Transformer Architectures From Scratch
1.0.0
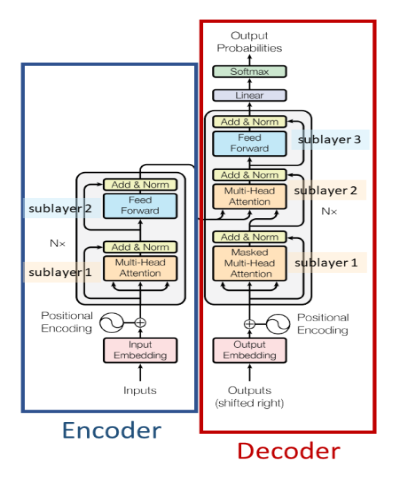
Une architecture d'encodeur-décodeur basée sur l'auto-attention. Il est surtout utilisé pour
Papier - https://arxiv.org/abs/1706.03762
Une architecture d'encodeur basée sur l'auto-attention. Il est surtout utilisé pour
Papier - https://arxiv.org/abs/1810.04805
Un modèle autorégressif basé sur un décodeur basé sur l'auto-attention. Il est surtout utilisé pour
Papier - https://paperswithcode.com/method/gpt
Un modèle autorégressif basé sur un décodeur basé sur l'auto-attention avec un léger changement d'architecture et formé sur un corpus de texte plus grand que GPT-1. Il est surtout utilisé pour
Article - https://d4mucfpksywv.cloudfront.net/better-langage-models/langage-models.pdf
Une architecture d'encodeur de pointe basée sur l'auto-attention pour les applications de vision par ordinateur. Il est surtout utilisé pour
Article - https://arxiv.org/abs/2006.03677
Une architecture de codeur-décodeur basée sur l'auto-attention avec une complexité temporelle linéaire autre que le transformateur qui a une complexité temporelle quadratique. On l'utilise surtout
Article - https://arxiv.org/abs/2009.14794


