FinGLM
1.0.0
Lien vers les questions du concours | Page de promotion des questions du concours
? FinGLM : Engagé dans la construction d'un grand projet de modèle financier ouvert, de bien-être public et durable, utilisant l'open source pour promouvoir « IA + finance ».
[Mise à jour du 23/11/2023] Ajout du contenu du cours pour les modèles ChatGLM-6B de 1ère, 2ème et 3ème génération, y compris des PPT, des vidéos et des documents techniques.
【Mise à jour du 17/11/2023】Ajout d'une nouvelle solution "Nommez-le comme bon vous semble"
? Un système intelligent interactif conversationnel conçu pour analyser en profondeur les rapports annuels des sociétés cotées. Face aux termes professionnels et aux informations implicites contenues dans les textes financiers, nous nous engageons à utiliser l’IA pour réaliser une analyse financière de niveau expert.
Dans le domaine de l’IA, même si des progrès ont été réalisés dans le dialogue textuel, les scénarios d’interaction financière réelle restent un énorme défi. Plusieurs institutions ont organisé conjointement ce concours pour explorer les limites de l'IA dans le domaine financier.
Le rapport annuel d'une société cotée présente aux investisseurs la situation opérationnelle, la situation financière et les projets futurs de l'entreprise. L'expertise est la clé de l'interprétation, et notre objectif est de rendre ce processus plus facile et plus précis grâce à la technologie de l'IA.
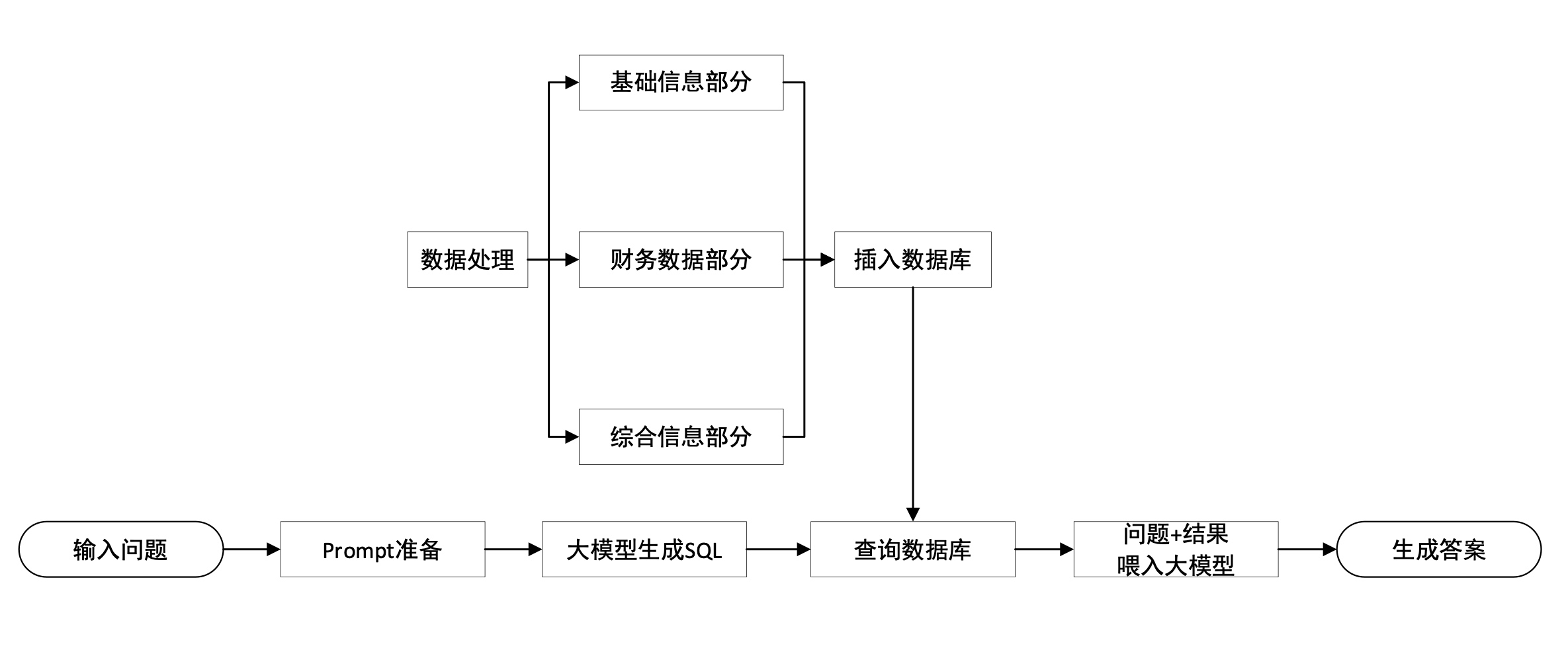
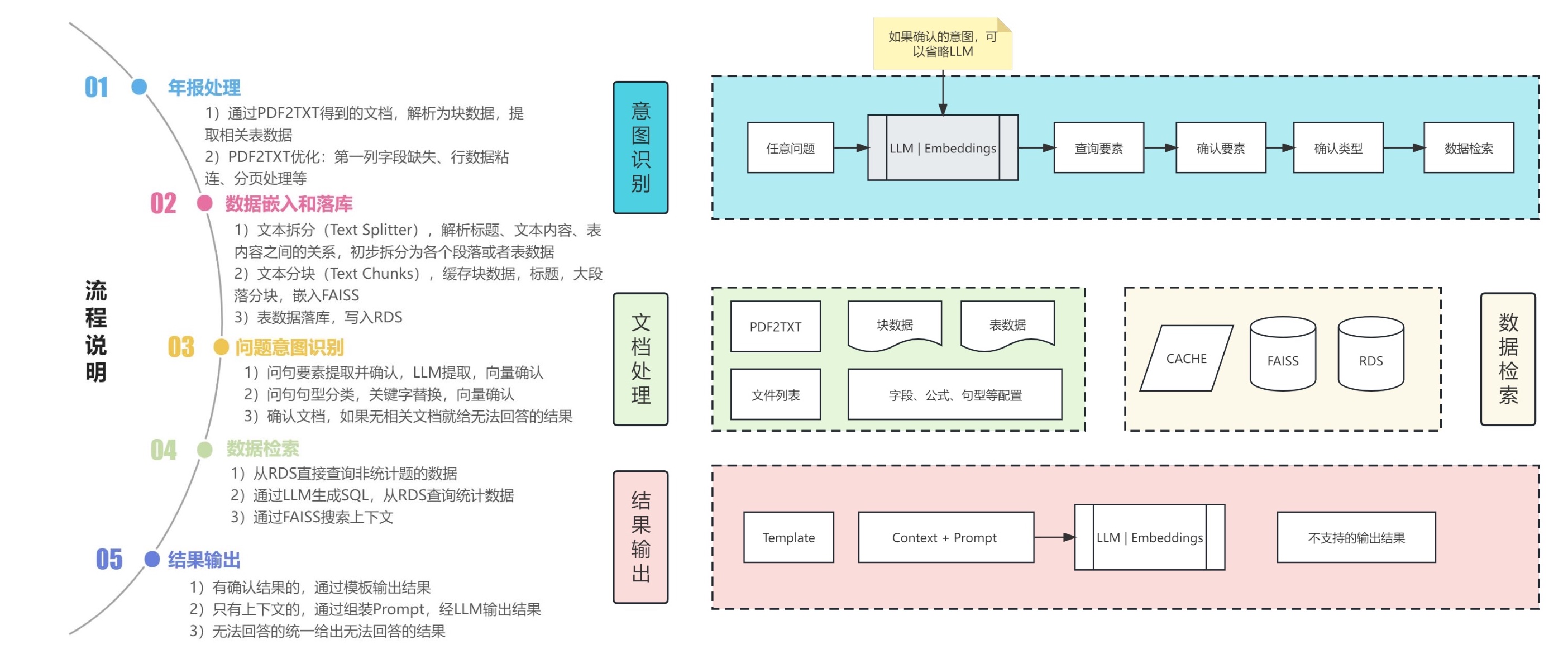
PDF vers TXT :
Segmentation des données :
Traitement des données :
Enregistrer dans la base de données :
Classification des données : telles que les données SQL, les données ES, etc.
