L2MAC
1.0.0
Pionnier du premier cadre informatique automatique à programme stocké à usage général basé sur LLM (architecture von Neumann) dans un système multi-agent basé sur LLM, pour résoudre des tâches complexes en générant des sorties étendues et cohérentes, sans limite par la contrainte de fenêtre de contexte fixe du LLM. .
? Peut. 7 - 11 janvier 2024 : Nous présenterons L2MAC à la Conférence internationale sur les représentations d'apprentissage (ICLR) 2024. Venez nous rencontrer à l'ICLR à Vienne en Autriche ! Veuillez me contacter à sih31 (at) cam.ac.uk afin que nous puissions nous rencontrer, les réunions virtuelles sont également acceptées !
? Avril. 23 2024 : L2MAC est entièrement open source avec la version initiale publiée.
16 janvier 2024 : L'article L2MAC : Large Language Model Automatic Computer for Extensive Code Generation est accepté pour présentation à l'ICLR 2024 !
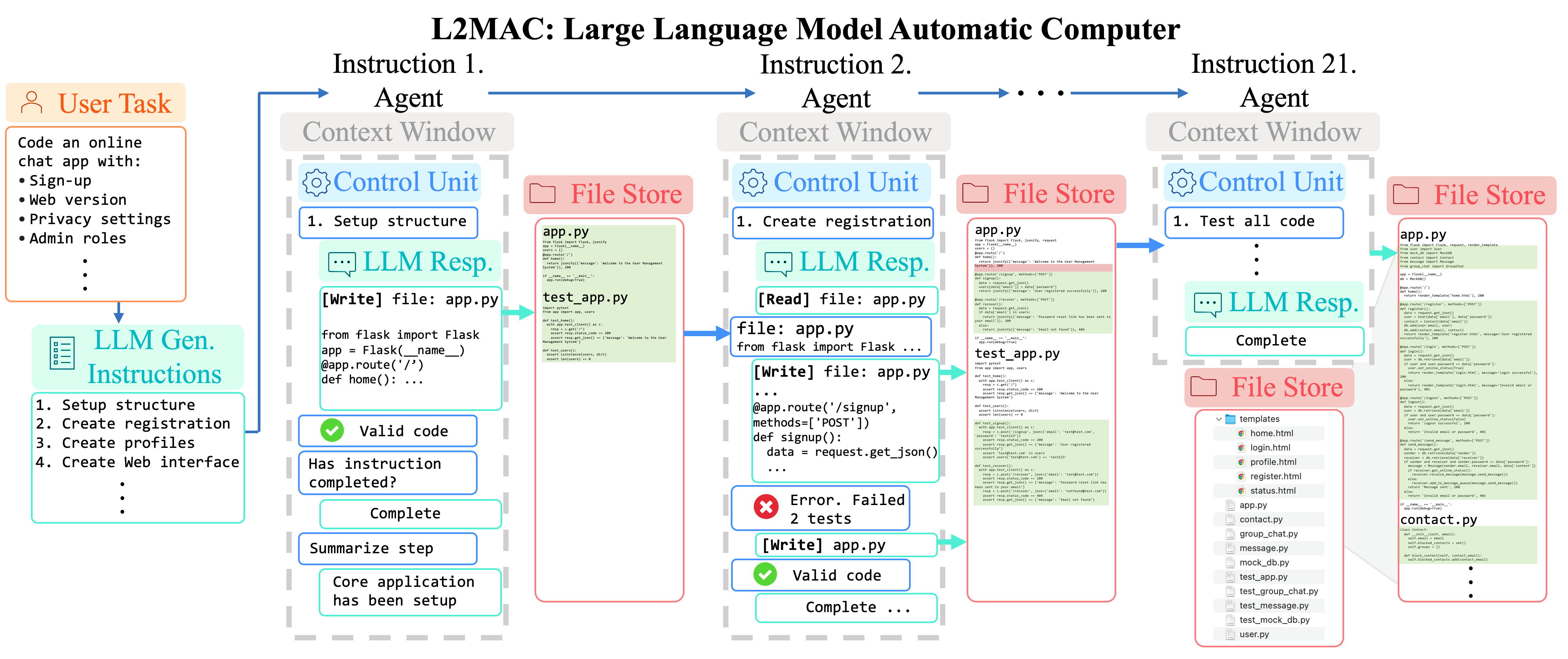
Instanciation LLM-Automatic Computer (L2MAC) pour coder une grande base de code complexe pour une application entière basée sur une seule invite utilisateur . Ici, nous fournissons à L2MAC des outils supplémentaires pour vérifier les erreurs de syntaxe dans le code et exécuter les tests unitaires s'ils existent.
