FasterTransformer
v5.3 release
Remarque : Le développement de FasterTransformer est passé à TensorRT-LLM. Tous les développeurs sont encouragés à tirer parti de TensorRT-LLM pour bénéficier des dernières améliorations en matière d'inférence LLM. Le dépôt NVIDIA/FasterTransformer restera actif, mais ne connaîtra pas de développement ultérieur.
Ce référentiel fournit un script et une recette pour exécuter le composant d'encodeur et de décodeur hautement optimisé basé sur un transformateur, et il est testé et maintenu par NVIDIA.
En NLP, l'encodeur et le décodeur sont deux composants importants, la couche transformateur devenant une architecture populaire pour les deux composants. FasterTransformer implémente une couche de transformateur hautement optimisée pour l'encodeur et le décodeur pour l'inférence. Sur les GPU Volta, Turing et Ampere, la puissance de calcul des Tensor Cores est utilisée automatiquement lorsque la précision des données et des poids est FP16.
FasterTransformer est construit sur CUDA, cuBLAS, cuBLASLt et C++. Nous fournissons au moins une API des frameworks suivants : TensorFlow, PyTorch et Triton backend. Les utilisateurs peuvent intégrer FasterTransformer directement dans ces frameworks. Pour les frameworks de support, nous fournissons également des exemples de codes pour démontrer comment utiliser et montrer les performances sur ces frameworks.
| Modèles | Cadre | PC16 | INT8 (d'après Turing) | Rareté (après Ampère) | Tenseur parallèle | Pipeline parallèle | FP8 (après Hopper) |
|---|---|---|---|---|---|---|---|
| BERTE | TensorFlow | Oui | Oui | - | - | - | - |
| BERTE | PyTorch | Oui | Oui | Oui | Oui | Oui | - |
| BERTE | Back-end Triton | Oui | - | - | Oui | Oui | - |
| BERTE | C++ | Oui | Oui | - | - | - | Oui |
| XLNet | C++ | Oui | - | - | - | - | - |
| Encodeur | TensorFlow | Oui | Oui | - | - | - | - |
| Encodeur | PyTorch | Oui | Oui | Oui | - | - | - |
| Décodeur | TensorFlow | Oui | - | - | - | - | - |
| Décodeur | PyTorch | Oui | - | - | - | - | - |
| Décodage | TensorFlow | Oui | - | - | - | - | - |
| Décodage | PyTorch | Oui | - | - | - | - | - |
| Google Tag | TensorFlow | Oui | - | - | - | - | - |
| TPG/OPT | PyTorch | Oui | - | - | Oui | Oui | Oui |
| TPG/OPT | Back-end Triton | Oui | - | - | Oui | Oui | - |
| GPT-MoE | PyTorch | Oui | - | - | Oui | Oui | - |
| FLORAISON | PyTorch | Oui | - | - | Oui | Oui | - |
| FLORAISON | Back-end Triton | Oui | - | - | Oui | Oui | - |
| GPT-J | Back-end Triton | Oui | - | - | Oui | Oui | - |
| Forme longue | PyTorch | Oui | - | - | - | - | - |
| T5/UL2 | PyTorch | Oui | - | - | Oui | Oui | - |
| T5 | TensorFlow 2 | Oui | - | - | - | - | - |
| T5/UL2 | Back-end Triton | Oui | - | - | Oui | Oui | - |
| T5 | TensorRT | Oui | - | - | Oui | Oui | - |
| T5-MoE | PyTorch | Oui | - | - | Oui | Oui | - |
| Transformateur Swin | PyTorch | Oui | Oui | - | - | - | - |
| Transformateur Swin | TensorRT | Oui | Oui | - | - | - | - |
| ViT | PyTorch | Oui | Oui | - | - | - | - |
| ViT | TensorRT | Oui | Oui | - | - | - | - |
| GPT-NeoX | PyTorch | Oui | - | - | Oui | Oui | - |
| GPT-NeoX | Back-end Triton | Oui | - | - | Oui | Oui | - |
| BART/mBART | PyTorch | Oui | - | - | Oui | Oui | - |
| WeNet | C++ | Oui | - | - | - | - | - |
| DeBERTa | TensorFlow 2 | Oui | - | - | En cours | En cours | - |
| DeBERTa | PyTorch | Oui | - | - | En cours | En cours | - |
Plus de détails sur des modèles spécifiques sont indiqués dans xxx_guide.md de docs/ , où xxx signifie le nom du modèle. Certaines questions courantes et les réponses respectives sont placées dans docs/QAList.md . Notez que les modèles d'Encoder et de BERT sont similaires et nous avons mis l'explication ensemble dans bert_guide.md .