Sélectionnez une stratégie de réglage fin : telle que ptuningv2, lora, etc.
Effectuer des réglages fins : en fonction de la stratégie sélectionnée.
1) Transformation d'événement
2) Données open source
3) Solutions/codes/modèles open source
4) Communication ouverte
5) Tutoriels d'étude
6) Pool de ressources du projet
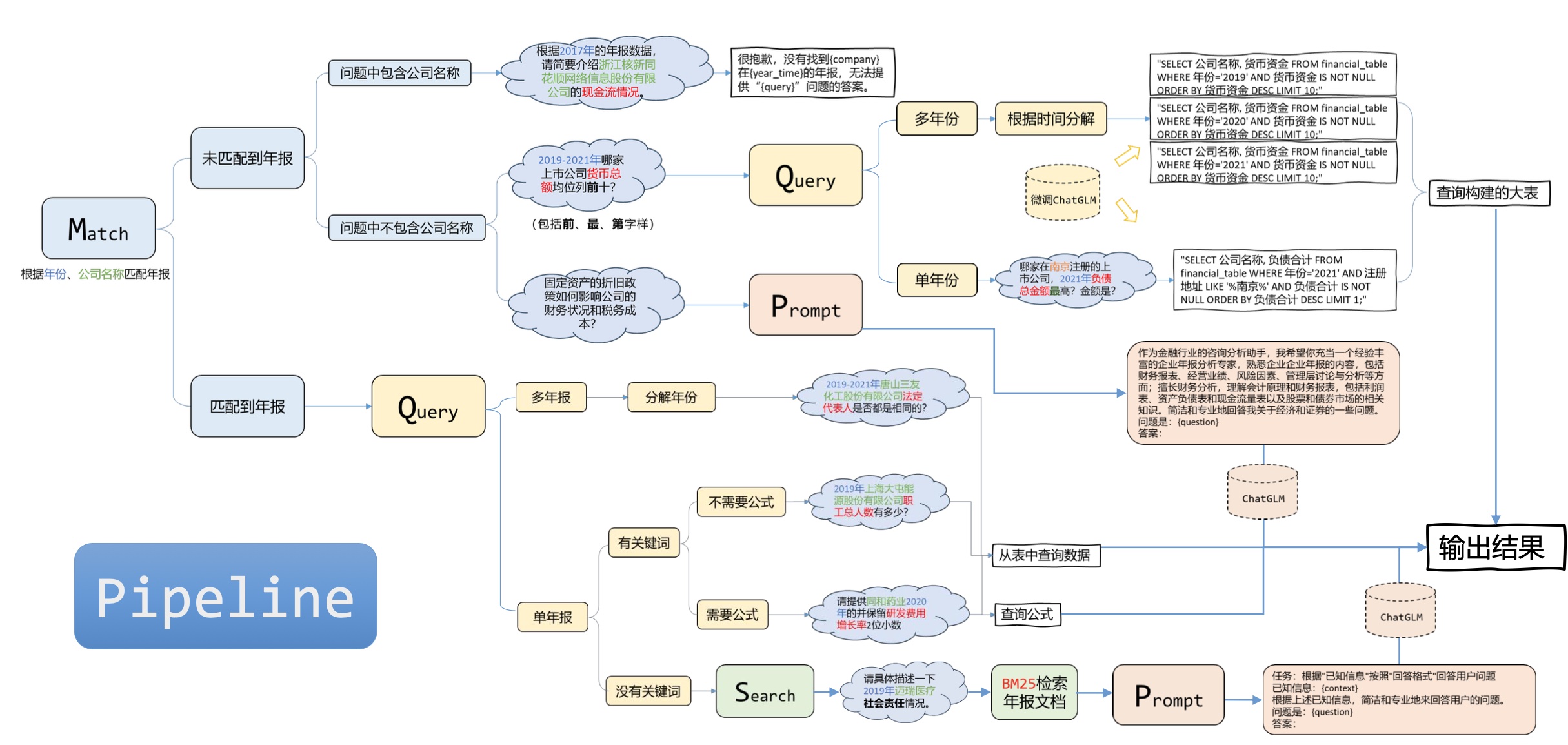
Premier problème :
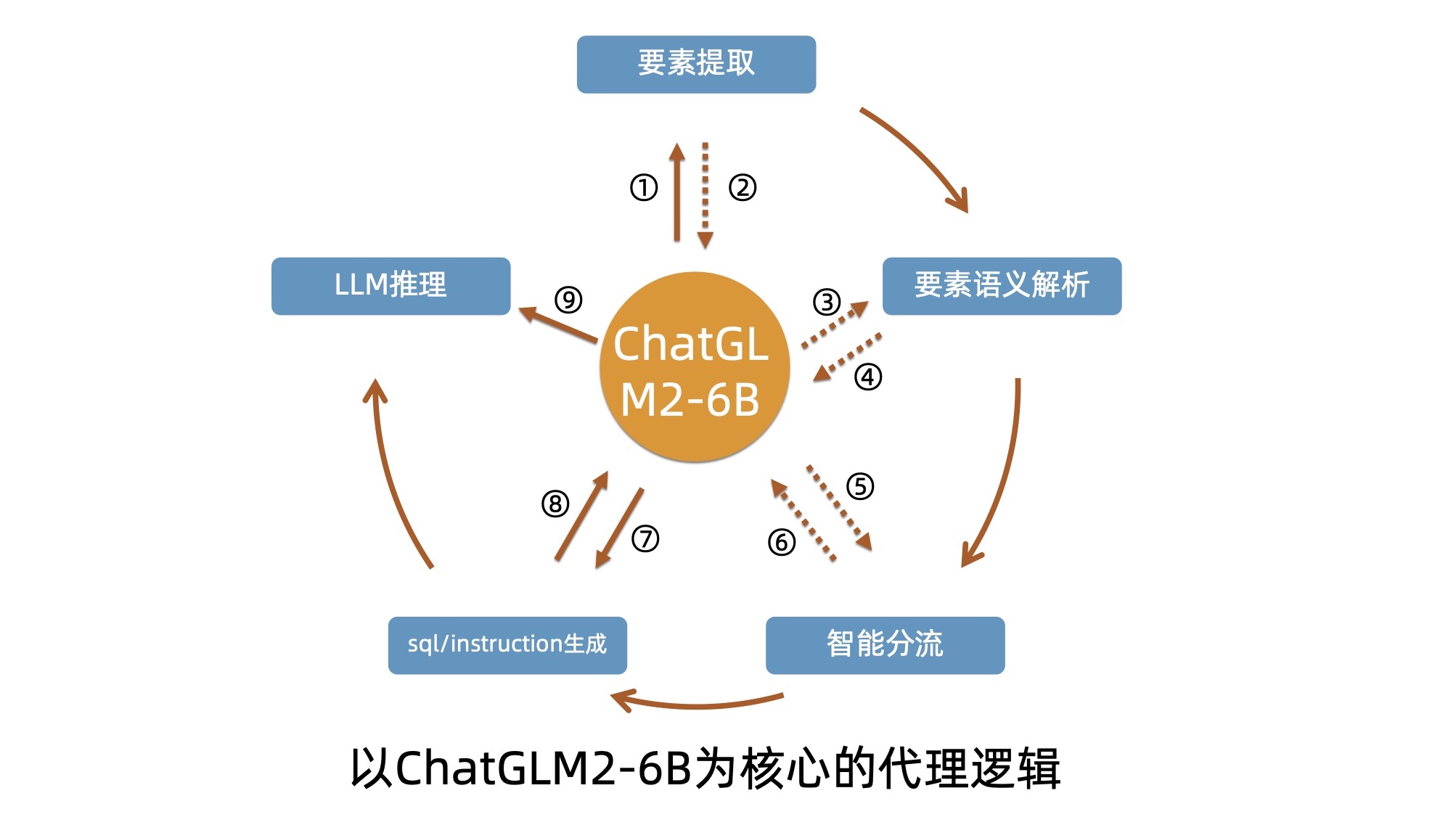
pdf2txt.py pour analyser les fichiers PDF. Deuxième problème :
Blog de présentation du projet :
[PPT] [Vidéo][Code]
Ce projet est une intégration de l'équipe Anshuoshuo Eye Exploration Enterprise basée sur son propre projet et les projets de plusieurs autres équipes. Nous continuerons à itérer et à mettre à niveau ce projet à l’avenir.