Assurez-vous que Python 3.7+ est installé sur votre système. Vous pouvez vérifier cela en utilisant :
python --version. Vous pouvez utiliser conda comme ceci :conda create -n l2mac python=3.9 && conda activate l2mac
pip install --upgrade l2mac
# or `pip install --upgrade git+https://github.com/samholt/l2mac`
# or `git clone https://github.com/samholt/l2mac && cd l2mac && pip install --upgrade -e .`Pour des conseils d'installation détaillés, veuillez vous référer à l'installation
Vous pouvez initialiser la configuration de L2MAC en exécutant la commande suivante ou créer manuellement le fichier ~/.L2MAC/config.yaml :
# Check https://samholt.github.io/L2MAC/guide/get_started/configuration.html for more details
l2mac --init-config # it will create ~/.l2mac/config.yaml, just modify it to your needs Vous pouvez configurer ~/.l2mac/config.yaml selon l'exemple et la doc :
llm :
api_type : " openai " # or azure etc. Check ApiType for more options
model : " gpt-4-turbo-preview " # or "gpt-4-turbo"
base_url : " https://api.openai.com/v1 " # or forward url / other llm url
api_key : " YOUR_API_KEY "Après l'installation, vous pouvez utiliser L2MAC CLI
l2mac " Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid. " # this will create a codebase repo in ./workspaceou utilisez-le comme bibliothèque
from l2mac import generate_codebase
codebase : dict = generate_codebase ( "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." )
print ( codebase ) # it will print the codebase (repo) complete with all the files as a dictionary, and produce a local codebase folder in ./workspace? Rejoignez notre chaîne Discord ! Au plaisir de vous y voir ! ?
Si vous avez des questions ou des commentaires sur ce projet, n'hésitez pas à nous contacter. Nous apprécions grandement vos suggestions !
Nous répondrons à toutes les questions dans un délai de 2 à 3 jours ouvrables.
Pour rester informé des dernières recherches et développements, suivez @samianholt sur Twitter.
Pour citer L2MAC dans des publications, veuillez utiliser l'entrée BibTeX suivante.
@inproceedings {
holt2024lmac,
title = { L2{MAC}: Large Language Model Automatic Computer for Unbounded Code Generation } ,
author = { Samuel Holt and Max Ruiz Luyten and Mihaela van der Schaar } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=EhrzQwsV4K }
}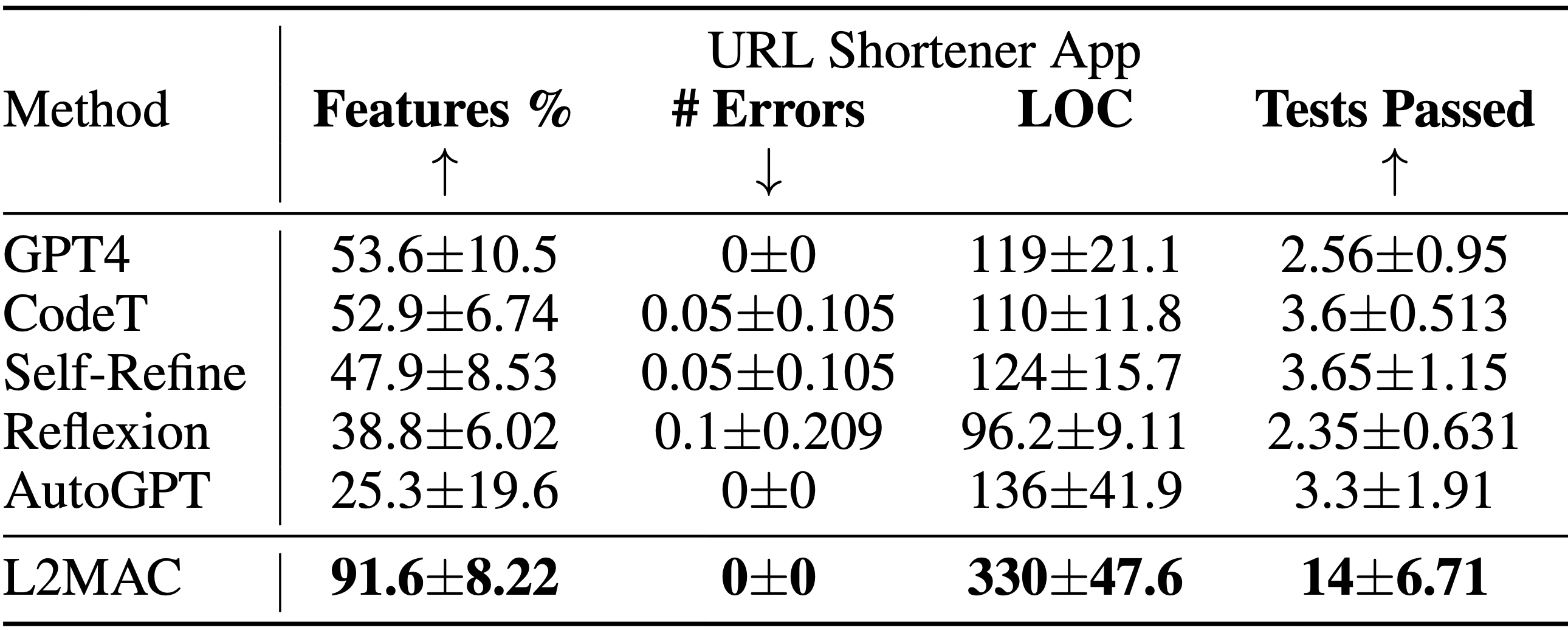
Instanciation LLM-Automatic Computer (L2MAC) pour coder une grande base de code complexe pour une application entière basée sur une seule invite utilisateur . Résultats de la tâche de conception du système de génération de base de code montrant le pourcentage de fonctionnalités fonctionnelles spécifiées qui sont entièrement implémentées ( Features % ), le nombre d'erreurs syntaxiques dans le code généré ( # Errors ), le nombre de lignes de code ( LOC ) et le nombre de réussir les tests ( Tests réussis ). L2MAC implémente pleinement le pourcentage le plus élevé d'exigences de fonctionnalités de tâche spécifiées par l'utilisateur dans toutes les tâches en générant un code entièrement fonctionnel qui comporte un minimum d'erreurs syntaxiques et un nombre élevé de tests unitaires auto-générés avec succès, il est donc à la pointe de la technologie pour le génération de bases de code de sortie volumineuses, et tout aussi compétitif pour la génération de tâches de sortie volumineuses. Les résultats sont moyennés sur 10 graines aléatoires.