Le code suivant répertorie la structure des répertoires de FasterTransformer :
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Notez que de nombreux dossiers contiennent de nombreux sous-dossiers pour diviser différents modèles. Les outils de quantification sont déplacés vers examples , comme examples/tensorflow/bert/bert-quantization/ et examples/pytorch/bert/bert-quantization-sparsity/ .
FasterTransformer fournit des variables d'environnement pratiques pour le débogage et les tests.
FT_LOG_LEVEL : Cet environnement contrôle le niveau de journalisation des messages de débogage. Plus de détails se trouvent dans src/fastertransformer/utils/logger.h . Notez que le programme imprimera beaucoup de messages lorsque le niveau est inférieur à DEBUG et le programme deviendra très lent.FT_NVTX : S'il est défini sur ON comme FT_NVTX=ON ./bin/gpt_example , le programme insérera la balise de nvtx pour aider à profiler le programme.FT_DEBUG_LEVEL : S'il est défini sur DEBUG , alors le programme exécutera cudaDeviceSynchronize() après chaque noyau. Sinon, le noyau est exécuté de manière asynchrone par défaut. Il est utile de localiser le point d'erreur lors du débogage. Mais cet indicateur affecte considérablement les performances du programme. Il ne doit donc être utilisé que pour le débogage. Paramètres matériels :
Afin d'exécuter le benchmark suivant, nous devons installer l'outil informatique Unix "bc" en
apt-get install bc Les résultats FP16 de TensorFlow ont été obtenus en exécutant benchmarks/bert/tf_benchmark.sh .
Les résultats INT8 de TensorFlow ont été obtenus en exécutant benchmarks/bert/tf_int8_benchmark.sh .
Les résultats FP16 de PyTorch ont été obtenus en exécutant benchmarks/bert/pyt_benchmark.sh .
Les résultats INT8 de PyTorch ont été obtenus en exécutant benchmarks/bert/pyt_int8_benchmark.sh .
Plus de repères sont mis dans docs/bert_guide.md .
