand le programme de pensées fonctionne-t-il pour le raisonnement ? pour plus de détails.
from easyinstruct import CodeSelector
# Step1: Specify your source file of code instructions
src_file = "data/code_example.json"
# Step2: Declare a code selecter class
selector = CodeSelector (
source_file_path = src_file ,
target_dir = "data/selections/" ,
manually_partion_data = True ,
min_boundary = 0.125 ,
max_boundary = 0.5 ,
automatically_partion_data = True ,
k_means_cluster_number = 2 ,
)
# Step3: Process the code instructions
selector . process ()
MultiSelectorest la classe permettant de combiner plusieurs sélecteurs appropriés en fonction de vos besoins spécifiques.
Le module Prompts standardise l'étape d'invite d'instructions, où les demandes des utilisateurs sont construites sous forme d'invites d'instructions et envoyées à des LLM spécifiques pour obtenir des réponses. Vous pouvez choisir la méthode d'invite appropriée en fonction de vos besoins spécifiques.
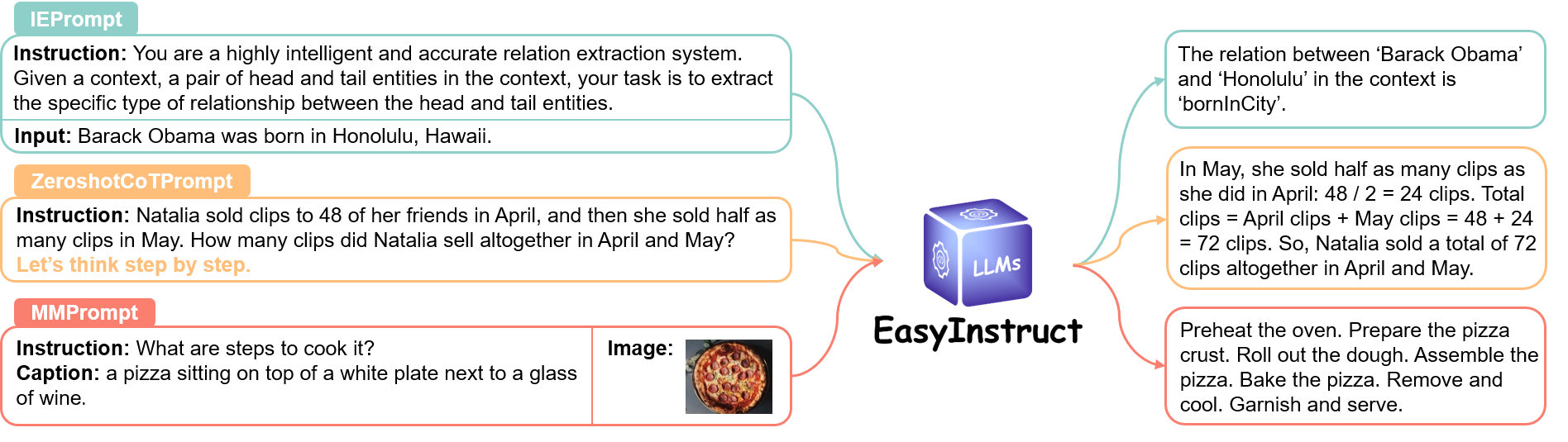
Veuillez consulter le lien pour plus de détails.
Le module Engines standardise le processus d'exécution des instructions, permettant l'exécution d'invites d'instructions sur des LLM spécifiques déployés localement. Vous pouvez choisir le moteur approprié en fonction de vos besoins spécifiques.
Veuillez consulter le lien pour plus de détails.
Veuillez citer notre référentiel si vous utilisez EasyInstruct dans votre travail.
@article { ou2024easyinstruct ,
title = { EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models } ,
author = { Ou, Yixin and Zhang, Ningyu and Gui, Honghao and Xu, Ziwen and Qiao, Shuofei and Bi, Zhen and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2402.03049 } ,
year = { 2024 }
}
@misc { knowlm ,
author = { Ningyu Zhang and Jintian Zhang and Xiaohan Wang and Honghao Gui and Kangwei Liu and Yinuo Jiang and Xiang Chen and Shengyu Mao and Shuofei Qiao and Yuqi Zhu and Zhen Bi and Jing Chen and Xiaozhuan Liang and Yixin Ou and Runnan Fang and Zekun Xi and Xin Xu and Lei Li and Peng Wang and Mengru Wang and Yunzhi Yao and Bozhong Tian and Yin Fang and Guozhou Zheng and Huajun Chen } ,
title = { KnowLM: An Open-sourced Knowledgeable Large Langugae Model Framework } ,
year = { 2023 } ,
url = { http://knowlm.zjukg.cn/ } ,
}
@article { bi2023program ,
title = { When do program-of-thoughts work for reasoning? } ,
author = { Bi, Zhen and Zhang, Ningyu and Jiang, Yinuo and Deng, Shumin and Zheng, Guozhou and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2308.15452 } ,
year = { 2023 }
}Nous proposerons une maintenance à long terme pour corriger les bugs, résoudre les problèmes et répondre aux nouvelles demandes. Donc, si vous rencontrez des problèmes, veuillez nous en faire part.
Autres projets connexes
? Nous tenons à exprimer notre sincère gratitude pour la contribution de Self-Instruct à notre projet, car nous avons utilisé des parties de leur code source dans notre projet.