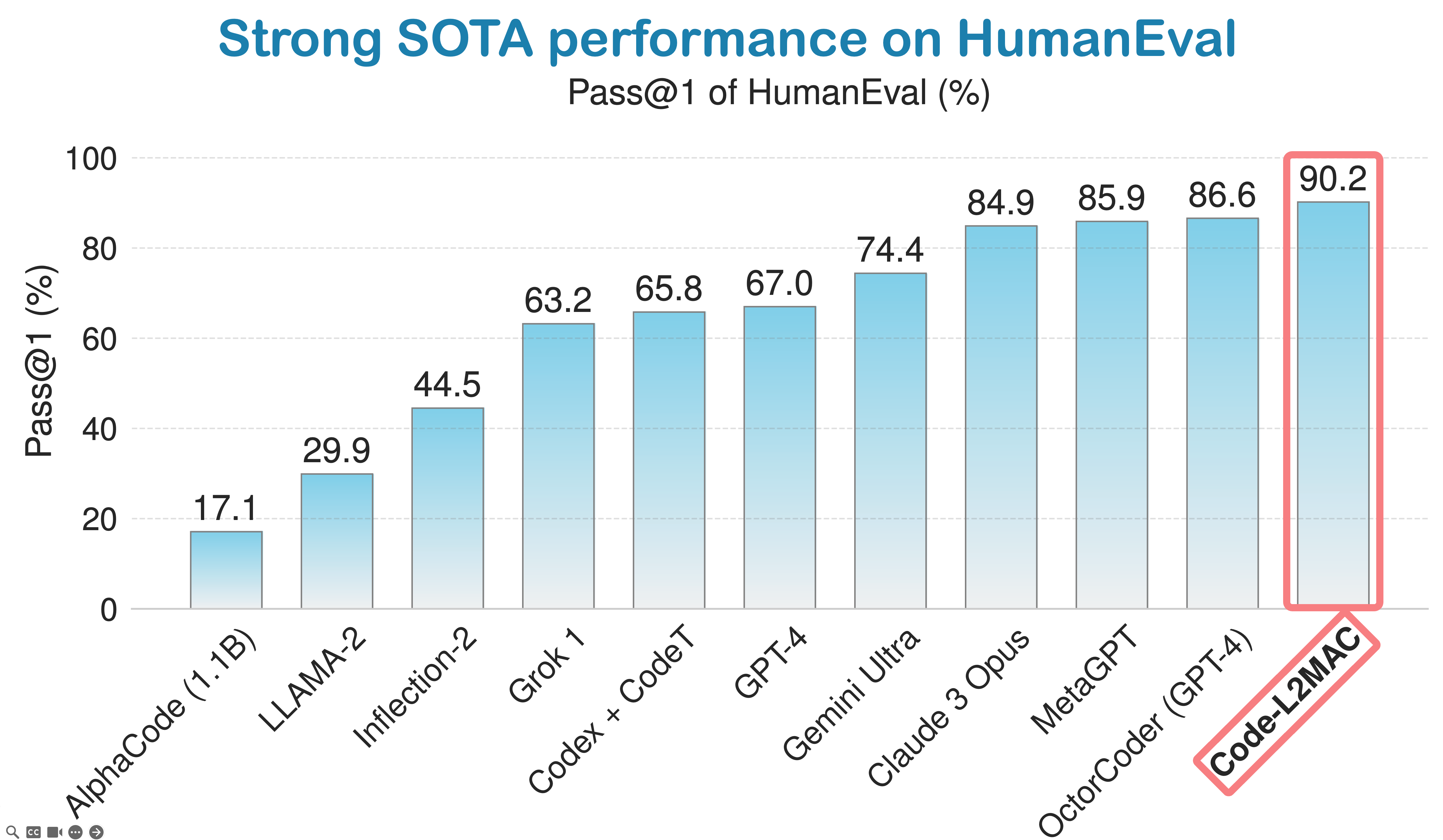
LLM-Automatic Computer (L2MAC) obtient de solides performances sur la référence de codage HumanEval et est actuellement classé 3e meilleur agent de codage d'IA au monde dans le classement mondial des normes de l'industrie du codage de HumanEval.
