DiGIT
1.0.0
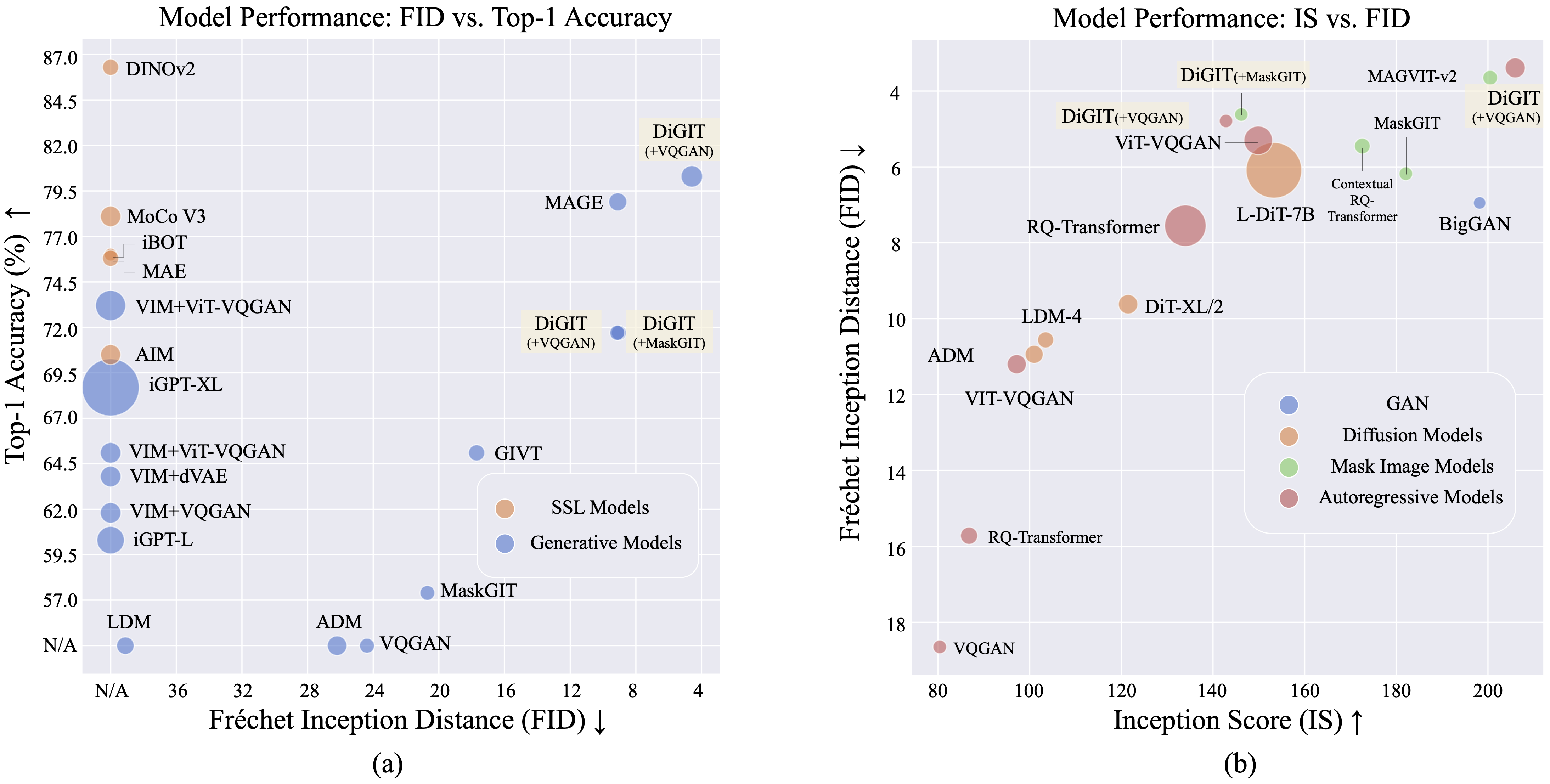
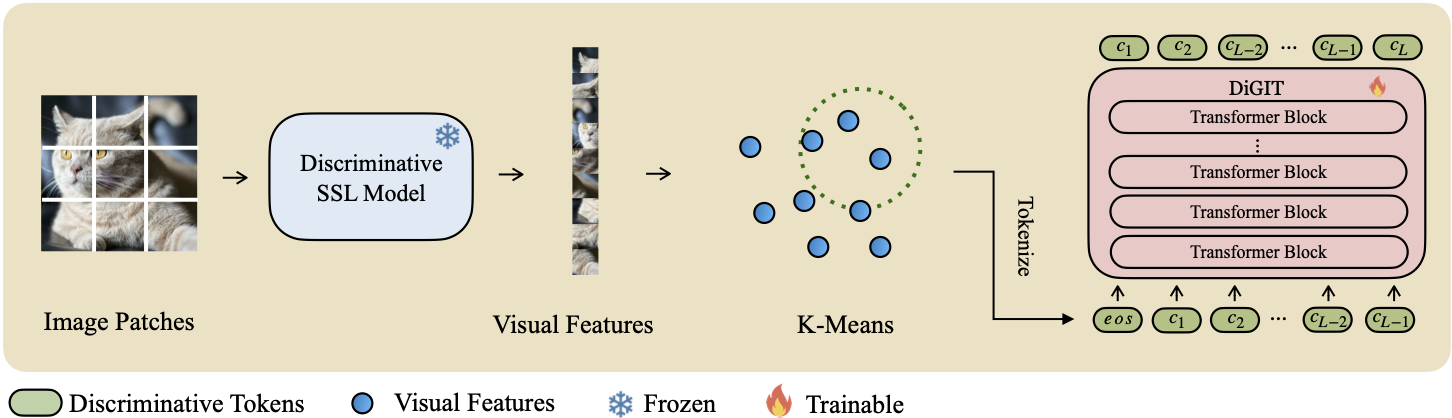
Nous présentons DiGIT , un modèle génératif auto-régressif effectuant la prédiction du prochain jeton dans un espace latent abstrait dérivé de modèles d'apprentissage auto-supervisé (SSL). En utilisant le clustering K-Means sur les états cachés du modèle DINOv2, nous créons efficacement un nouveau tokeniseur discret. Cette méthode améliore considérablement les performances de génération d'images sur l'ensemble de données ImageNet, atteignant un score FID de 4,59 pour les tâches inconditionnelles de classe et de 3,39 pour les tâches conditionnelles de classe . De plus, le modèle améliore la compréhension des images, atteignant une précision de sonde linéaire de 80,3 .
| Méthodes | # Jetons | Caractéristiques | # Paramètres | Top-1 Acc. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362M | 60,3 |
| iGPT-XL | 64 | 3072 | 6801M | 68,7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61,8 |
| VIM+dVAE | 32 | 1024 | 650M | 63,8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697M | 73.2 |
| BUT | 16 | 1536 | 0,6 B | 70,5 |
| DiGIT (le nôtre) | 16 | 1024 | 219M | 71,7 |
| DiGIT (le nôtre) | 16 | 1536 | 732M | 80,3 |
| Taper | Méthodes | #Paramètre | # Époque | FID | EST |
|---|---|---|---|---|---|
| GAN | GrosGAN | 70M | - | 38,6 | 24h70 |
| Diff. | MLD | 395M | - | 39.1 | 22.83 |
| Diff. | SMA | 554M | - | 26.2 | 39.70 |
| MIM | MAGE | 200M | 1600 | 11.1 | 81.17 |
| MIM | MAGE | 463M | 1600 | 9.10 | 105.1 |
| MIM | MasqueGIT | 227M | 300 | 20,7 | 42.08 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 9.04 | 75.04 |
| RA | VQGAN | 214M | 200 | 24h38 | 30.93 |
| RA | DiGIT (+VQGAN) | 219M | 400 | 9.13 | 73,85 |
| RA | DiGIT (+VQGAN) | 732M | 200 | 4,59 | 141.29 |
| Taper | Méthodes | #Paramètre | # Époque | FID | EST |
|---|---|---|---|---|---|
| GAN | GrosGAN | 160M | - | 6,95 | 198.2 |
