mengzi retrieval lm
1.0.0
Chez Langboat Technology, nous nous concentrons sur l'amélioration des modèles pré-entraînés pour les rendre plus légers afin de répondre aux besoins réels de l'industrie. Une approche basée sur la récupération (comme RETRO, REALM et RAG) est cruciale pour atteindre cet objectif.
Ce référentiel est une implémentation expérimentale du modèle de langage amélioré par la récupération. Actuellement, il ne prend en charge que l'ajustement de récupération sur GPT-Neo.
Nous avons créé Huggingface Transformers et lm-evaluation-harness pour ajouter la prise en charge de la récupération. La partie indexation est implémentée en tant que serveur HTTP pour mieux découpler la récupération et la formation.
La plupart de l'implémentation du modèle est copiée de RETRO-pytorch et GPT-Neo. Nous utilisons transformers-cli pour ajouter un nouveau modèle nommé Re_gptForCausalLM basé sur GPT-Neo, puis y ajoutons une partie de récupération.
Nous avons téléchargé le modèle installé sur EleutherAI/gpt-neo-125M à l'aide de la bibliothèque de récupération 200G.
Vous pouvez initialiser un modèle comme ceci :
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )Et évaluez le modèle comme ceci :
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Nous calculons la similarité en utilisant l'intégration de sentence_transformers comme représentation textuelle. Vous pouvez initialiser un modèle Sentence-BERT comme ceci :
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )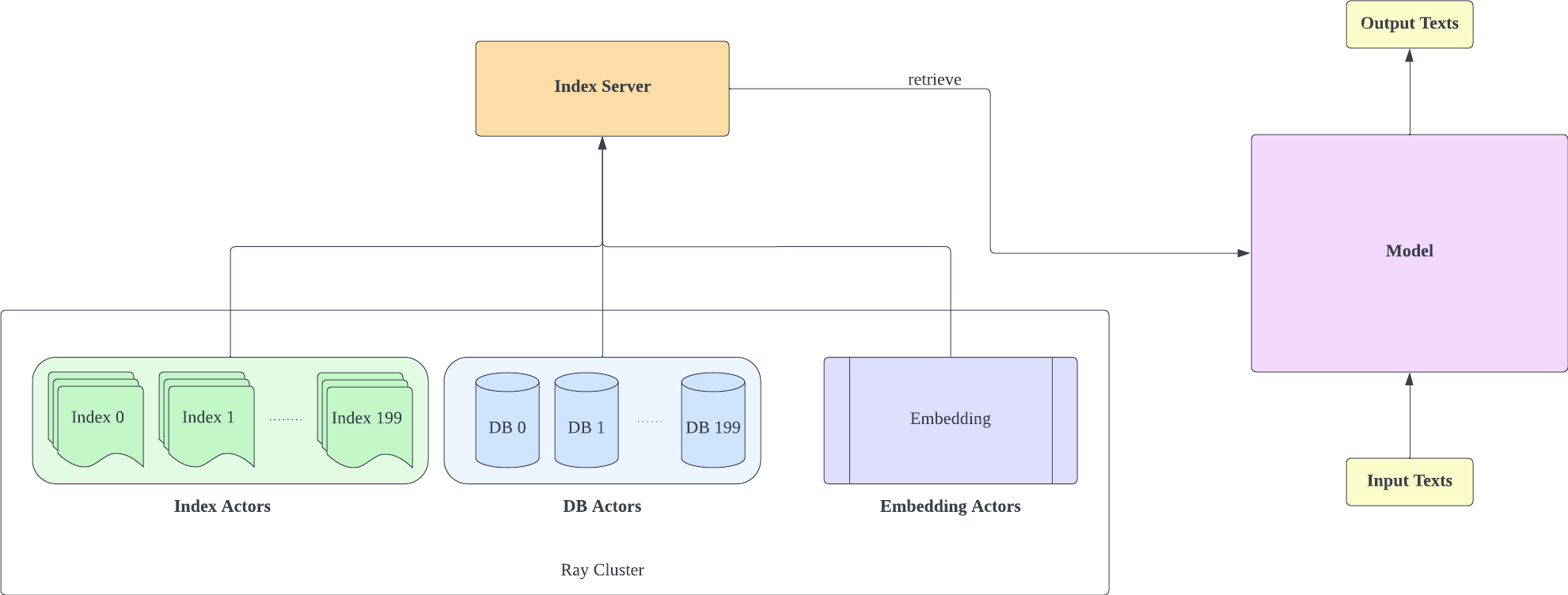
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " En utilisant IVF1024PQ48 comme usine d'index faiss, nous avons téléchargé l'index et la base de données sur le hub de modèles Huggingface, qui peuvent être téléchargés à l'aide de la commande suivante.
Dans download_index_db.py, vous pouvez spécifier le nombre d'index et de bases de données que vous souhaitez télécharger.
python -u download_index_db.py --num 200Vous pouvez télécharger manuellement le modèle ajusté à partir d'ici : https://huggingface.co/Langboat/ReGPT-125M-200G
Le serveur d'index est basé sur FastAPI et Ray. Avec Ray's Actor, les tâches gourmandes en calcul sont encapsulées de manière asynchrone, ce qui nous permet d'utiliser efficacement les ressources CPU et GPU avec une seule instance de serveur FastAPI. Vous pouvez initialiser un serveur d'index comme ceci :
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Gardez à l’esprit que le nombre de fragments de configuration IVF1024PQ48.json doit correspondre au nombre d’index téléchargés. Vous pouvez afficher le numéro d'index actuellement téléchargé sous le db_path
- Cette configuration a été testée sur l'A100-40G, donc si vous disposez d'un GPU différent, nous vous recommandons de l'ajuster à votre matériel.
- Après avoir déployé le serveur d'index, vous devez modifier le request_server dans lm-evaluation-harness/config.json et train/config.json .
- Vous pouvez réduire le nombre encoder_actor_count dans config_IVF1024PQ48.json pour réduire les ressources mémoire requises.
· db_path:l'emplacement de téléchargement de la base de données depuis huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" est un exemple.
Cette commande téléchargera la base de données et les données d'index depuis Huggingface.
Modifiez le dossier d'index dans le fichier de configuration (config IVF1024PQ48) pour qu'il pointe vers le chemin du dossier d'index et envoyez les instantanés du dossier de base de données en tant que chemin de base de données au script api.py.
Arrêtez le serveur d'index avec la commande suivante
ray stop
- Gardez à l'esprit que vous devez garder le serveur d'index activé pendant la formation, l'évaluation et l'inférence.
Utilisez train/train.py pour mettre en œuvre la formation ; train/config.json peut être modifié pour changer les paramètres de formation.
Vous pouvez initialiser la formation comme ceci :
cd train
python -u train.py
- Étant donné que le serveur d'index doit utiliser des ressources mémoire, il est préférable de déployer le serveur d'index et de modéliser la formation sur différents GPU.
Utilisez train/inference.py comme inférence pour déterminer la perte d'un texte et sa perplexité.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- Les tests_data.json et train_data.json dans le dossier data sont des formats de fichiers actuellement pris en charge, vous pouvez modifier vos données dans ce format.
Utiliser lm-evaluation-harness comme méthode d'évaluation
Nous définissons le seq_len du lm-evaluation-harness sur 1025 comme paramètre initial pour la comparaison de modèles, car le seq_len de notre formation de modèle est de 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:le chemin du modèle d'ajustement
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Les résultats de l'évaluation sont les suivants
| modèle | texte wiki word_perplexité |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Langboat/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Langboat/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