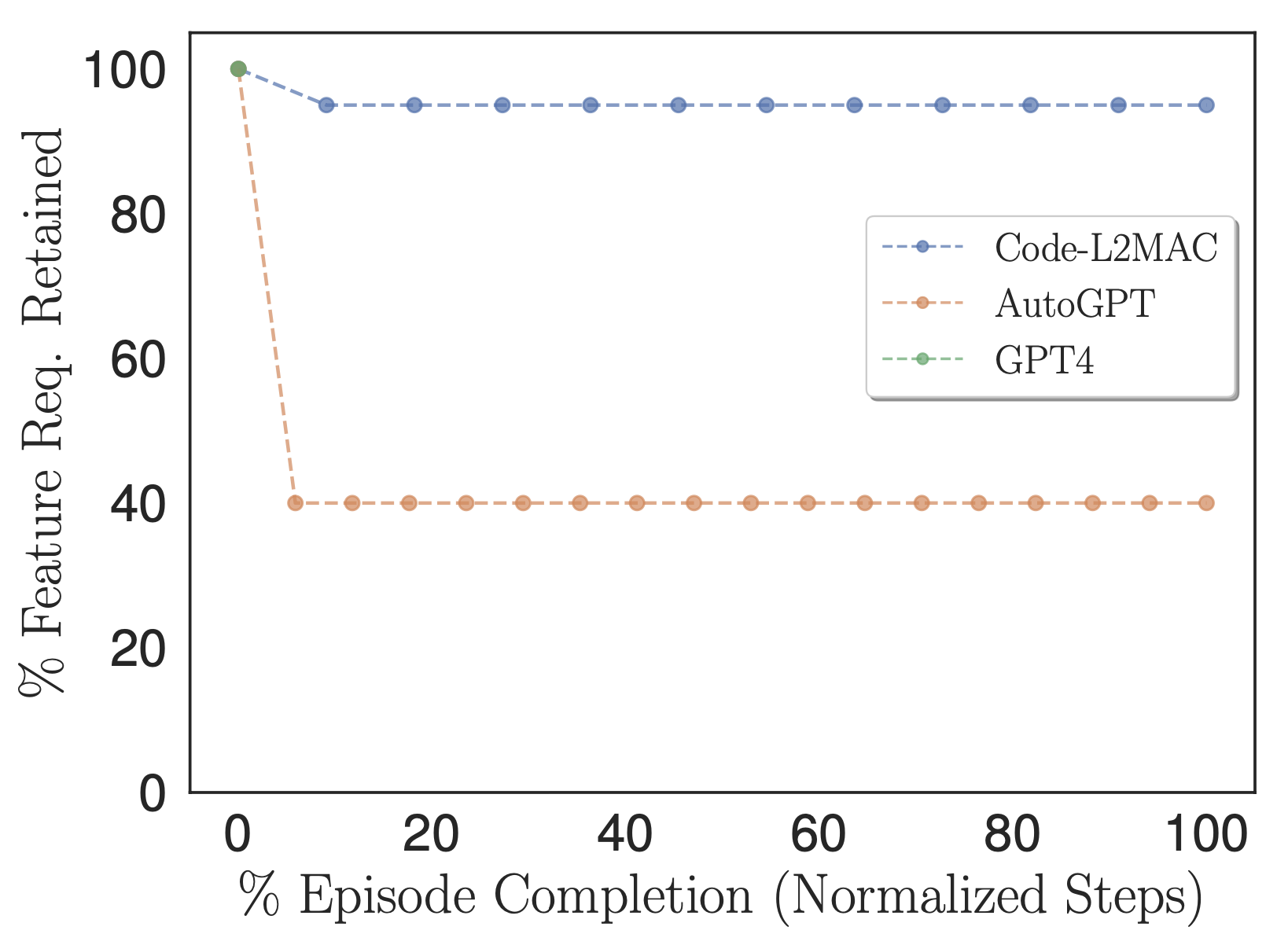
Pourcentage des exigences de fonctionnalités spécifiées par l'utilisateur qui sont conservées dans les instructions de tâche des méthodes et utilisées dans le contexte.
Pour déterminer si les méthodes évaluées pendant le fonctionnement contiennent les informations dans leur contexte permettant d'accomplir la tâche directement, nous avons adapté notre métrique % de fonctionnalités pour compter le nombre d'exigences de fonctionnalités de tâche spécifiées par l'utilisateur qui sont conservées dans les instructions de tâche des méthodes, c'est-à-dire celles instructions qui sont finalement introduites dans sa fenêtre contextuelle pendant son fonctionnement, comme le montre la figure ci-dessus. Empiriquement, nous observons que L2MAC est capable de conserver un grand nombre d'exigences de fonctionnalités de tâches spécifiées par l'utilisateur dans son programme d'invite et d'effectuer des tâches de longue durée orientées instructions. Nous notons qu'AutoGPT traduit également initialement les exigences en matière de fonctionnalités de tâche spécifiées par l'utilisateur en instructions de tâche ; cependant, il le fait avec une compression plus élevée, condensant les informations en une simple description de six phrases. Ce processus entraîne la perte d'informations cruciales sur la tâche, nécessaires à l'exécution correcte de la tâche globale, de sorte qu'elle s'aligne sur la tâche détaillée spécifiée par l'utilisateur.