| Diff. | SMA | 554M | - | 10.94 | 101,0 |
| Diff. | LDM-4 | 400M | - | 10.56 | 103,5 |
| Diff. | DiT-XL/2 | 675M | - | 9.62 | 121,50 |
| Diff. | L-DiT-7B | 7B | - | 6.09 | 153.32 |
| MIM | CQR-Trans | 371M | 300 | 5h45 | 172,6 |
| MIM+RA | VAR | 310M | 200 | 4,64 | - |
| MIM+RA | VAR | 310M | 200 | 3,60* | 257,5* |
| MIM+RA | VAR | 600M | 250 | 2,95* | 306.1* |
| MIM | MAGVIT-v2 | 307M | 1080 | 3,65 | 200,5 |
| RA | VQVAE-2 | 13,5B | - | 31.11 | 45 |
| RA | RQ-Trans | 480M | - | 15.72 | 86,8 |
| RA | RQ-Trans | 3,8 milliards | - | 7h55 | 134,0 |
| RA | ViTVQGAN | 650M | 360 | 11h20 | 97,2 |
| RA | ViTVQGAN | 1,7 milliards | 360 | 5.3 | 149,9 |
| MIM | MasqueGIT | 227M | 300 | 6.18 | 182.1 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 4,62 | 146.19 |
| RA | VQGAN | 227M | 300 | 18h65 | 80,4 |
| RA | DiGIT (+VQGAN) | 219M | 400 | 4,79 | 142,87 |
| RA | DiGIT (+VQGAN) | 732M | 200 | 3.39 | 205,96 |
* : VAR est formé avec un guidage sans classificateur alors que tous les autres modèles ne le sont pas.
Le fichier npy K-Means et les points de contrôle du modèle peuvent être téléchargés à partir de :
| Modèle | Lien |
|---|---|
| Des poids HF ? | Visage câlin |
Pour le modèle de base, nous utilisons DINOv2-base et DINOv2-large pour les modèles de grande taille. Le VQGAN que nous utilisons est le même que MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq via pip install fairseq . Téléchargez l'ensemble de données ImageNet et placez-le dans le répertoire de votre ensemble de données $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Extrayez les fonctionnalités SSL et enregistrez-les sous forme de fichiers .npy. Utilisez l'algorithme K-Means avec faiss pour calculer les centroïdes. Vous pouvez également utiliser nos centroïdes pré-entraînés disponibles sur Huggingface.
bash preprocess/run.shÉtape 1
