GraphGPT : apprentissage de graphiques avec des transformateurs génératifs pré-entraînés
Ce référentiel est l'implémentation officielle de « GraphGPT : Graph Learning with Generative Pre-trained Transformers » dans PyTorch.
GraphGPT : apprentissage de graphiques avec des transformateurs génératifs pré-entraînés
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
Mise à jour:
13/10/2024
- v0.4.0 publié. Vérifiez
CHANGELOG.md pour plus de détails. - Réalisation de SOTA dans 3 ensembles de données OGB à grande échelle :
- PCQM4M-v2 (pas de 3D) : 0,0802 (SOTA précédent 0,0821)
- ogbl-ppa : 68,76 (SOTA précédent 65,24)
- ogbl-citation2 : 91,15 (précédent SOTA 90,72)
18/08/2024
- v0.3.1 publié. Vérifiez
CHANGELOG.md pour plus de détails.
07/09/2024
- v0.3.0 publié.
19/03/2024
- v0.2.0 publié.
- Implémentez
permute_nodes pour un ensemble de données de style carte au niveau graphique, afin d'augmenter les variations des chemins eulériens et d'obtenir des résultats meilleurs et robustes. - Ajoutez
StackedGSTTokenizer afin que les jetons sémantiques (c'est-à-dire les attributs de nœud/bord) puissent être empilés avec des jetons structurels, et la longueur de la séquence serait considérablement réduite. - refactoriser les codes.
23/01/2024
- v0.1.1, corrige les bugs du package common-io.
01/03/2024
- Publication initiale des codes.
Orientations futures
Loi d'échelle : quelle est la limite d'échelle des modèles GraphGPT ?
- Comme nous le savons, les GPT entraînés avec des données textuelles peuvent s'adapter à des centaines de milliards de paramètres et continuer à améliorer leurs capacités.
- Les données textuelles peuvent fournir des milliards de jetons, sont très complexes et possèdent de nombreuses connaissances, y compris des connaissances sociales et naturelles.
- En revanche, les données graphiques sans attributs de nœud/bord ne contiennent que des informations de structure, ce qui est assez limité par rapport aux données texte. La plupart des informations cachées (par exemple, les degrés, le nombre de sous-structures, etc.) derrière la structure peuvent être calculées exactement à l'aide de packages comme networkx. Par conséquent, les informations provenant de la structure du graphique pourraient ne pas être en mesure de prendre en charge la mise à l'échelle de la taille du modèle jusqu'à des milliards de paramètres.
- Nos expériences préliminaires avec divers ensembles de données graphiques à grande échelle montrent que nous pouvons faire évoluer GraphGPT jusqu'à plus de 400 millions de paramètres tout en améliorant les performances. Mais nous ne pouvons pas améliorer davantage les résultats. Cela pourrait être dû à nos expériences insuffisantes. Mais il est possible que ce soit les limitations inhérentes aux données graphiques qui en soient la cause.
- De grands ensembles de données graphiques (soit un grand graphique, soit d'énormes quantités de petits graphiques) avec des attributs de nœud/bord pourraient être en mesure de fournir suffisamment d'informations pour nous permettre de former un grand modèle GraphGPT. Même ainsi, un seul ensemble de données graphiques peut ne pas suffire et nous devrons peut-être collecter plusieurs ensembles de données graphiques pour former un GraphGPT.
- Le problème ici est de savoir comment définir un tokenizer universel pour les attributs de bord/nœud à partir de divers ensembles de données graphiques.
Données graphiques de haute qualité : que sont les données graphiques de haute qualité pour entraîner un GraphGPT à des tâches générales ?
- Par exemple, si nous voulons former un modèle pour toutes sortes de tâches de compréhension et de génération de molécules, quel type de données devons-nous utiliser ?
- D'après notre enquête préliminaire, nous avons ajouté ZINC (4,6 M) et CEPDB (2,3 M) au pré-entraînement, nous n'avons observé aucun gain lors du réglage fin de PCQM4M-v2 pour la tâche de prédiction de l'écart homo-lumo. Les raisons possibles pourraient être les suivantes :
- #structure# Les modèles graphiques derrière le graphique moléculaire sont relativement simples.