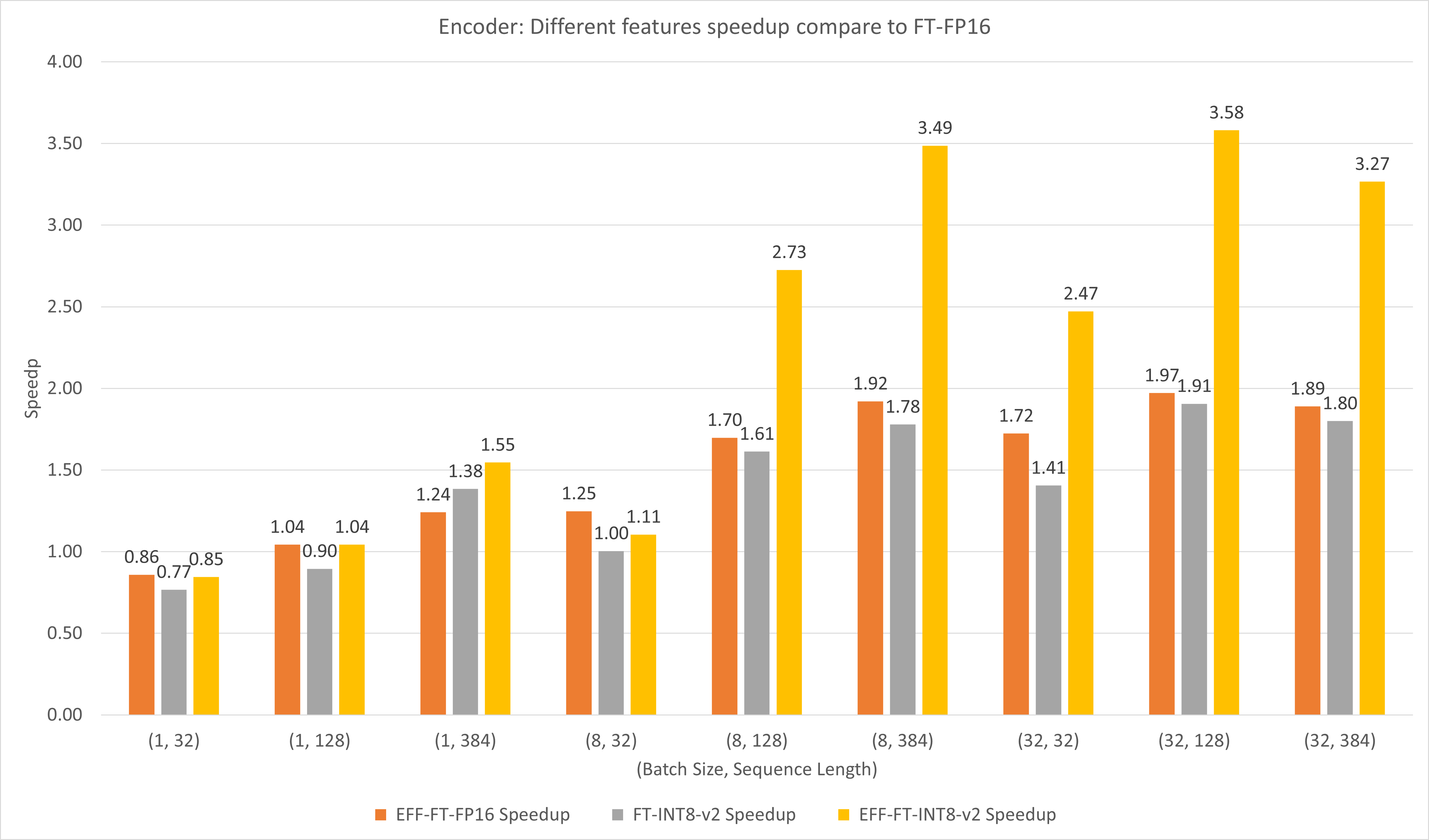
La figure suivante compare les performances des différentes fonctionnalités de FasterTransformer et FasterTransformer sous FP16 sur T4.
Pour les lots de grande taille et la longueur des séquences, EFF-FT et FT-INT8-v2 entraînent une accélération 2x. L'utilisation simultanée d'Effective FasterTransformer et de int8v2 peut entraîner une accélération d'environ 3,5 fois par rapport à FasterTransformer FP16 pour les grands boîtiers.
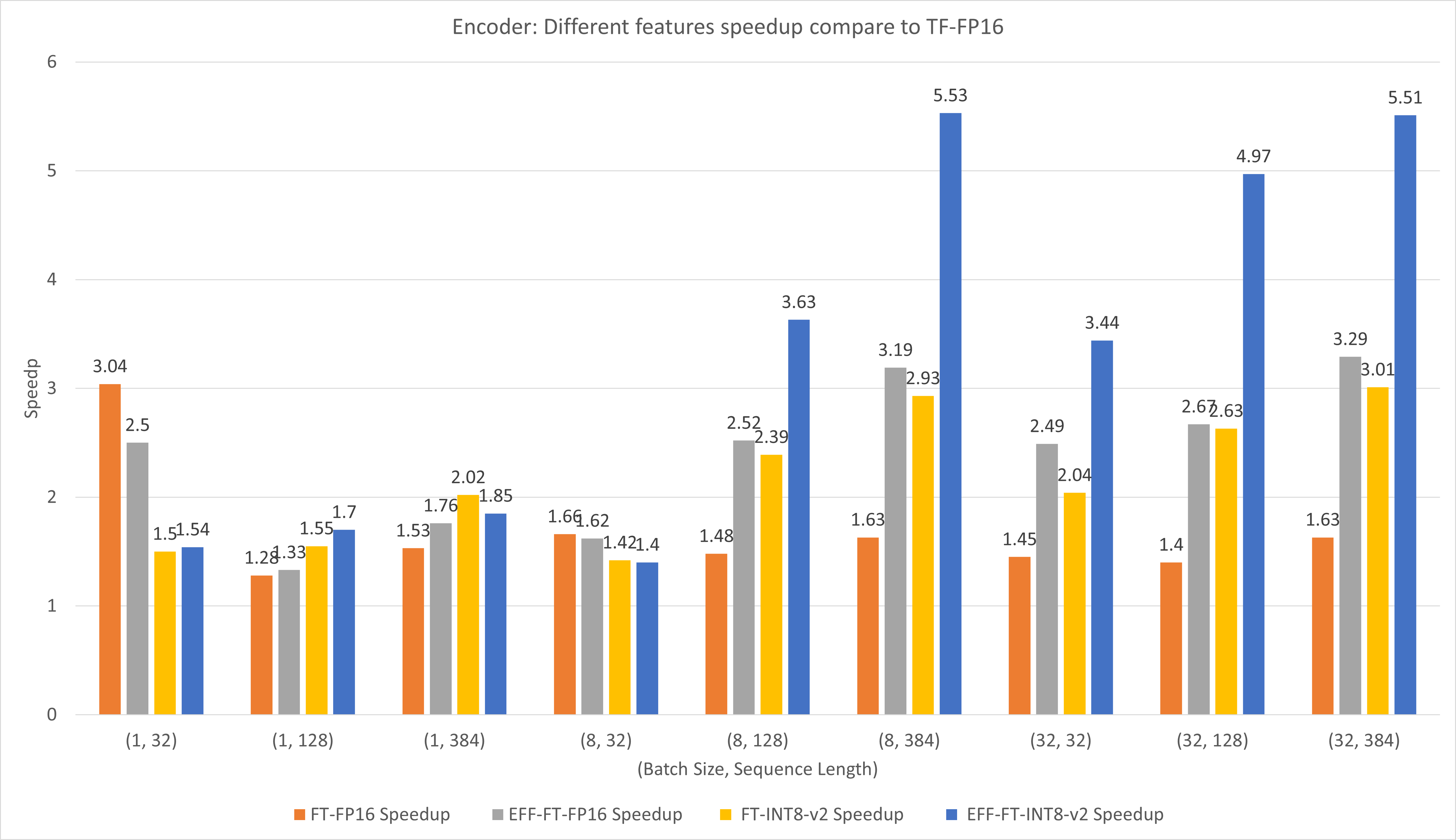
La figure suivante compare les performances de différentes fonctionnalités de FasterTransformer et TensorFlow XLA sous FP16 sur T4.
Pour les petits lots et la longueur de séquence, l'utilisation de FasterTransformer peut entraîner une accélération 3x.
Pour les lots de grande taille et la longueur de séquence, l'utilisation d'Effective FasterTransformer avec la quantification INT8-v2 peut entraîner une accélération d'environ 5 fois.