Entraînez un modèle GPT avec un tokenizer discriminant. Vous pouvez trouver les scripts de formation dans scripts/train_stage1_ar.sh et les hyper-params sont dans config/stage1/dino_base.yaml . Pour la configuration de la génération conditionnelle de classe, voir scripts/train_stage1_classcond.sh .
Étape 2
Entraînez un décodeur de pixels (modèle AR ou modèle NAR) conditionné sur les jetons discriminants. Vous pouvez trouver les scripts de formation autorégressifs dans scripts/train_stage2_ar.sh et les scripts de formation NAR dans scripts/train_stage2_nar.sh .
Un dossier nommé outputs/EXP_NAME/checkpoints sera créé pour enregistrer les points de contrôle. Les fichiers journaux TensorBoard sont enregistrés dans outputs/EXP_NAME/tb . Les journaux seront enregistrés dans outputs/EXP_NAME/train.log .
Vous pouvez surveiller le processus de formation à l'aide tensorboard --logdir=outputs/EXP_NAME/tb .
Premier échantillonnage de jetons discriminants avec scripts/infer_stage1_ar.sh . Pour la taille du modèle de base, nous vous recommandons de définir topk=200 et pour une taille de modèle de grande taille, utilisez topk=400.
Exécutez ensuite scripts/infer_stage2_ar.sh pour échantillonner les jetons VQ en fonction des jetons discriminants précédemment échantillonnés.
Les jetons générés et les images synthétisées seront stockés dans un répertoire nommé outputs/EXP_NAME/results .
Préparez l'ensemble de validation ImageNet pour l'évaluation FID :
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Installez l'outil d'évaluation en exécutant pip install torch-fidelity .
Exécutez la commande suivante pour évaluer le FID :
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shCe projet est sous licence MIT - voir le fichier LICENSE pour plus de détails.
Si vous trouvez notre projet utile, j'espère que vous pourrez mettre en vedette notre dépôt et citer notre travail comme suit.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