[PPT] [Vidéo] [Code] 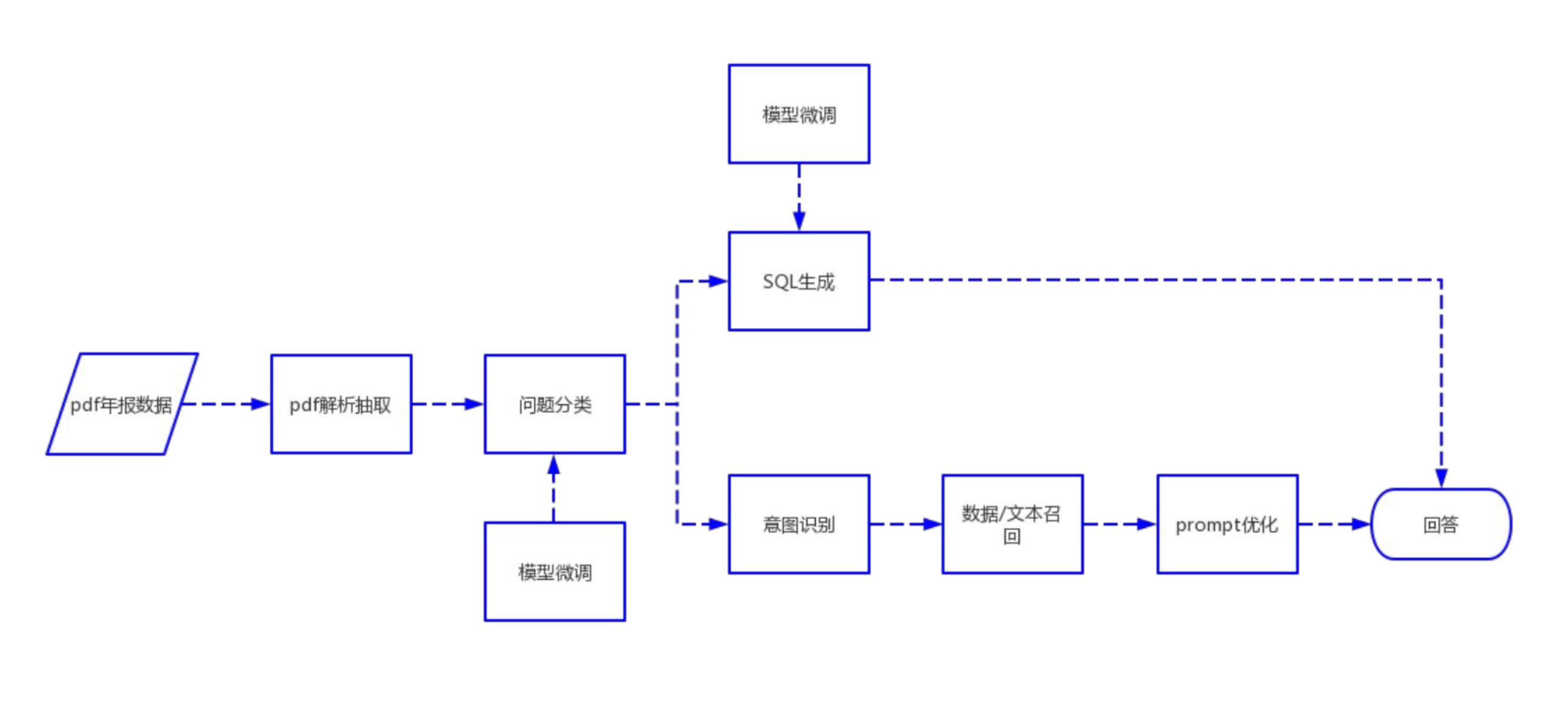
[PPT] [Vidéo] [Code]
[PPT] [Vidéo] [Code]
[PPT] [Vidéo] [Code]
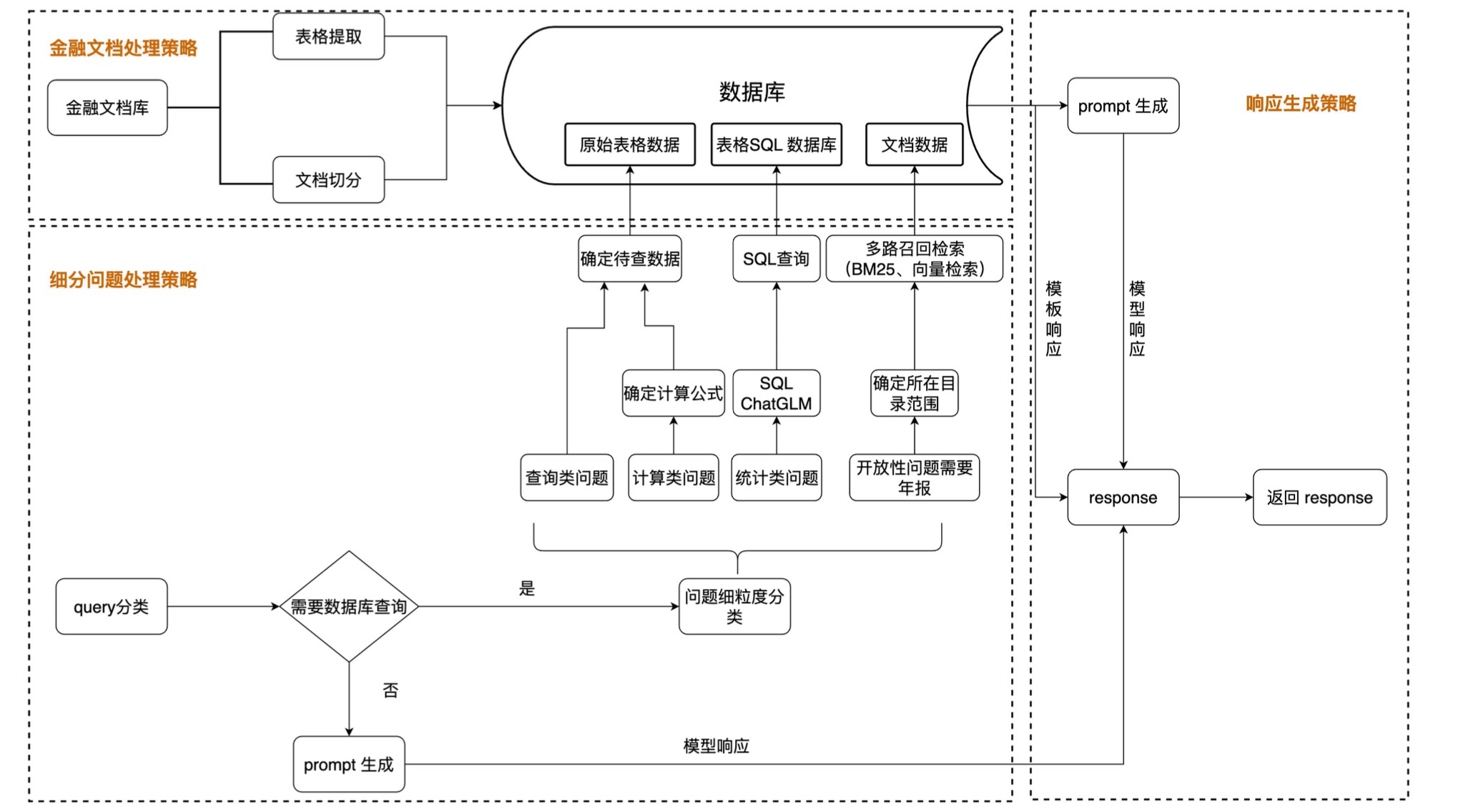
[PPT] [Vidéo] [Code]

[PPT] [Vidéo] [Code]
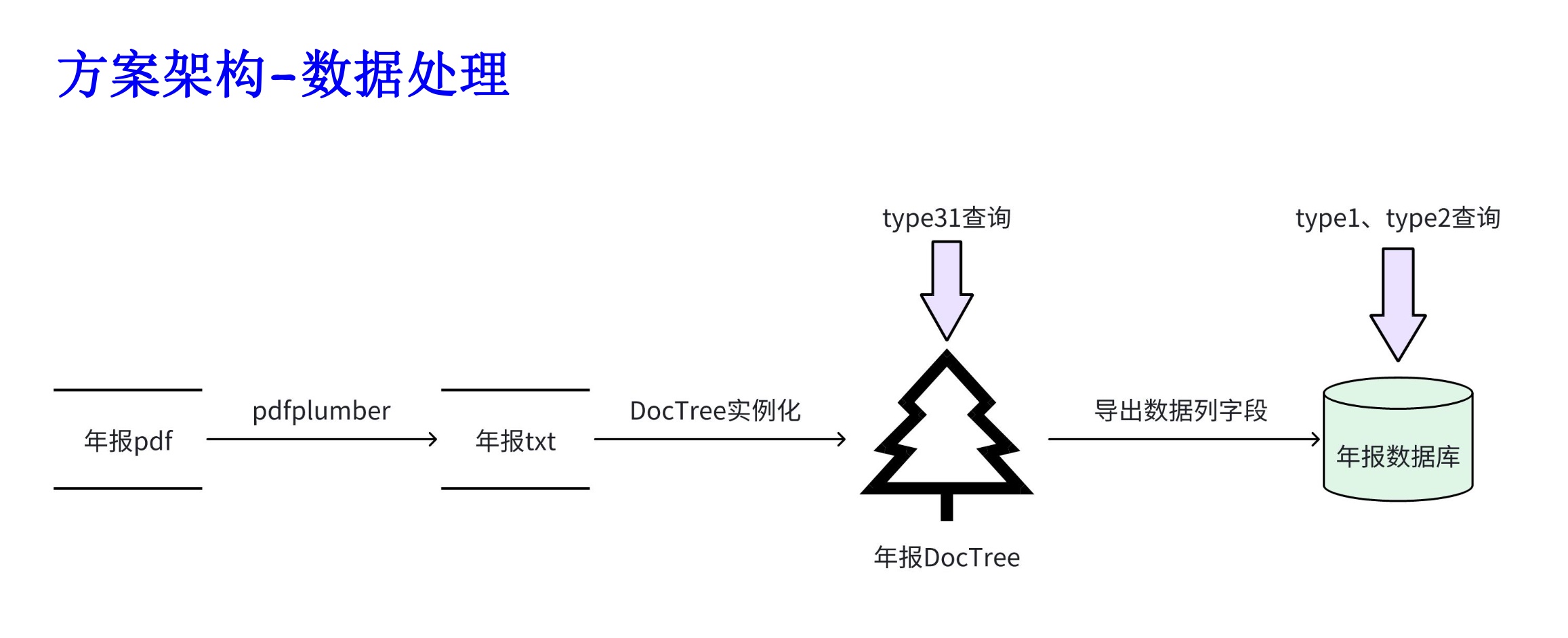
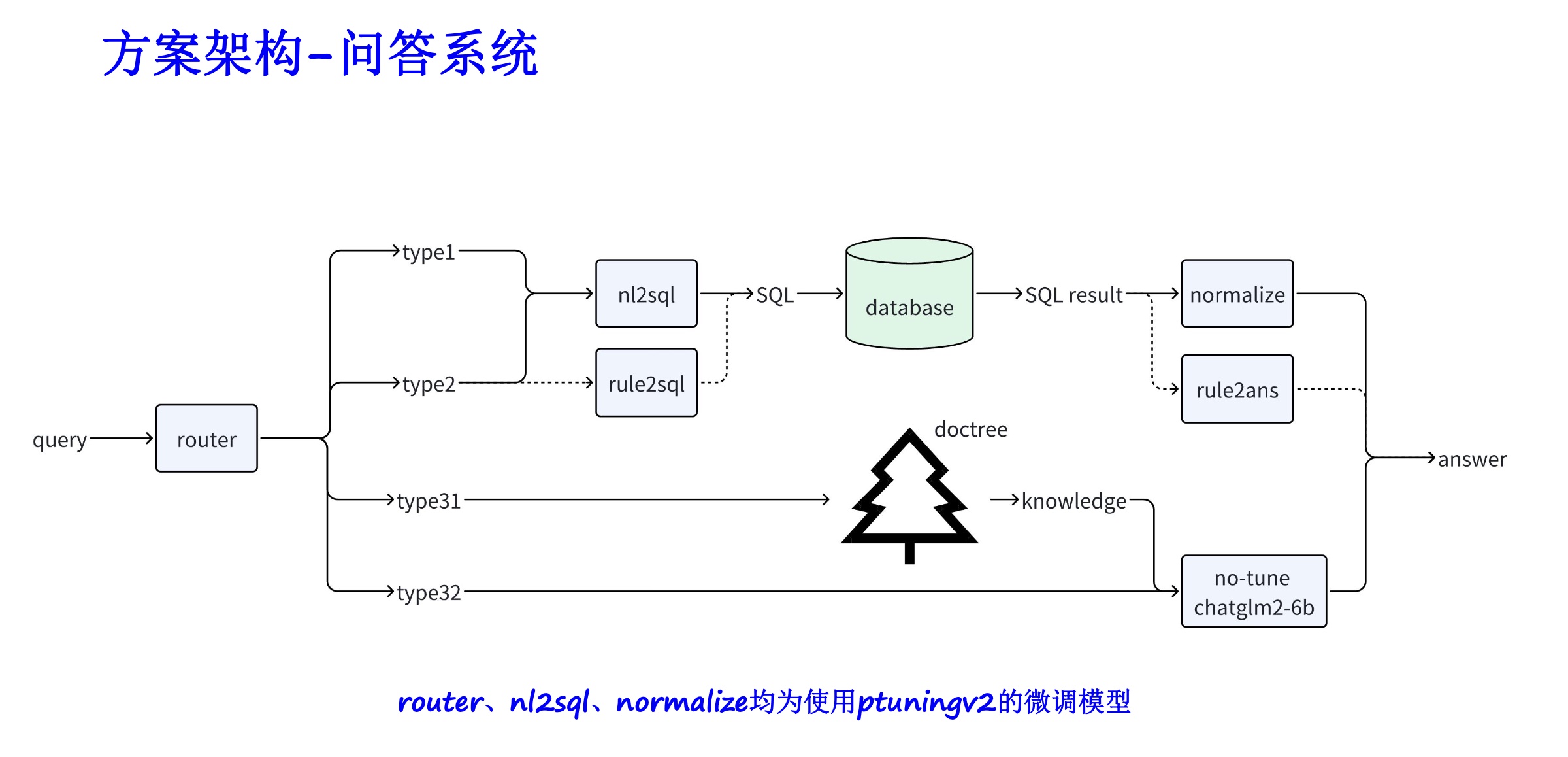