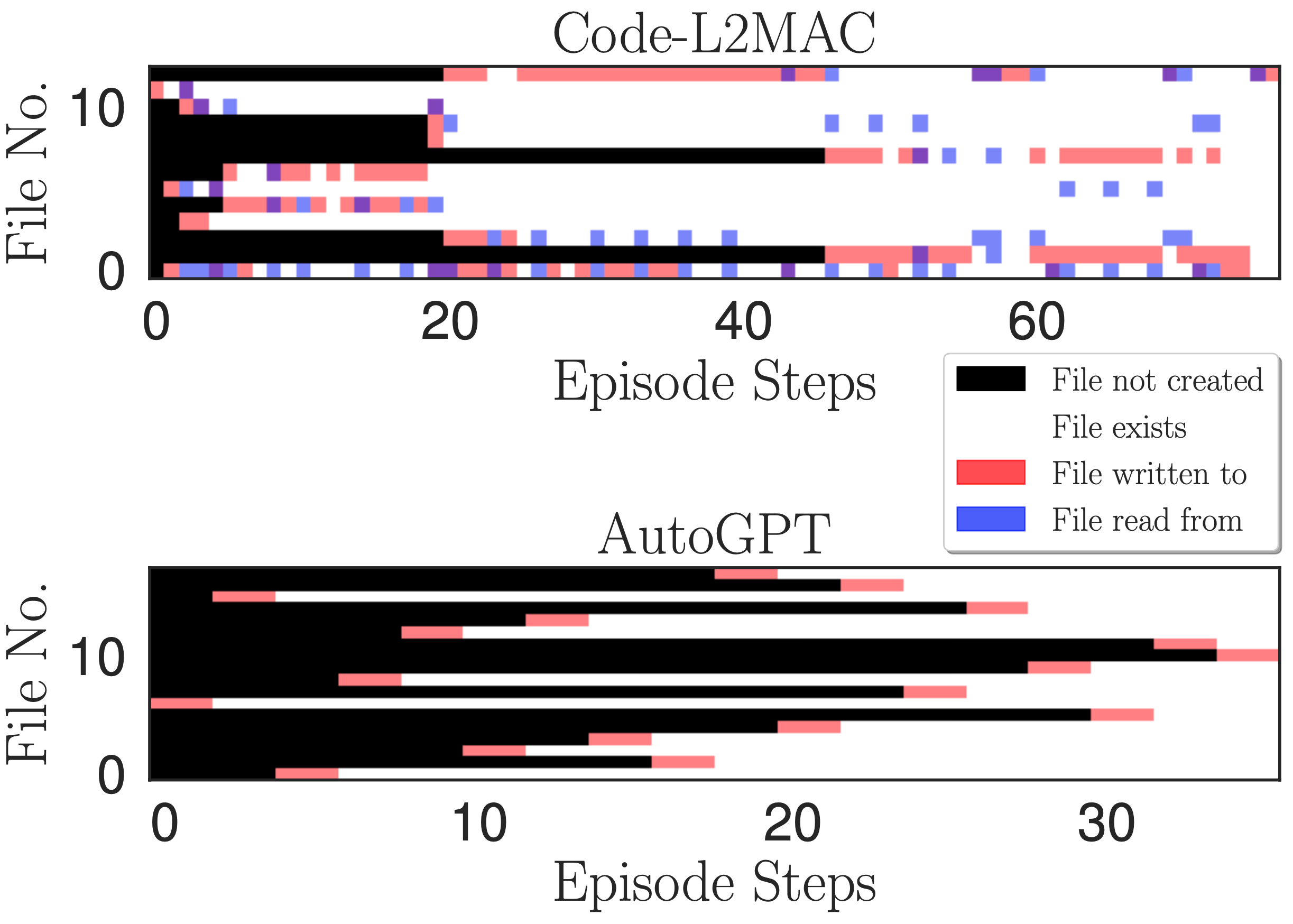
Carte thermique de l'accès aux fichiers. Indique la lecture, l'écriture et le moment où les fichiers sont créés à chaque étape de l'opération d'écriture au cours d'un épisode pour la tâche de l'application de chat en ligne.
Nous souhaitons comprendre, lors de l'exécution d'une instruction de tâche, si L2MAC peut comprendre les fichiers de code générés existants dans la base de code --- qui auraient pu être créés il y a de nombreuses instructions, et grâce à sa compréhension, créer de nouveaux fichiers en relation avec le fichiers existants, et surtout mettre à jour les fichiers de code existants à mesure que de nouvelles fonctionnalités sont implémentées. Pour obtenir un aperçu, nous traçons une carte thermique de la lecture, de l'écriture et du moment où les fichiers sont créés à chaque étape de l'opération d'écriture au cours d'un épisode dans la figure ci-dessus. Nous observons que L2MAC a une compréhension du code généré existant qui lui permet de mettre à jour les fichiers de code existants, même ceux créés à l'origine il y a de nombreuses étapes d'instructions, et peut afficher les fichiers lorsqu'il n'est pas certain et mettre à jour les fichiers en écrivant dans les fichiers. En revanche, AutoGPT n'écrit souvent dans les fichiers qu'une seule fois, lors de leur création initiale, et ne peut mettre à jour que les fichiers dont il a connaissance et qui sont conservés dans sa fenêtre de contexte actuelle. Bien qu'il dispose également d'un outil de lecture de fichiers, il oublie souvent les fichiers qu'il a créés il y a de nombreuses itérations en raison de son approche de gestion de la fenêtre contextuelle consistant à résumer les messages de dialogue les plus anciens dans sa fenêtre contextuelle, c'est-à-dire une compression continue avec perte des progrès réalisés précédemment. pendant l'opération de réalisation de la tâche.