- Les modèles graphiques tels que les chaînes ou les anneaux à 5/6 nœuds sont très courants.
- En moyenne 2 arêtes par nœud, ce qui signifie que les atomes ont en moyenne 2 liaisons.
- #sémantique# Les règles chimiques pour construire des petites molécules organiques sont simples : l'atome de carbone a 4 liaisons, l'atome d'azote a 3 liaisons, l'atome d'oxygène a 2 liaisons et l'atome d'hydrogène a 1 liaison, et ainsi de suite. En termes simples, tant que le nombre de liaisons des atomes est satisfait, nous pouvons générer n'importe quelle molécule.
- Les règles de structure et de sémantique sont si simples que même un modèle de taille moyenne peut apprendre d'un ensemble de données de taille moyenne. L’ajout de données supplémentaires n’aide donc pas. Nous pré-entraînons des modèles petits/moyens/de base/grands à l'aide de 3,7 millions de données moléculaires, et leurs pertes sont très proches, ce qui indique des gains limités résultant de l'agrandissement de la taille des modèles dans la phase de pré-entraînement.
- Deuxièmement, si nous voulons former un modèle pour n’importe quel type de tâches de compréhension de la structure graphique, quel type de données devons-nous utiliser ?
- Devons-nous utiliser de véritables données graphiques provenant des réseaux sociaux, des réseaux de citations, etc., ou simplement utiliser des données graphiques synthétiques, telles que des graphiques Erdos-Renyi aléatoires ?
- Nos expériences préliminaires montrent que l'utilisation de graphiques aléatoires pour pré-entraîner GraphGPT est utile pour que le modèle comprenne les structures des graphiques, mais il est instable. Nous soupçonnons que cela est lié aux distributions des structures graphiques dans les étapes de pré-entraînement et de réglage fin. Par exemple, s'ils ont un nombre similaire d'arêtes par nœud, un nombre similaire de nœuds, alors le paradigme de pré-entraînement et de réglage fin fonctionne bien.
- #Universalité# Alors, comment entraîner un modèle GraphGPT pour comprendre universellement n'importe quelle structure de graphe ?
- Cela nous ramène aux questions précédentes sur la loi de mise à l'échelle : quelles sont les données graphiques appropriées et de haute qualité pour continuer à faire évoluer GraphGPT afin qu'il puisse bien effectuer diverses tâches graphiques ?
Quelques tirs : GraphGPT peut-il acquérir une capacité de quelques tirs ?
- Si possible, comment concevoir les données de formation pour permettre à GraphGPT de les apprendre ?
- D’après nos expériences préliminaires avec l’ensemble de données PCQM4M-v2, aucune capacité d’apprentissage de tir n’est observée ! Mais cela ne veut pas dire que ce n’est pas possible. Cela pourrait être dû aux raisons suivantes :
- Le modèle n'est pas assez grand. Nous utilisons le modèle de base avec ~ 100 millions de paramètres.
- Les données de formation ne suffisent pas. Nous n'utilisons que 3,7 millions de molécules, ce qui ne fournit que des jetons limités pour la formation.
- Le format des données d'entraînement n'est pas adapté au modèle pour acquérir une capacité de quelques tirs.
Aperçu:

Nous proposons GraphGPT, un nouveau modèle d'apprentissage de graphes par des transformateurs eulériens de graphes de pré-entraînement génératifs auto-supervisés (GET). Nous introduisons d'abord GET, qui consiste en un squelette d'encodeur/décodeur de transformateur vanille et une transformation qui transforme chaque graphe ou sous-graphe échantillonné en une séquence de jetons représentant le nœud, l'arête et les attributs de manière réversible en utilisant le chemin eulérien. Ensuite, nous pré-entraînons le GET avec soit la tâche de prédiction du prochain jeton (NTP), soit la tâche planifiée de prédiction du jeton masqué (SMTP). Enfin, nous affinons le modèle avec les tâches supervisées. Ce modèle intuitif, mais efficace, permet d'obtenir des résultats supérieurs ou proches des méthodes de pointe pour les tâches au niveau des graphiques, des bords et des nœuds sur l'ensemble de données moléculaires à grande échelle PCQM4Mv2, l'ensemble de données d'association protéine-protéine ogbl-ppa. , l'ensemble de données du réseau de citations ogbl-citation2 et l'ensemble de données ogbn-proteins de l'Open Graph Benchmark (OGB). De plus, la pré-formation générative nous permet d'entraîner GraphGPT jusqu'à 2B+ paramètres avec des performances constamment croissantes, ce qui dépasse la capacité des GNN et des transformateurs graphiques précédents.