[PPT] [Vidéo] [Code]
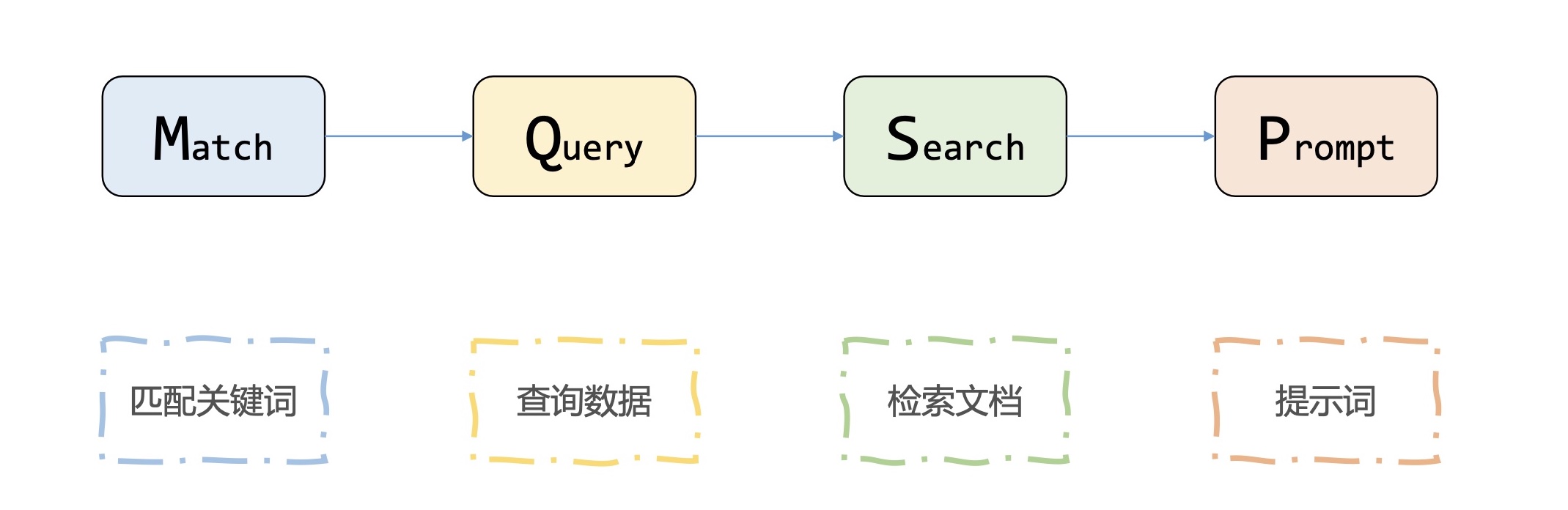
[PPT] [Vidéo] [Code]
[PPT] [Vidéo] [Code]
[PPT] [Vidéo][Code]
Notre ensemble de données open source couvre les rapports annuels de certaines sociétés cotées de 2019 à 2021. Cet ensemble de données contient un total de 11 588 fichiers PDF détaillés (liste). Vous pouvez utiliser le contenu de ces fichiers PDF pour créer la base de données ou la bibliothèque vectorielle dont vous avez besoin. Afin d'éviter le gaspillage de ressources informatiques, nous convertissons également les fichiers correspondants en fichiers TXT et HTML accessibles à tous.