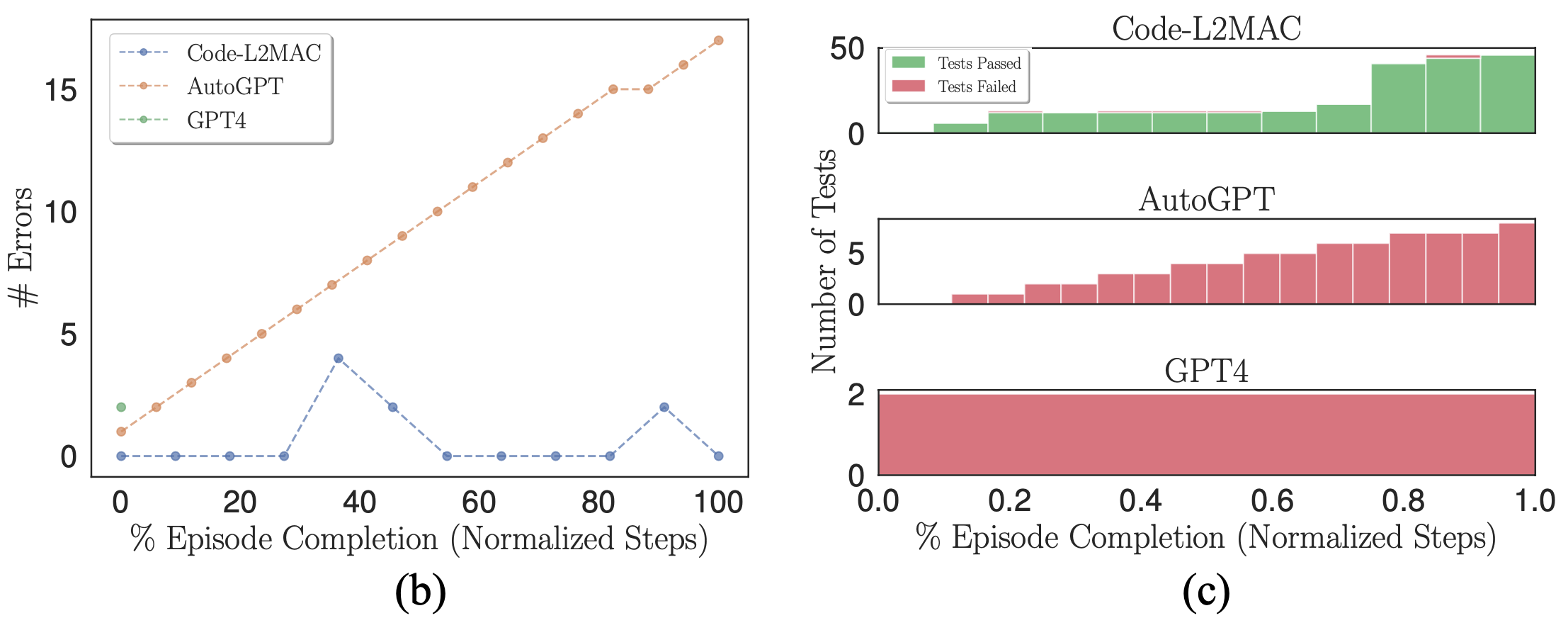
(b) Nombre d'erreurs syntaxiques dans la base de code. (c) Histogrammes empilés des tests unitaires réussis et échoués auto-générés.
Lorsque vous utilisez un modèle probabiliste (LLM) comme générateur de code de sortie, des erreurs peuvent naturellement se produire dans ses sorties. Par conséquent, nous souhaitons vérifier si, lorsque des erreurs apparaissent, les méthodes de référence respectives peuvent corriger les erreurs de la base de code. Nous traçons le nombre d'erreurs syntaxiques dans la base de code lors d'une exécution où des erreurs sont commises dans la figure (b) ci-dessus. Nous observons que L2MAC peut corriger correctement les erreurs de la base de code générée précédemment qui contient des erreurs, qui pourraient provenir d'erreurs syntaxiques du dernier fichier écrit ou d'autres fichiers qui dépendent du fichier écrit le plus récent, qui contiennent désormais des erreurs. Pour ce faire, il reçoit le résultat de l'erreur lorsqu'elle se produit et modifie la base de code pour résoudre l'erreur tout en complétant l'instruction en cours. En revanche, AutoGPT ne peut pas détecter lorsqu'une erreur dans la base de code a été commise et continue de fonctionner, ce qui peut aggraver le nombre d'erreurs formées dans la base de code.
De plus, L2MAC génère des tests unitaires parallèlement au code fonctionnel et les utilise comme vérificateur d'erreurs pour inspecter les fonctionnalités de la base de code au fur et à mesure de sa génération et peut utiliser ces erreurs pour corriger la base de code afin de réussir les tests unitaires qui échouent désormais après la mise à jour d'une partie d'un code existant. déposer. Nous montrons cela dans la figure (c) ci-dessus et observons qu'AutoGPT, bien qu'il soit invité à écrire également des tests unitaires pour tout le code généré, est incapable d'utiliser ces tests comme contrôle d'erreur d'intégrité, ce qui pourrait être aggravé par l'observation selon laquelle AutoGPT oublie quel code est généré. fichiers qu'il a créés précédemment et donc incapable de modifier les fichiers de code oubliés existants à mesure que de nouvelles modifications sont apportées, conduisant à des fichiers de code incompatibles.