Graphique en séquences
Après avoir converti les graphiques eulerisés en séquences, il existe plusieurs manières différentes d'attacher des attributs de nœud et d'arête aux séquences. Nous appelons ces méthodes short , long et prolonged .
Étant donné le graphique, nous l’eulérisons d’abord, puis le transformons en une séquence équivalente. Et puis, nous réindexons les nœuds de manière cyclique.
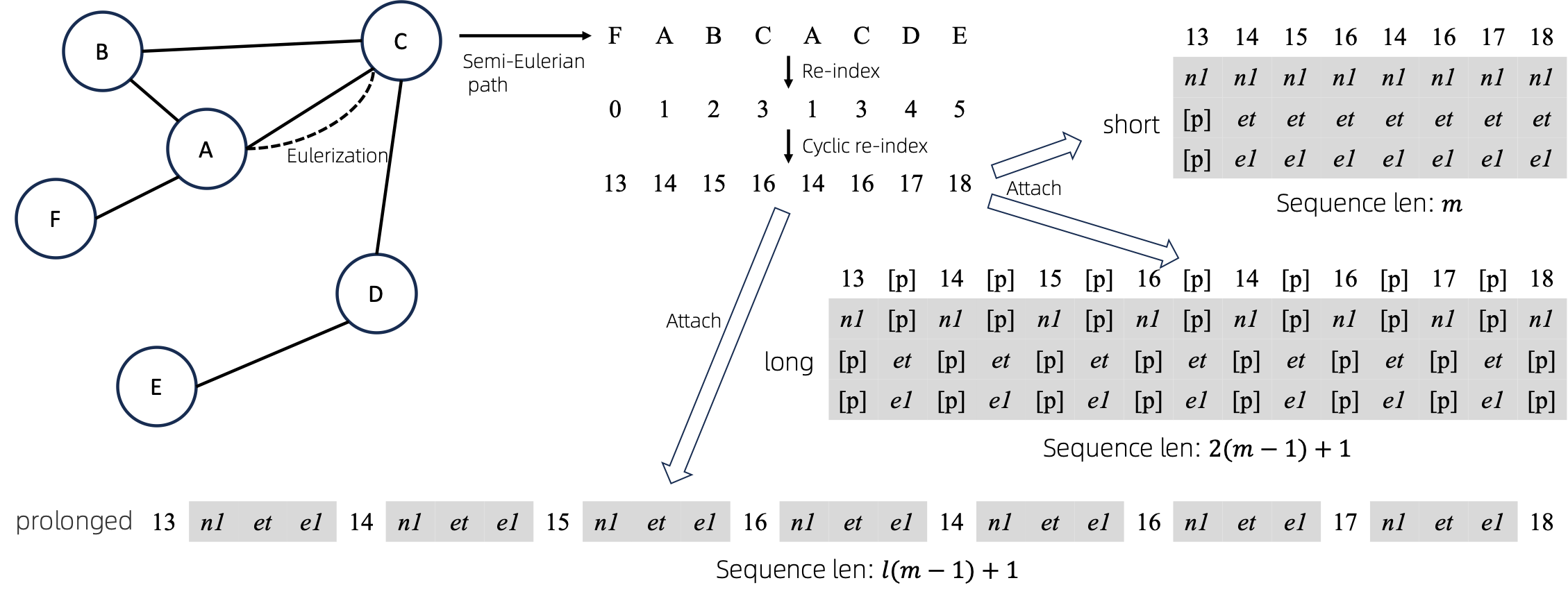
Supposons que le graphique ait un attribut de nœud et un attribut de bord, puis les méthodes short , long et prolong sont présentées ci-dessus.