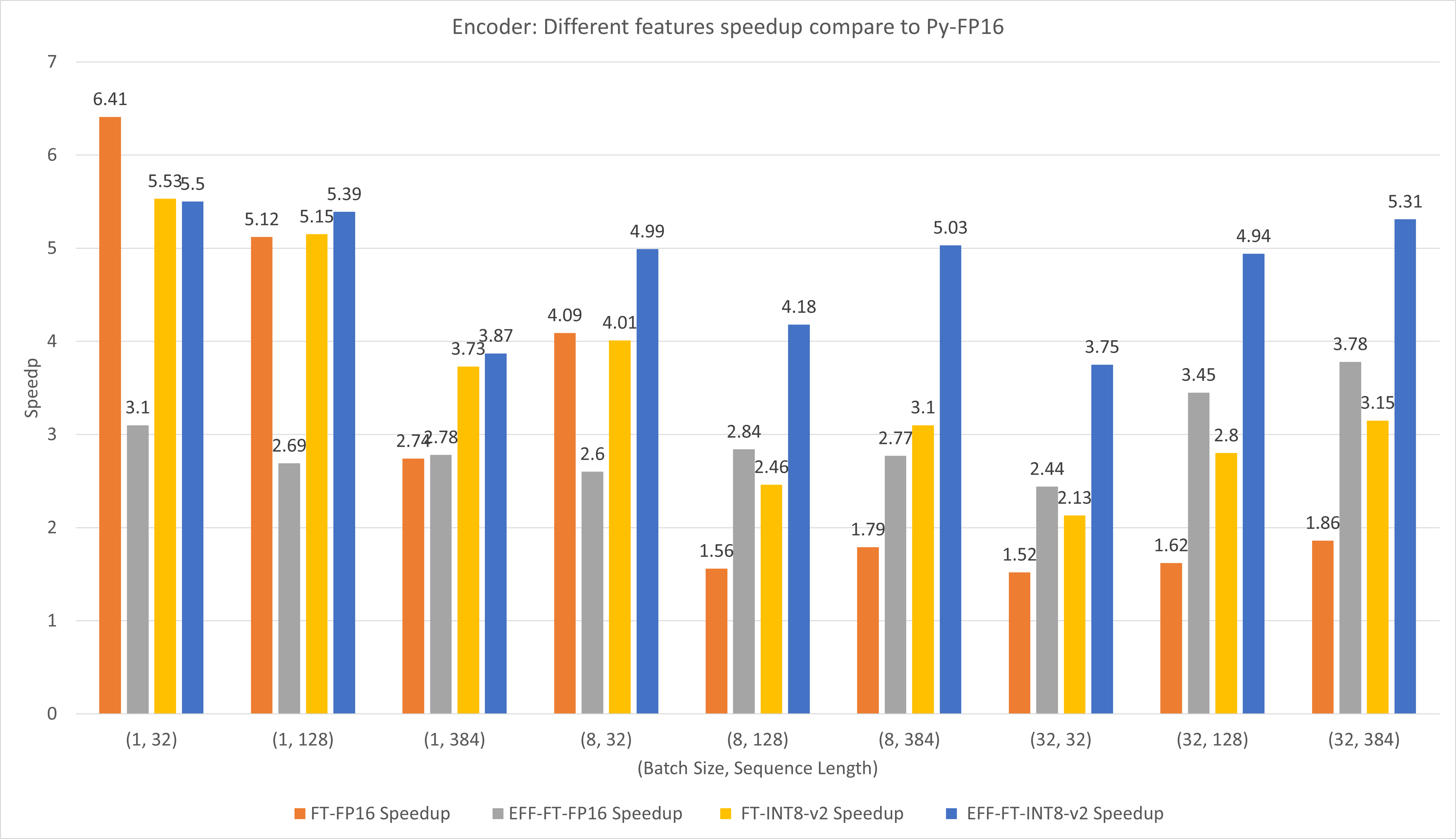
La figure suivante compare les performances des différentes fonctionnalités de FasterTransformer et PyTorch TorchScript sous FP16 sur T4.
Pour les petits lots et la longueur de séquence, l'utilisation de FasterTransformer CustomExt peut entraîner une accélération d'environ 4 à 6 fois.
Pour les lots de grande taille et la longueur de séquence, l'utilisation d'Effective FasterTransformer avec la quantification INT8-v2 peut entraîner une accélération d'environ 5 fois.
Les résultats de TensorFlow ont été obtenus en exécutant les benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh et benchmarks/decoding/tf_decoding_sampling_benchmark.sh
Les résultats de PyTorch ont été obtenus en exécutant benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh .
Dans les expériences de décodage, nous avons mis à jour les paramètres suivants :
Plus de benchmarks sont mis dans docs/decoder_guide.md .