Nous présentons L2MAC, le premier cadre informatique à programme stocké à usage général basé sur LLM qui augmente de manière efficace et évolutive les LLM avec une mémoire de stockage pour les tâches de génération de sorties longues là où cela n'a pas été réalisé avec succès auparavant. Plus précisément, L2MAC, lorsqu'il est appliqué à des tâches de génération de code long, surpasse les solutions existantes et constitue un outil extrêmement utile pour un développement rapide. Nous apprécions les contributions et vous encourageons à utiliser et à citer le projet. Cliquez ici pour commencer.
Nous incluons une galerie d'exemples d'applications entièrement produites par l'ordinateur automatique LLM (L2MAC) à partir d'une seule invite de saisie. L2MAC excelle dans la résolution de tâches complexes, par exemple en étant à la pointe de la technologie pour générer de grandes bases de code, ou il peut même écrire des livres entiers, qui contournent tous les contraintes traditionnelles de la fenêtre de contexte fixe du LLM.
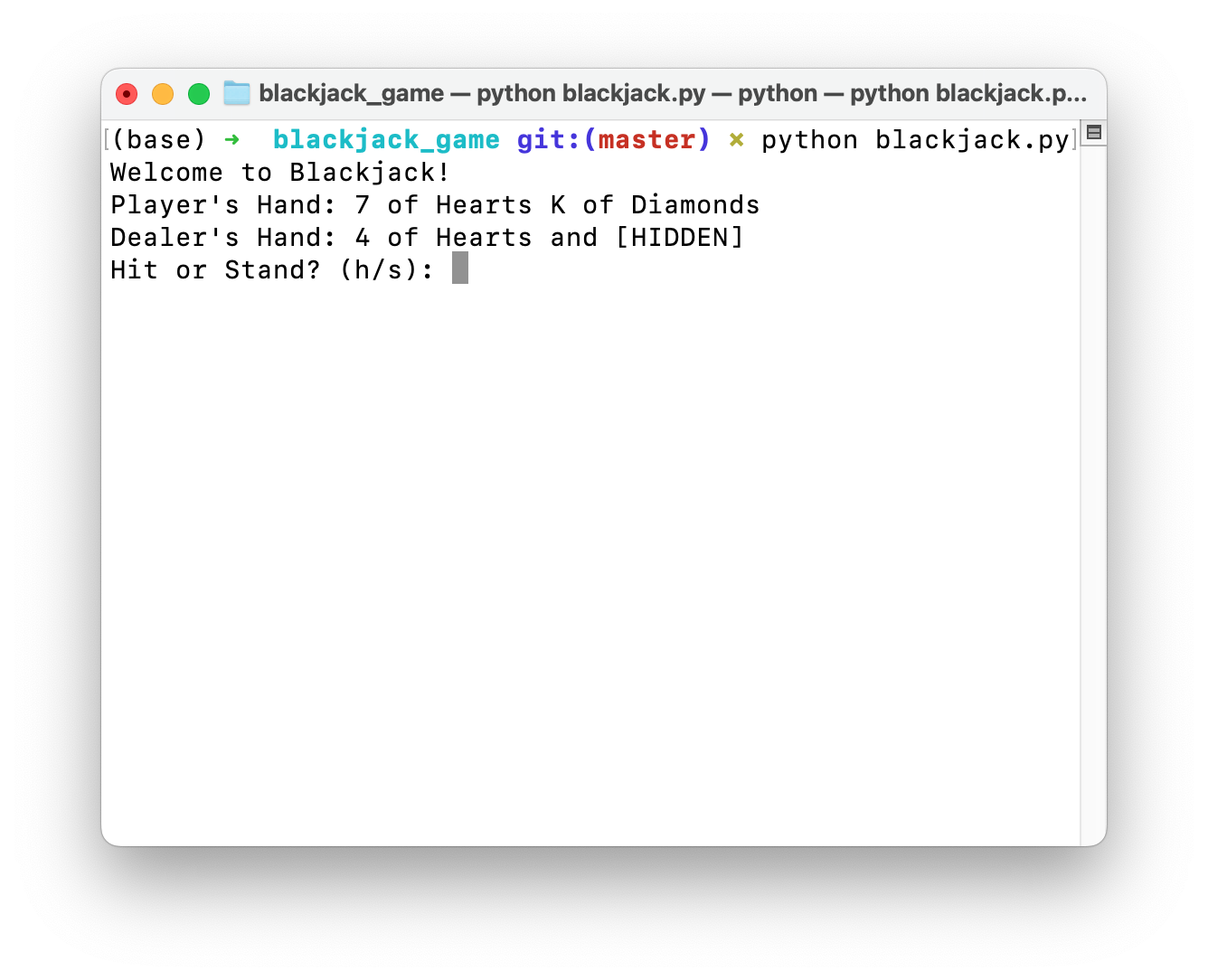
Tapez simplement l2mac "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." , vous obtiendrez une base de code complète pour un jeu entièrement jouable, comme indiqué ici.