Taille : 69 Go Format de fichier : fichier pdf Nombre de fichiers : 11588
charge git
# 要求安装 git lfs
git clone http://www.modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset.git
chargement du SDK
# Note:
# 1. 【重要】请将modelscope sdk升级到v1.7.2rc0,执行: pip3 install "modelscope==1.7.2rc0" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 2. 【重要】datasets版本限制为 >=2.8.0, <=2.13.0,可执行: pip3 install datasets==2.13.0
from modelscope.msdatasets import MsDataset
# 使用流式方式加载「推荐」
# 无需全量加载到cache,随下随处理
# 其中,通过设置 stream_batch_size 可以使用batch的方式加载
ds = MsDataset.load('chatglm_llm_fintech_raw_dataset', split='train', use_streaming=True, stream_batch_size=1)
for item in ds:
print(item)
# 加载结果示例(单条,pdf:FILE字段值为该pdf文件本地缓存路径,文件名做了SHA转码,可以直接打开)
{'name': ['2020-03-24__北京鼎汉技术集团股份有限公司__300011__鼎汉技术__2019年__年度报告.pdf'], 'pdf:FILE': ['~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/430da7c46fb80d4d095a57b4fb223258ffa1afe8bf53d0484e3f2650f5904b5c']}
# 备注:
1. 自定义缓存路径,可以自行设置cache_dir参数,即 MsDataset.load(..., cache_dir='/to/your/path')
2. 补充数据加载(从9493条增加到11588条),sdk加载注意事项
a) 删除缓存中的csv映射文件(默认路径为): ~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/732dc4f3b18fc52380371636931af4c8
b) 使用MsDataset.load(...) 加载,默认会reuse已下载过的文件,不会重复下载。
Remarque : Convertissez le fichier PDF en fichier au format txt pour une réutilisation facile (un fichier est endommagé, le nombre total est donc 1 de moins que le fichier PDF, 11 587 au total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip -OutFile D:\alltxt.zip
Remarque : Convertissez les fichiers PDF au format HTML pour une réutilisation facile (un fichier est endommagé, le nombre total est donc inférieur au PDF, 11 582 au total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip -OutFile D:\allhtml.zip
Voici nos étapes recommandées :
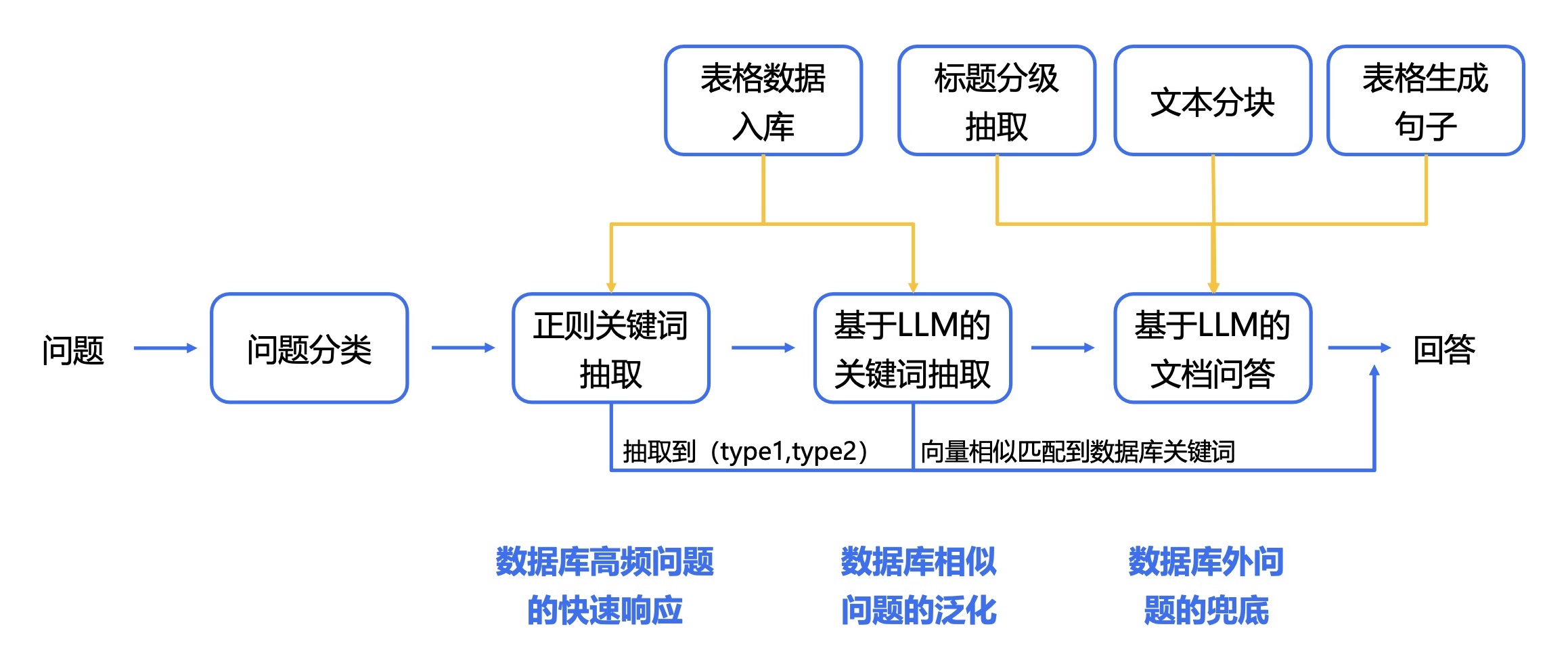
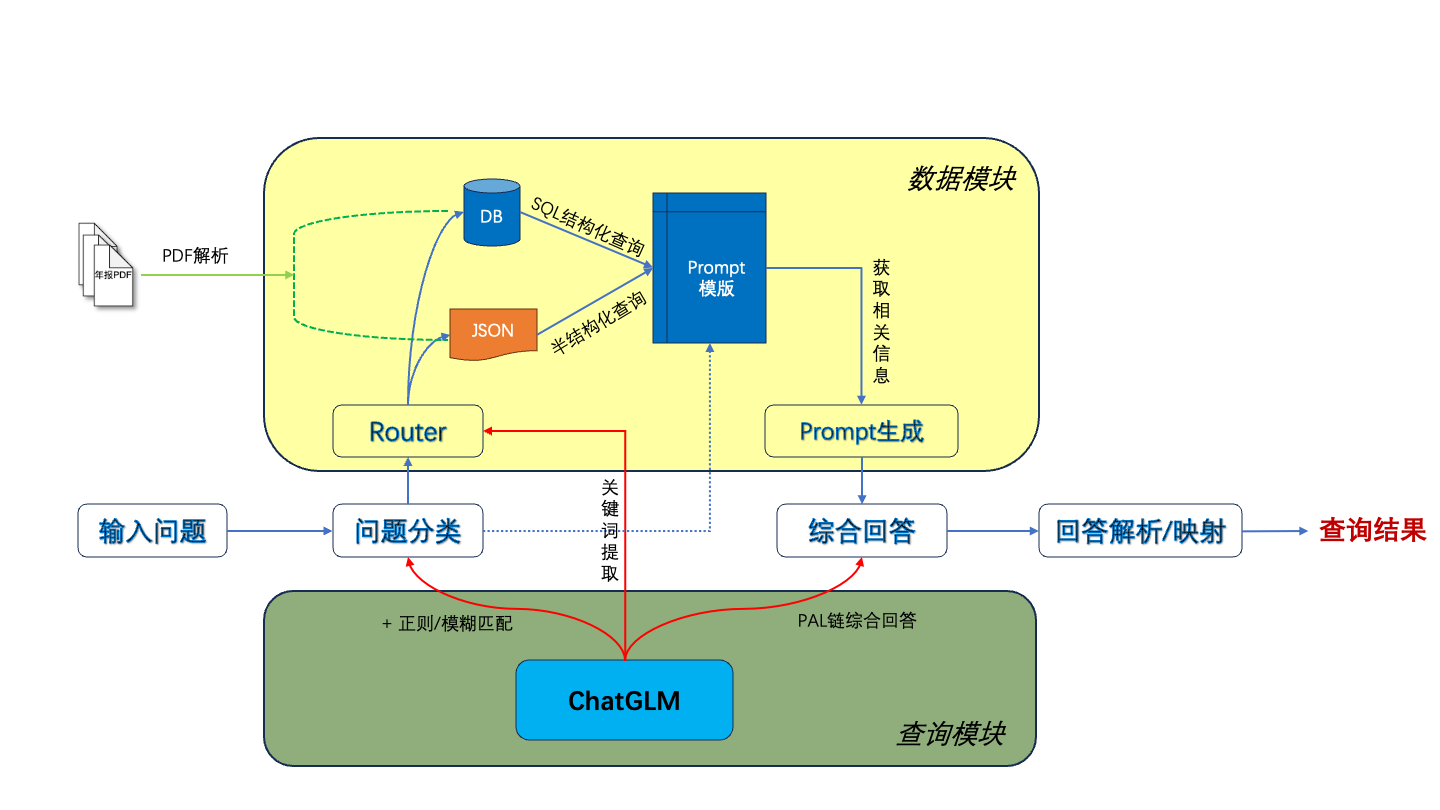
1. Extraction de texte et de tableau PDF : vous pouvez utiliser des boîtes à outils telles que pdfplumber et pdfminer pour extraire des données de texte et de tableau à partir de fichiers PDF.