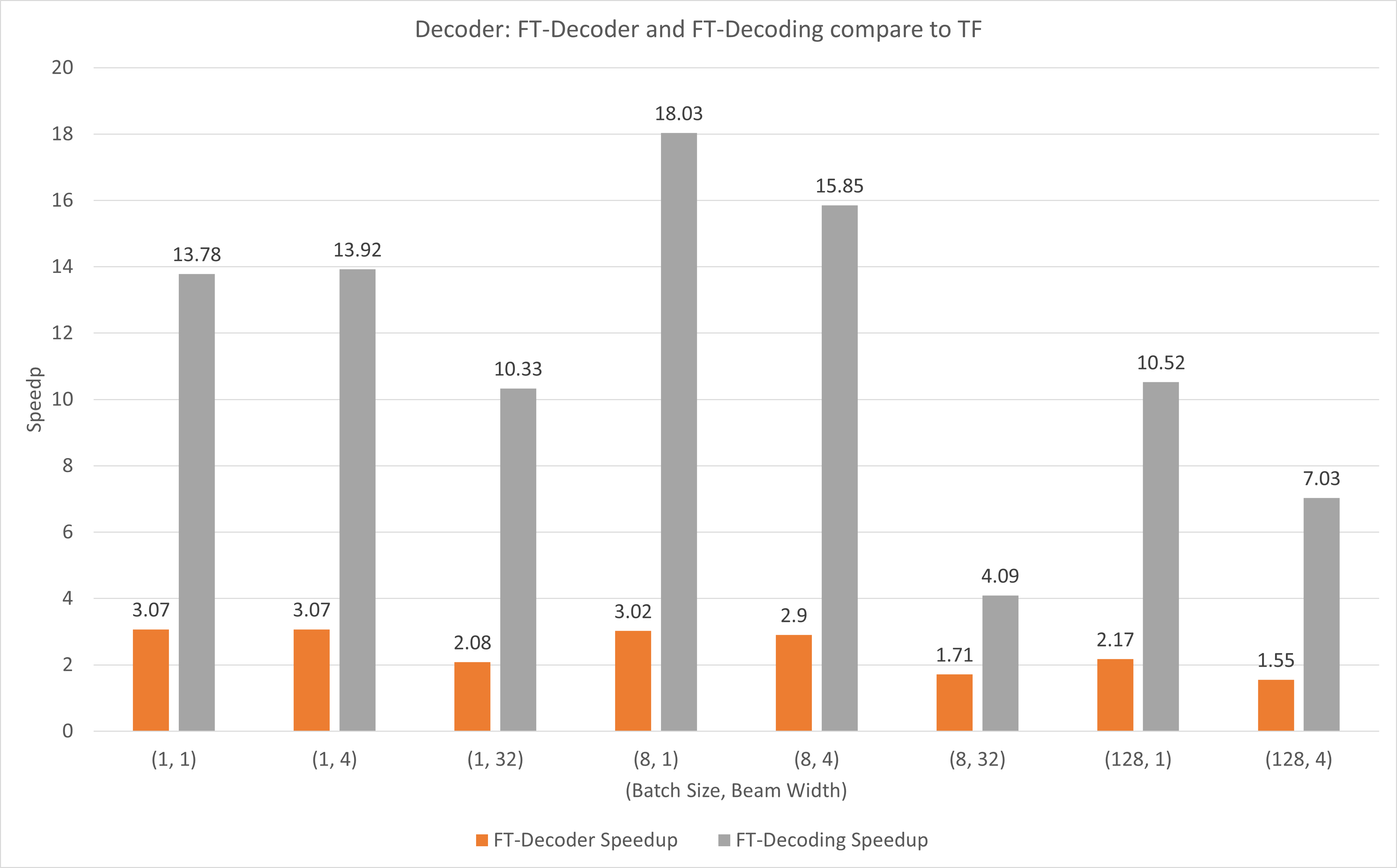
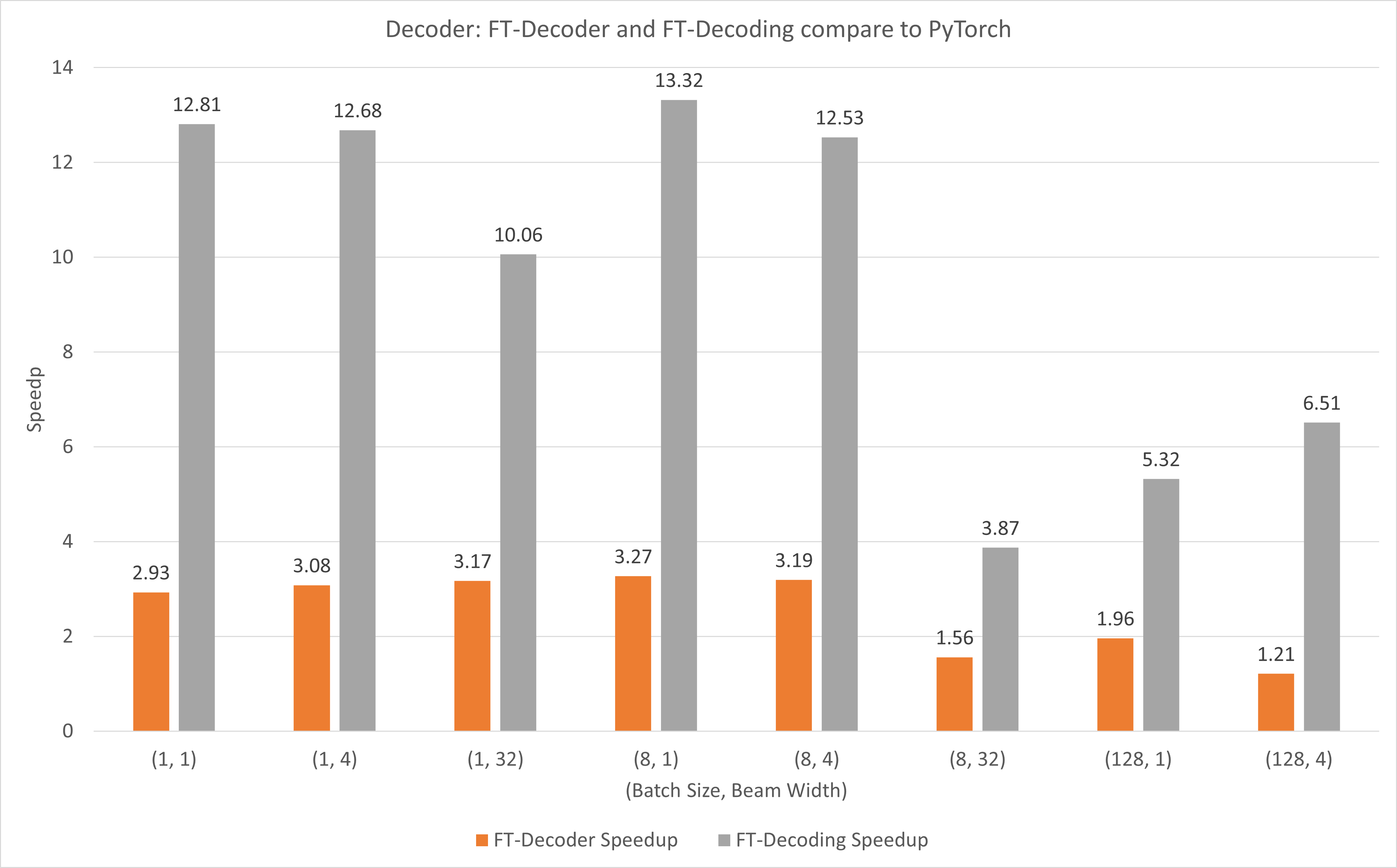
La figure suivante montre l'accélération des opérations FT-Decoder et FT-Decoding par rapport à TensorFlow sous FP16 avec T4. Ici, nous utilisons le débit de traduction d'un ensemble de tests pour éviter que le nombre total de jetons de chaque méthode ne soit différent. Par rapport à TensorFlow, FT-Decoder offre une accélération de 1,5x à 3x ; tandis que le décodage FT offre une accélération de 4x à 18x.
La figure suivante montre l'accélération de l'opération FT-Decoder et de l'opération FT-Decoding par rapport à PyTorch sous FP16 avec T4. Ici, nous utilisons le débit de traduction d'un ensemble de tests pour éviter que le nombre total de jetons de chaque méthode ne soit différent. Par rapport à PyTorch, FT-Decoder offre une accélération de 1,2x à 3x ; tandis que le décodage FT offre une accélération de 3,8x ~ 13x.