Dans les figures ci-dessus, n1 , n2 et e1 représentent les jetons des attributs de nœud et de bord, et [p] représente le jeton de remplissage.
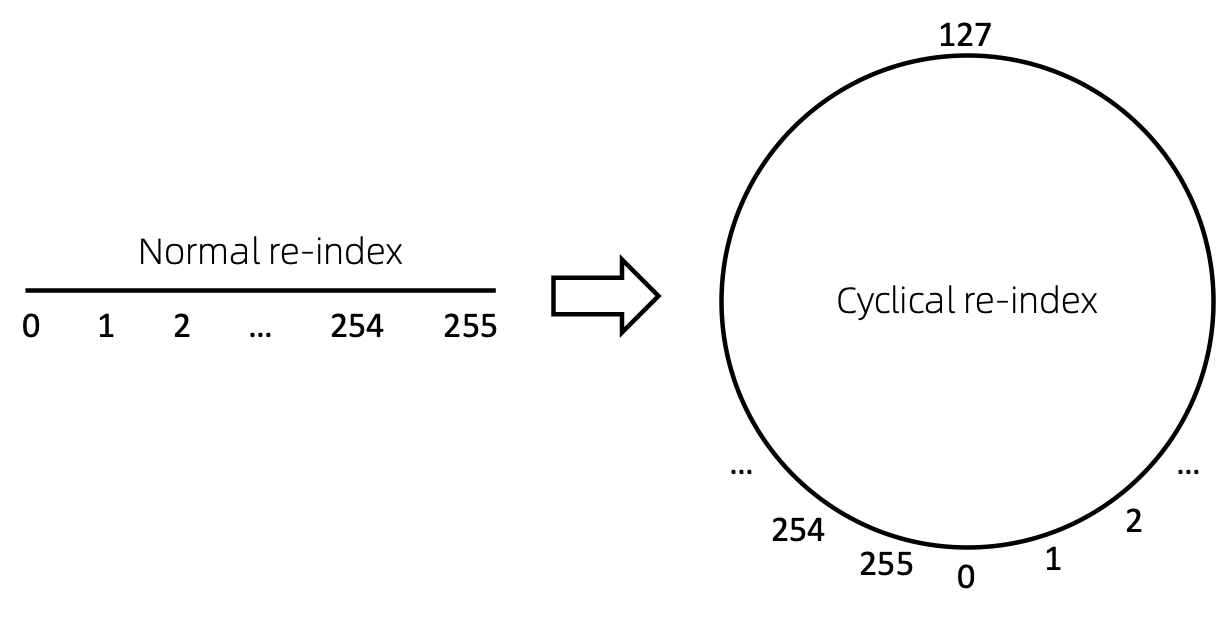
Réindexation cyclique des nœuds
Un moyen simple de réindexer la séquence de nœuds consiste à commencer par 0 et à ajouter 1 progressivement. De cette manière, les jetons des petits indices seront suffisamment entraînés, contrairement aux grands indices. Pour surmonter ce problème, nous proposons cyclical re-index , qui commence par un nombre aléatoire dans la plage donnée, disons [0, 255] , et incrémentée de 1. Après avoir atteint la limite, par exemple 255 , l'indice de nœud suivant sera 0. .
Résultats
Dépassé. A mettre à jour prochainement.