2. Segmentation des données : selon les informations du répertoire, du sous-répertoire et du chapitre du fichier PDF, le contenu est segmenté avec précision.
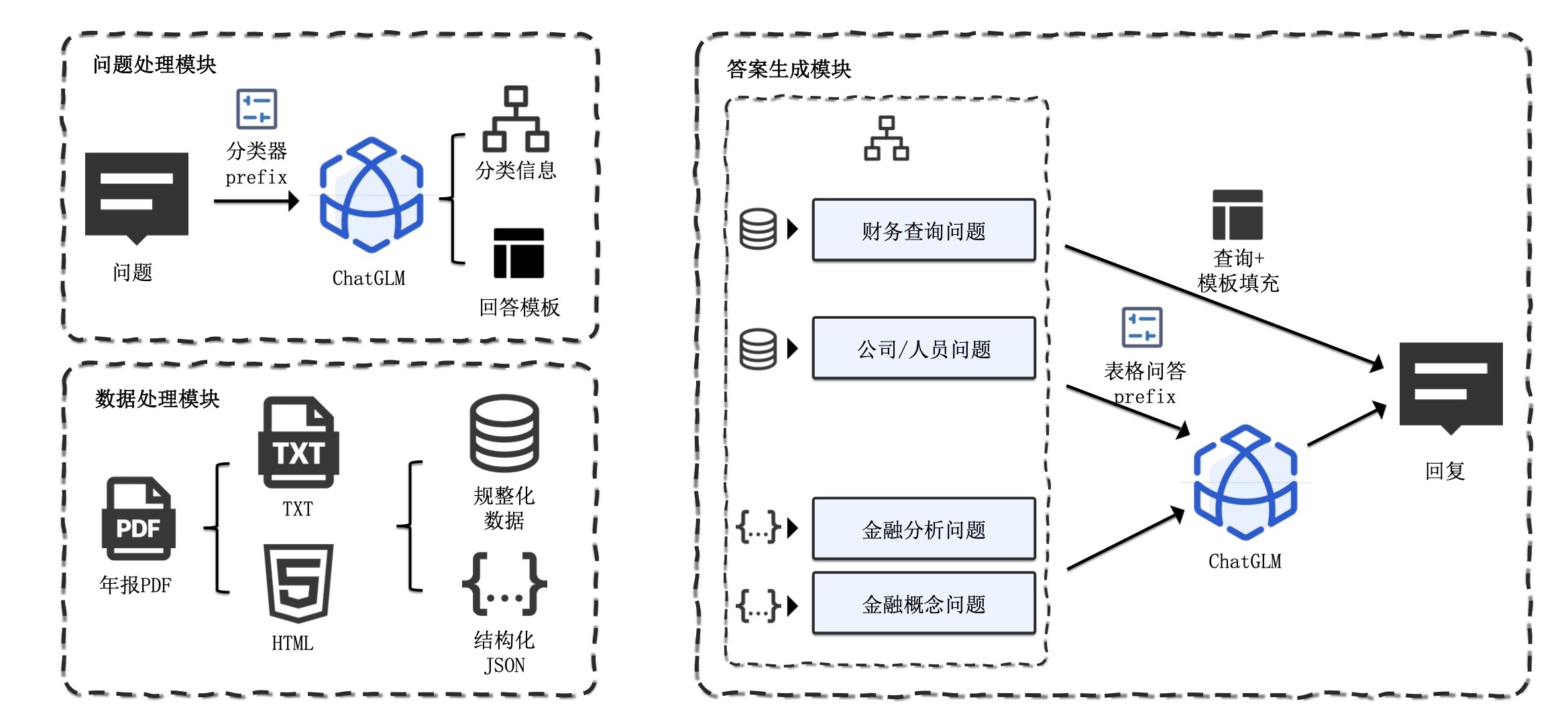
3. Créez une base de données financière de base : concevez des champs et des formats de bases de données financières professionnelles basés sur les connaissances financières et le contenu PDF. Par exemple, définissez le bilan, le tableau des flux de trésorerie, le compte de résultat, etc.
4. Extraction d'informations : utilisez les capacités d'extraction d'informations des grands modèles et de la technologie NLP pour extraire les informations du domaine financier correspondant. Par exemple, veuillez utiliser le mode json pour afficher le contenu du répertoire, avec le nom du chapitre comme clé et le numéro de page comme valeur. Dans le même temps, veuillez extraire les données du tableau en détail et les afficher au format JSON.
5. Construire une base de données de questions et réponses sur les connaissances financières : en combinaison avec la base de données financière construite, appliquer de grands modèles pour créer une base de données de questions et réponses financières de base. Par exemple,
{"question":"某公司2021年的财务费用为多少元?", "answer": "某公司2021年的财务费用为XXXX元。"}
prompt:用多种句式修改question及answer的内容。
{"question":"为什么财务费用可以是负的?", "answer": ""}
prompt:请模仿上面的question给出100个类似的问题与对应的答案,用json输出。
6. Créez une bibliothèque de vecteurs : à l'aide de technologies telles que Word2Vec et Text2Vec, les vecteurs sémantiques sont extraits des données textuelles originales. Utilisez pgvector, une extension basée sur PostgreSQL, pour stocker et indexer ces vecteurs afin de créer une bibliothèque de vecteurs à grande échelle qui peut être interrogée efficacement.
7. Application : combiné avec des bibliothèques vectorielles, de grands modèles, langchain et d'autres outils pour améliorer les effets d'application.
Dans le cadre du ChatGLM Financial Large Model Challenge SMP 2023, nous avons mené respectivement le tour préliminaire, la demi-finale A, la demi-finale B et la demi-finale C. Pour ces tours de concours, nous avons annoté manuellement les données pertinentes, avec un total de 10 000 entrées.