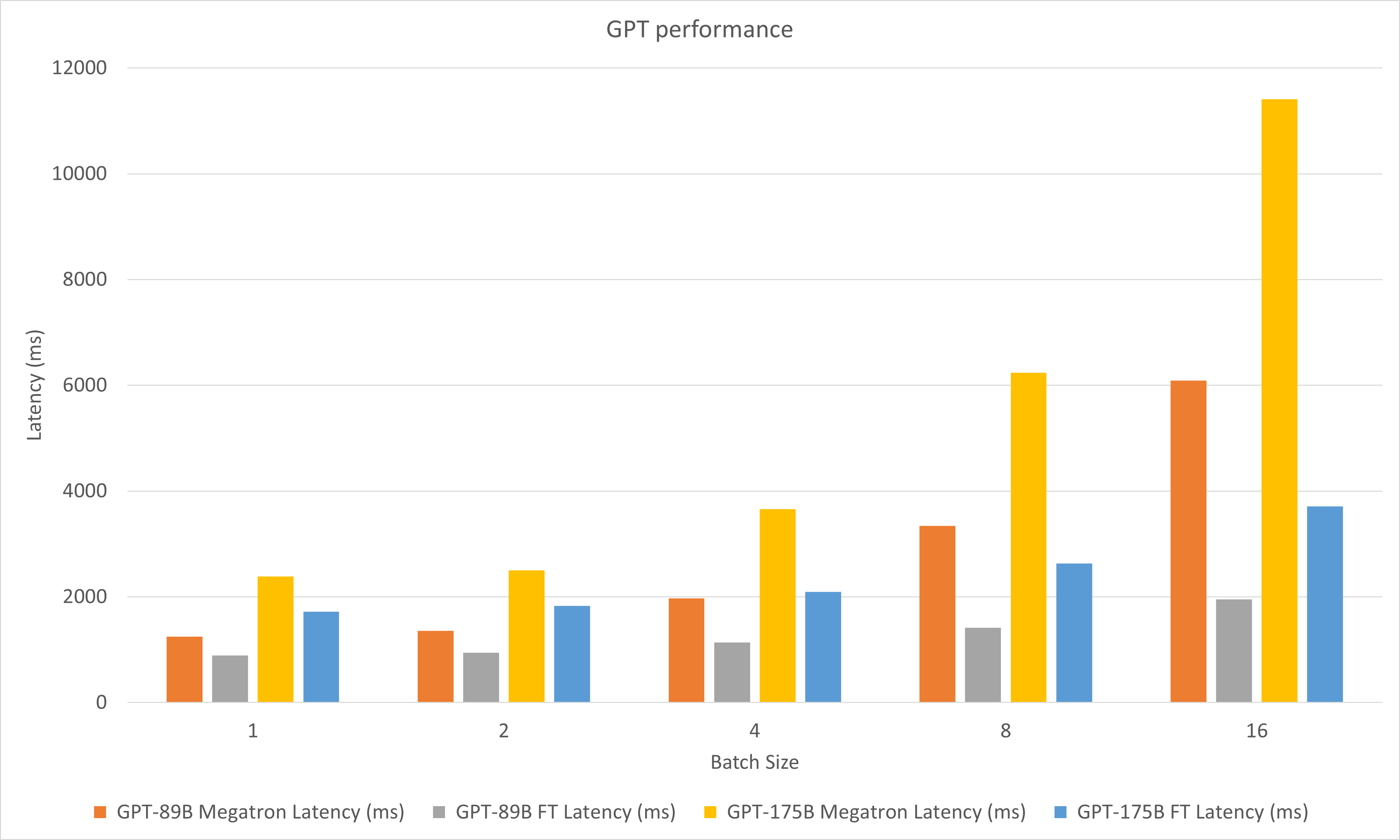
La figure suivante compare les performances de Megatron et FasterTransformer sous FP16 sur A100.
Dans les expériences de décodage, nous avons mis à jour les paramètres suivants :
mai 2023
janvier 2023
décembre 2022
novembre 2022
octobre 2022
septembre 2022
août 2022
juillet 2022
juin 2022
mai 2022
avril 2022
mars 2022
stop_ids et ban_bad_ids dans GPT-J.start_id et end_id dans GPT-J, GPT, T5 et Decoding.Février 2022
décembre 2021
novembre 2021
août 2021
layer_para en pipeline_para .size_per_head 96, 160, 192, 224, 256 pour le modèle GPT.juin 2021
avril 2021
décembre 2020
novembre 2020
septembre 2020
août 2020
juin 2020
mai 2020
translate_sample.py .avril 2020
decoding_opennmt.h en decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h , bert_transformer_op.cu.cc dans bert_transformer_op.ccdecoder.h , decoder.cu.cc dans decoder.ccdecoding_beamsearch.h , decoding_beamsearch.cu.cc dans decoding_beamsearch.ccbleu_score.py dans utils . Notez que le score BLEU nécessite python3.mars 2020
translate_sample.py pour montrer comment traduire une phrase en restaurant le modèle pré-entraîné d'OpenNMT-tf.Février 2020
juillet 2019
import torch . Si cela a été fait, cela est dû à l'ABI C++ incompatible. Vous devrez peut-être vérifier que le PyTorch utilisé lors de la compilation et de l'exécution est le même, ou vous devrez vérifier comment votre PyTorch est compilé, ou la version de votre GCC, etc.