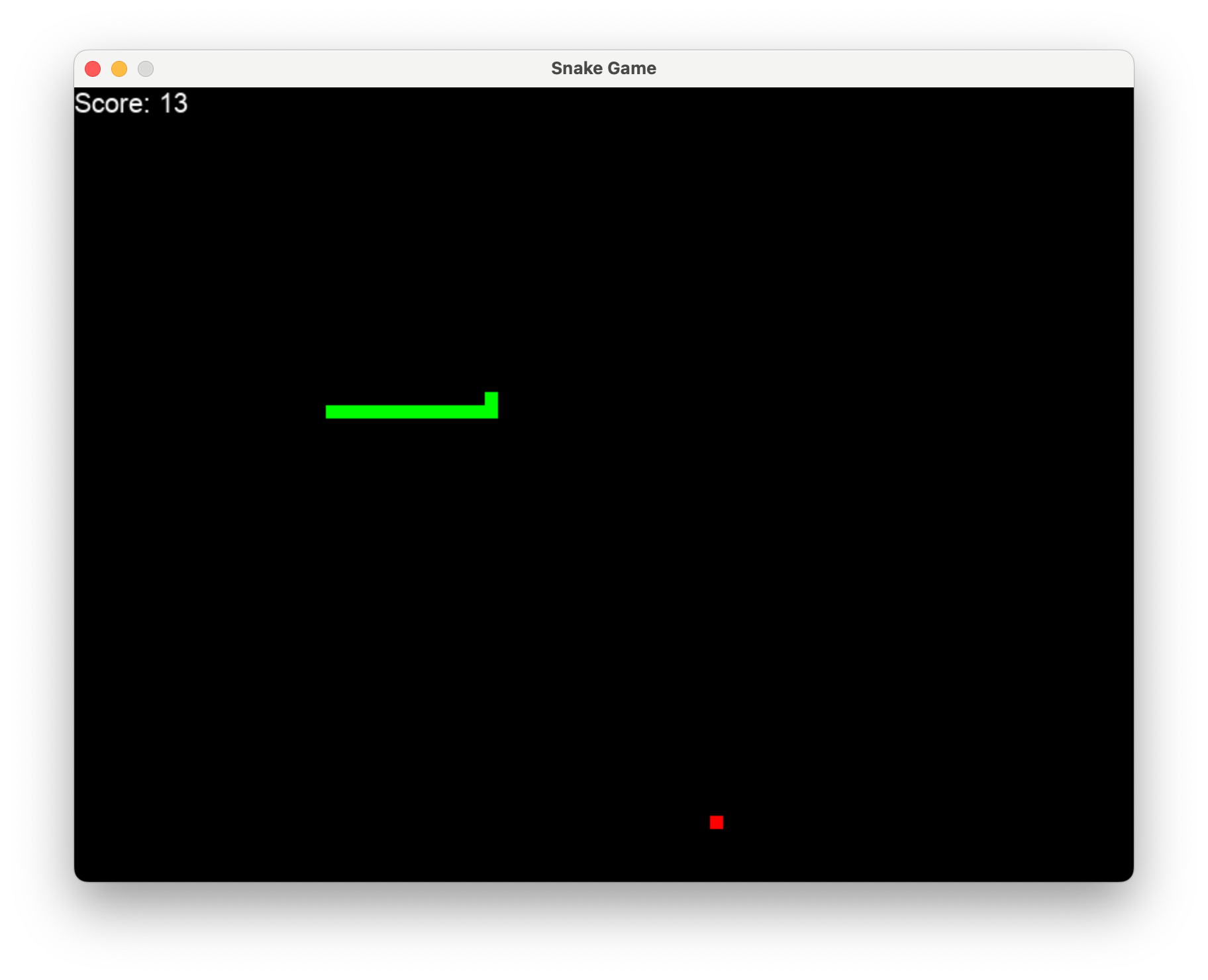
Cliquez ici pour les fichiers complets sur github ou téléchargez-les ici. Le code et l'invite pour générer ceci sont ici.
Cliquez ici pour les fichiers complets sur github ou téléchargez-les ici. Le code et l'invite pour générer ceci sont ici.
Donnez simplement à L2MAC l'invite Write a complete recipe book for the following book title of "Twirls & Tastes: A Journey Through Italian Pasta". Description: "Twirls & Tastes" invites you on a flavorful expedition across Italy, exploring the diverse pasta landscape from the sun-drenched hills of Tuscany to the bustling streets of Naples. Discover regional specialties, learn the stories behind each dish, and master the art of pasta making with easy-to-follow recipes that promise to delight your senses. et il peut générer automatiquement un livre complet de 26 pages.

Cliquez ici pour le livre complet ; L2MAC a produit tout le texte du livre et toutes les images ont été créées avec DALLE.
Les fichiers texte de sortie complets sont sur github ; vous pouvez les télécharger ici. Le code et l'invite pour générer ceci sont ici.
Cliquez ici pour les fichiers complets sur github ou téléchargez-les ici. Le code et l'invite pour générer ceci sont ici.
Nous recherchons activement que vous téléchargiez vos propres applications géniales ici en soumettant un PR avec l'application que vous avez créée, en la partageant avec un problème GitHub ou en la partageant sur le canal Discord.


