PatrickStar
v0.4.6

Voir CHANGE_LOG.md.
Les modèles pré-entraînés (PTM) deviennent le point chaud de la recherche en PNL et de ses applications industrielles. Cependant, la formation des PTM nécessite d’énormes ressources matérielles, ce qui la rend accessible uniquement à une petite partie des personnes de la communauté de l’IA. Désormais, PatrickStar rendra la formation PTM accessible à tous !
L'erreur de mémoire insuffisante (MOO) est le cauchemar de tout ingénieur formant des PTM. Nous devons souvent introduire davantage de GPU pour stocker les paramètres du modèle afin d'éviter de telles erreurs. PatrickStar apporte une meilleure solution à ce problème. Avec la formation hétérogène (DeepSpeed Zero Stage 3 l'utilise également), PatrickStar pourrait utiliser pleinement la mémoire CPU et GPU afin que vous puissiez utiliser moins de GPU pour entraîner des modèles plus grands.
L'idée de Patrick est la suivante. Les données non-modèles (principalement les activations) varient au cours de la formation, mais les solutions de formation hétérogènes actuelles divisent statiquement les données du modèle en CPU et GPU. Pour mieux utiliser le GPU, PatrickStar propose une planification dynamique de la mémoire à l'aide d'un module de gestion de la mémoire basé sur des chunks. La gestion de la mémoire de PatrickStar prend en charge le déchargement de tout, sauf la partie informatique actuelle du modèle, vers le CPU pour économiser le GPU. De plus, la gestion de la mémoire basée sur des blocs est efficace pour la communication collective lors de la mise à l'échelle vers plusieurs GPU. Voir l'article et ce document pour l'idée derrière PatrickStar.
En expérience, Patrickstar v0.4.3 est capable de former un modèle de paramètres de 18 milliards (18 Go) avec 8 GPU Tesla V100 et 240 Go de mémoire GPU dans le nœud du centre de données WeChat, dont la topologie du réseau est la suivante. PatrickStar est plus de deux fois plus grand que DeepSpeed. Et les performances de PatrickStar sont également meilleures pour les modèles de même taille. Le pstar est PatrickStar v0.4.3. Les profondeurs indiquent les performances de DeepSpeed v0.4.3 en utilisant l'exemple officiel DeepSpeed, exemple d'étape zéro3 avec des optimisations d'activation ouvertes par défaut.

Nous avons également évalué PatrickStar v0.4.3 sur un seul nœud du SuperPod A100. Il peut entraîner un modèle 68B sur 8xA100 avec 1 To de mémoire CPU, soit plus de 6 fois plus grande que DeepSpeed v0.5.7. Outre l'échelle du modèle, PatrickStar est bien plus efficace que DeepSpeed. Les scripts de référence sont ici.

Des résultats de référence détaillés sur le centre de données WeChat AI et NVIDIA SuperPod sont publiés sur ce document Google.
Adaptez PatrickStar à plusieurs machines (nœuds) sur SuperPod. Nous réussissons à entraîner un GPT3-175B sur 32 GPU. À notre connaissance, il s’agit du premier travail permettant d’exécuter GPT3 sur un si petit cluster GPU. Microsoft a utilisé 10 000 V100 pour appartenir à GPT3. Vous pouvez désormais le peaufiner ou même pré-entraîner le vôtre sur 32 GPU A100, incroyable !