Exemple de données :
{ "ID" : 1 ,
"question" : "2019年中国工商银行财务费用是多少元?" ,
"answer" : "2019年中国工商银行财务费用是12345678.9元。" }
{ "ID" : 2 ,
"question" : "工商银行2019年营业外支出和营业外收入分别是多少元?" ,
"answer" : "工商银行2019年营业外支出为12345678.9元,营业外收入为2345678.9元。" }
{ "ID" : 3 ,
"question" : "中国工商银行2021年净利润增长率是多少?保留2位小数。" ,
"answer" : "中国工商银行2020年净利润为12345678.90元,2021年净利润为22345678.90元,根据公式,净利润增长率=(净利润-上年净利润)/上年净利润,得出结果中国工商银行2021年净利润增长率81.00%。" }Parallèlement, nous avons également rédigé un code de révision pour le concours. Nous nous appuyons sur :
Exemple d'évaluation :
{ "question" : "2019年中国工商银行财务费用是多少元?" ,
"prompt" : { "财务费用" : "12345678.9元" , "key_word" : "财务费用、2019" , "prom_answer" : "12345678.9元" },
"answer" : [
"2019年中国工商银行财务费用是12345678.9元。" ,
"2019年工商银行财务费用是12345678.9元。" ,
"中国工商银行2019年的财务费用是12345678.9元。" ]
}Exemple de calcul d'évaluation :
Réponse 1 : Les dépenses financières de l'ICBC en 2019 s'élèvent à 123 456 78,9 yuans.
phrases les plus similaires :
Les dépenses financières de l'ICBC en 2019 s'élevaient à 1 2345678,9 yuans. (Note : 0,9915)
Les dépenses financières de la Banque industrielle et commerciale de Chine en 2019 se sont élevées à 1 234 5678,9 yuans. (Note : 0,9820)
Les dépenses financières de la Banque industrielle et commerciale de Chine en 2019 se sont élevées à 1 234 5678,9 yuans. (Note : 0,9720)
Note : 0,25+0,25+0,9915*0,5=0,9958 points.
Explication de la notation : prom_answer est correct, contient tous les mots-clés et présente la similarité la plus élevée de 0,9915.
Réponse 2 : Les dépenses financières de l'ICBC en 2019 s'élèvent à 335 768,91 yuans.
Note : 0 point.
Explication de la notation : les erreurs Prom_answer ne sont pas notées.
Troisième réponse : 12345678,9 yuans.
phrases les plus similaires :
Les dépenses financières de l'ICBC en 2019 s'élevaient à 1 2345678,9 yuans. (Note : 0,6488)
Les dépenses financières de la Banque industrielle et commerciale de Chine en 2019 se sont élevées à 1 234 5678,9 yuans. (Note : 0,6409)
Les dépenses financières de la Banque industrielle et commerciale de Chine en 2019 se sont élevées à 1 234 5678,9 yuans. (Note : 0,6191)
Note : 0,25+0+0,6488*0,5=0,5744 points.
Explication de la notation : prom_answer est correct, ne contient pas tous les mots-clés et présente la similarité la plus élevée de 0,6488.
{ "id" : 0 , "question" : "2021年其他流动资产第12高的是哪家上市公司?" , "answer" : "2021年其他流动资产第12高的公司是苏美达股份有限公司。" }
{ "id" : 1 , "question" : "注册地址在重庆的上市公司中,2021年营业收入大于5亿的有多少家?" , "answer" : "2021年注册在重庆,营业收入大于5亿的公司一共有4家。" }
{ "id" : 2 , "question" : "广东华特气体股份有限公司2021年的职工总人数为?" , "answer" : "2021年广东华特气体股份有限公司职工总人数是1044人。" }
{ "id" : 3 , "question" : "在保留两位小数的情况下,请计算出金钼股份2019年的流动负债比率" , "answer" : "2019金钼股份流动负债比率是61.10%。其中流动负债是1068418275.97元;总负债是1748627619.69元;" }
{ "id" : 4 , "question" : "2019年负债总金额最高的上市公司为?" , "answer" : "2019年负债合计最高的是上海汽车集团股份有限公司。" }
{ "id" : 5 , "question" : "2019年总资产最高的前五家上市公司是哪些家?" , "answer" : "2019年资产总计最高前五家是上海汽车集团股份有限公司、中远海运控股股份有限公司、国投电力控股股份有限公司、华域汽车系统股份有限公司、广州汽车集团股份有限公司。" }
{ "id" : 6 , "question" : "2020年营业收入最高的3家并且曾经在宁波注册的上市公司是?金额是?" , "answer" : "注册在宁波,2020年营业收入最高的3家是宁波均胜电子股份有限公司营业收入47889837616.15元;宁波建工股份有限公司营业收入19796854240.57元;宁波继峰汽车零部件股份有限公司营业收入15732749552.37元。" }
{ "id" : 7 , "question" : "注册地址在苏州的上市公司中,2020年利润总额大于5亿的有多少家?" , "answer" : "2020年注册在苏州,利润总额大于5亿的公司一共有2家。" }
{ "id" : 8 , "question" : "浙江运达风电股份有限公司在2019年的时候应收款项融资是多少元?" , "answer" : "2019年浙江运达风电股份有限公司应收款项融资是51086824.07元。" }
{ "id" : 9 , "question" : "神驰机电股份有限公司2020年的注册地址为?" , "answer" : "2020年神驰机电股份有限公司注册地址是重庆市北碚区童家溪镇同兴北路200号。" }
{ "id" : 10 , "question" : "2019年山东惠发食品股份有限公司营业外支出和营业外收入分别是多少元?" , "answer" : "2019年山东惠发食品股份有限公司营业外收入是1018122.97元;营业外支出是2513885.46元。" }
{ "id" : 11 , "question" : "福建广生堂药业股份有限公司2020年年报中提及的财务费用增长率具体是什么?" , "answer" : "2020福建广生堂药业股份有限公司财务费用增长率是34.33%。其中,财务费用是7766850.48元;上年财务费用是5781839.51元。" }
{ "id" : 12 , "question" : "华灿光电股份有限公司2021年的法定代表人与上年相比相同吗?" , "answer" : "不相同,华灿光电股份有限公司2020年法定代表人是俞信华,2021年法定代表人是郭瑾。" }
{ "id" : 13 , "question" : "请具体描述一下2020年仲景食品控股股东是否发生变更。" , "answer" : "2020年,仲景食品控股股东没有发生变更。" }
{ "id" : 14 , "question" : "什么是其他债权投资?" , "answer" : "其他债权投资是指企业或机构投资者通过购买债券、贷款、定期存款等金融产品获得的固定收益。这些金融产品通常由政府、公司或其他机构发行,具有一定的信用等级和风险。 n n其他债权投资是企业或机构投资组合中的一部分,通常用于稳定收益和分散风险。与股票投资相比,其他债权投资的风险较低,但收益也相对较低。 n n其他债权投资的管理和投资策略与其他资产类别类似,包括分散投资、风险控制、收益最大化等。然而,由于其他债权投资的种类繁多,其投资和管理也存在一定的特殊性。" }[PPT] [Vidéo][Documentation technique]
[PPT] [Vidéo][Documentation technique]
[PPT] [Vidéo][Documentation technique]
Voici les équipes et les individus qui ont contribué à ce projet :
Le projet open source FinGLM est entièrement destiné à des fins de bien-être public et tous les développeurs sont invités à postuler pour y participer. Bien entendu, nous procéderons à un examen strict. Si vous êtes intéressé, veuillez remplir le formulaire.
Les ressources liées à ce projet sont uniquement destinées à la recherche et à la communication, et ne sont généralement pas recommandées pour un usage commercial. En cas d'utilisation à des fins commerciales, veuillez supporter les risques juridiques qui en découlent.
Lorsqu'il s'agit d'utilisation commerciale de modèles, veillez à suivre les protocoles des modèles concernés, tels que ChatGLM-6B.