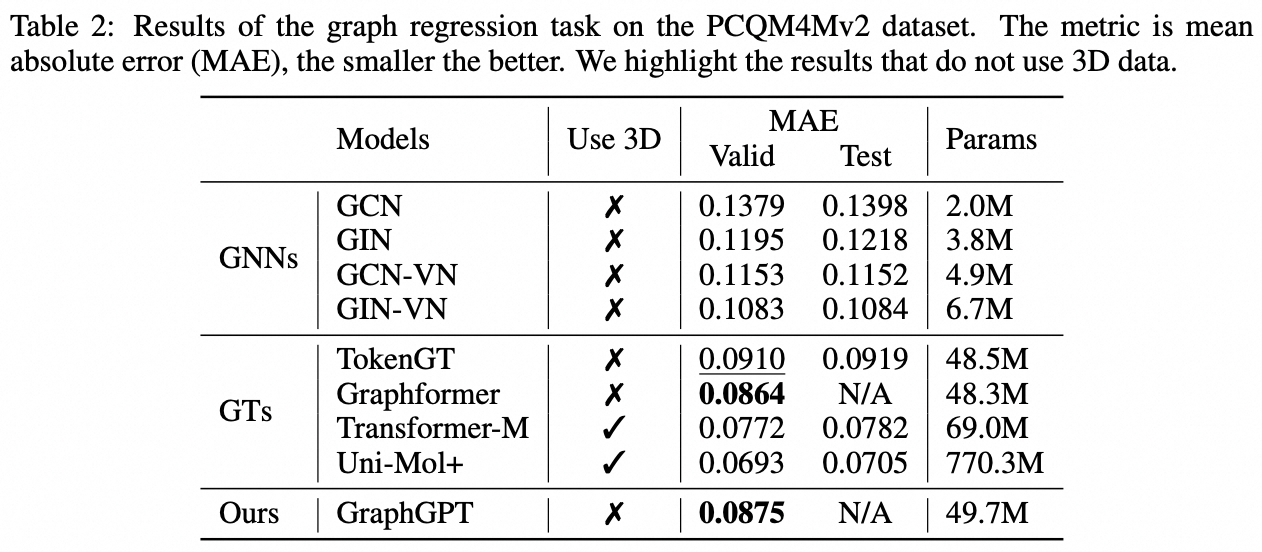
Tâche au niveau du graphique : ensemble de données PCQM4M-v2
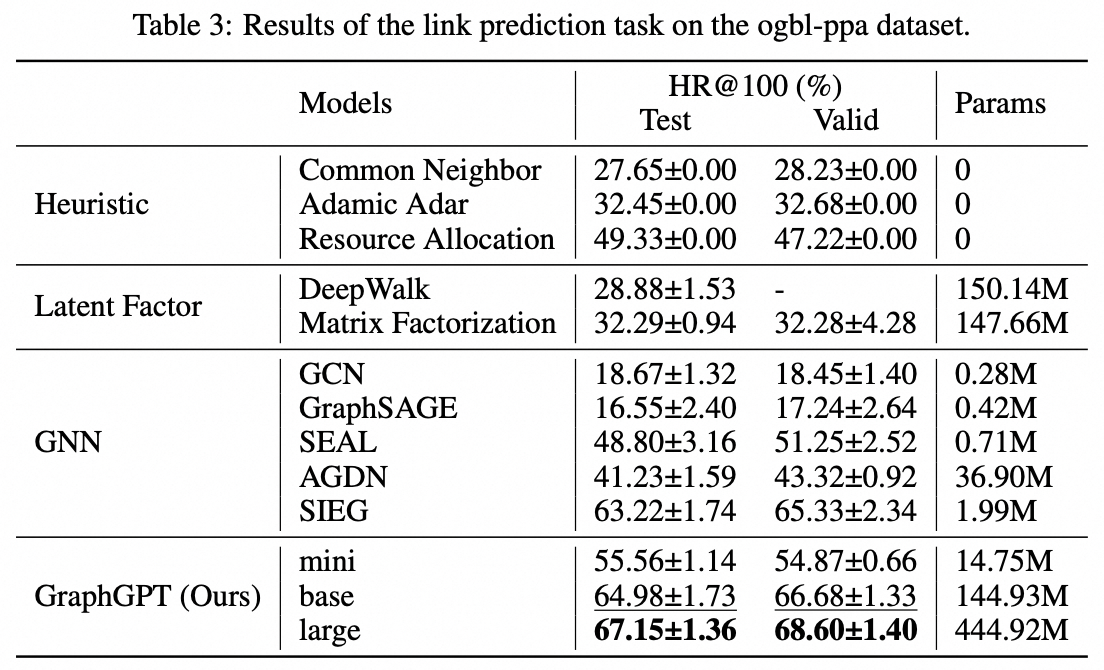
Tâche au niveau périphérique : ensemble de données ogbl-ppa
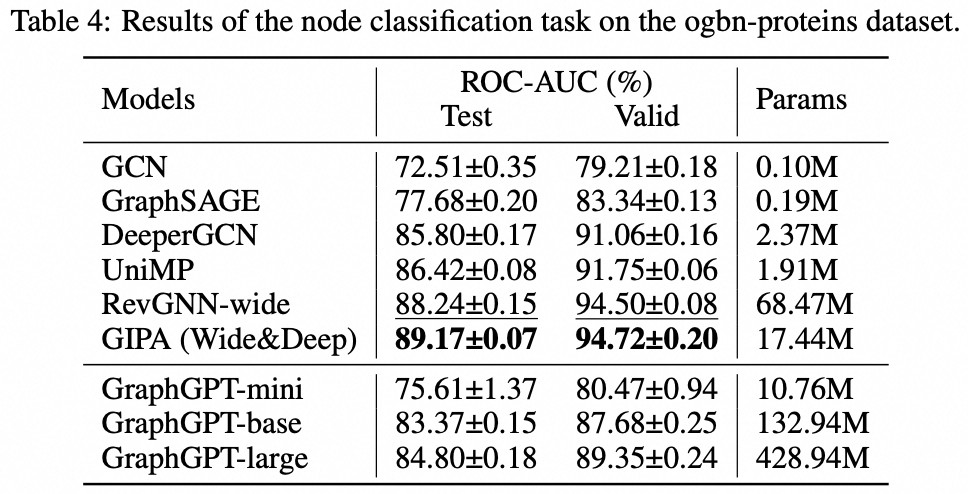
Tâche au niveau du nœud : ensemble de données ogbn-proteins
Installation
git clone https://github.com/alibaba/graph-gpt.git
- Installez les dépendances dans Requirements.txt (à l'aide d'Anaconda, testé avec py38, pytorch-1131 et CUDA-11.7, 11.8 et 12.1 sur GPU V100 et A100)
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Ensembles de données
Les ensembles de données sont téléchargés à l'aide du package python ogb.
Lorsque vous exécutez des scripts dans ./examples , l'ensemble de données sera automatiquement téléchargé.
Cependant, l'ensemble de données PCQM4M-v2 est énorme et le téléchargement et le prétraitement peuvent être problématiques. Nous suggérons cd ./src/utils/ et python dataset_utils.py pour télécharger et prétraiter l'ensemble de données séparément.
Courir
- Pré-entraînement : modifiez les paramètres dans
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , par exemple, dataset_name , model_name , batch_size , workerCount et etc., puis exécutez ./examples/graph_lvl/pcqm4m_v2_pretrain.sh pour pré-entraîner le modèle avec PCQM4M-v2 ensemble de données.- Pour exécuter l'exemple de jouet, exécutez directement
./examples/toy_examples/reddit_pretrain.sh .