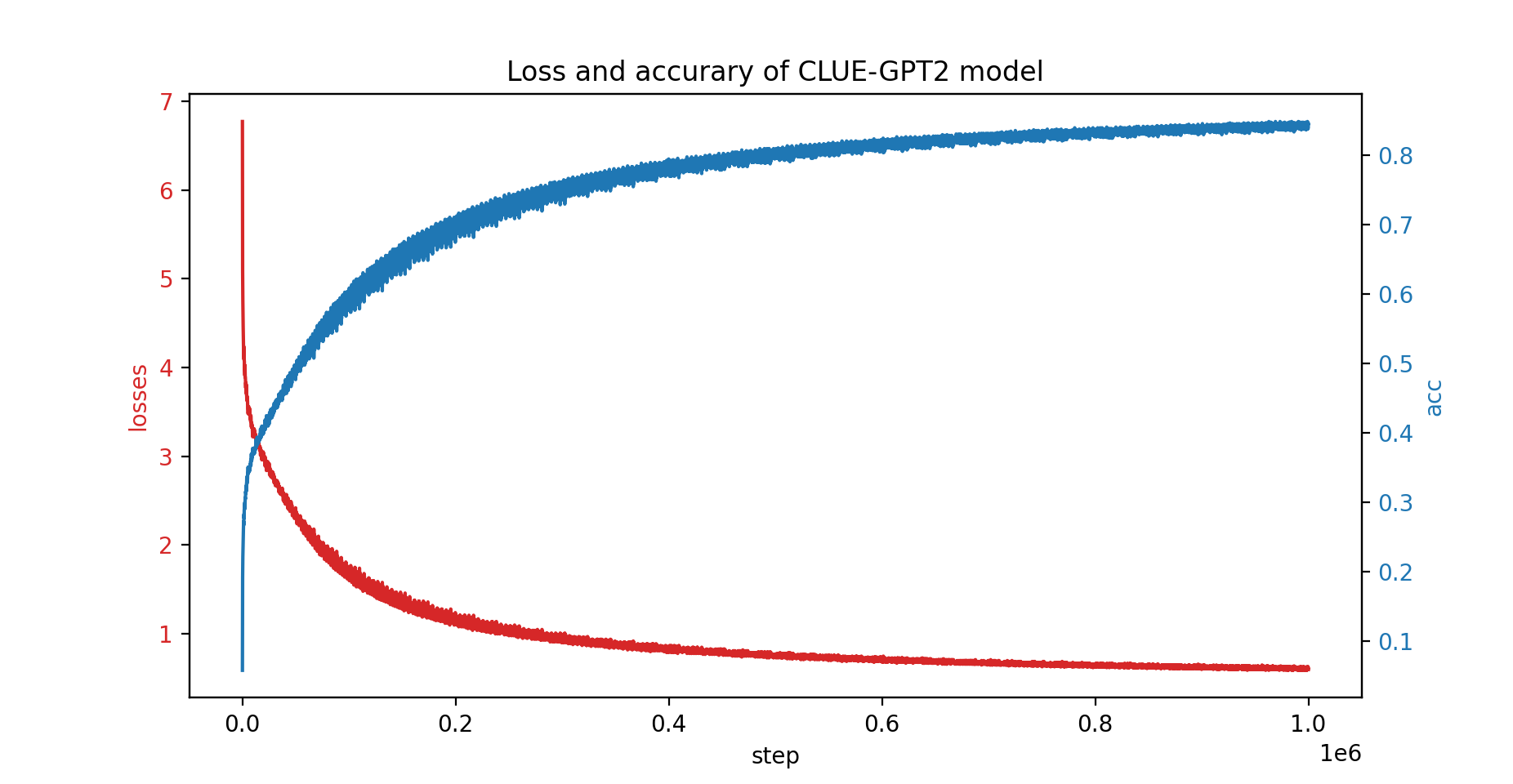
Nous avons également entraîné le modèle CLUE-GPT2 avec PatrickStar, la courbe de perte et de précision est présentée ci-dessous :
pip install .Notez que PatrickStar nécessite gcc de version 7 ou supérieure. Vous pouvez également utiliser des images NVIDIA NGC, l'image suivante est testée :
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar est basé sur PyTorch, ce qui facilite la migration d'un projet pytorch. Voici un exemple de PatrickStar :
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Nous utilisons le même format config que la configuration JSON de DeepSpeed, qui comprend principalement les paramètres de l'optimiseur, du scaler de perte et une configuration spécifique à PatrickStar.
Pour une explication détaillée de l'exemple ci-dessus, veuillez consulter le guide ici
Pour plus d’exemples, veuillez vérifier ici.
Un script de référence de démarrage rapide est ici. Il est exécuté avec des données générées aléatoirement ; vous n'avez donc pas besoin de préparer les données réelles. Il a également démontré toutes les techniques d'optimisation de Patrickstar. Pour plus d’astuces d’optimisation exécutant le benchmark, consultez Options d’optimisation.
Licence BSD à 3 clauses
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
Propulsé par l'équipe WeChat AI, Tencent NLP Oteam.