- Affiner : modifiez les paramètres dans
./examples/graph_lvl/pcqm4m_v2_supervised.sh , par exemple, dataset_name , model_name , batch_size , workerCount , pretrain_cpt et etc., puis exécutez ./examples/graph_lvl/pcqm4m_v2_supervised.sh pour affiner les tâches en aval. .- Pour exécuter l'exemple de jouet, exécutez directement
./examples/toy_examples/reddit_supervised.sh .
Norme du code
Pré-engagement
- Consultez le site officiel pour plus de détails
-
.pre-commit-config.yaml : créez le fichier avec le contenu suivant pour python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : installez le pré-commit dans vos hooks git.- le pré-commit s'exécutera désormais à chaque commit.
- Chaque fois que vous clonez un projet à l'aide du pré-commit, l'exécution
pre-commit install doit toujours être la première chose à faire.
-
pre-commit run --all-files : exécute tous les hooks de pré-commit sur un référentiel -
pre-commit autoupdate : mettez automatiquement à jour vos hooks vers la dernière version -
git commit -n : les vérifications préalables au commit peuvent être désactivées pour un commit particulier avec la commande
Citation
Si vous trouvez ce travail utile, veuillez citer les articles suivants :
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Contact
Qifang Zhao ([email protected])
J'apprécie sincèrement vos suggestions sur notre travail !
Licence
Publié sous licence MIT (voir LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


