airllm
1.0.0

Démarrage rapide | Configurations | MacOS | Exemples de cahiers | FAQ
AirLLM optimise l'utilisation de la mémoire d'inférence, permettant à 70 milliards de modèles de langage volumineux d'exécuter l'inférence sur une seule carte GPU de 4 Go sans quantification, distillation ni élagage. Et vous pouvez maintenant exécuter 405B Llama3.1 sur 8 Go de VRAM .
[20/08/2024] v2.11.0 : prise en charge de Qwen2.5
[2024/08/18] v2.10.1 Prise en charge de l'inférence CPU. Prend en charge les modèles non fragmentés. Merci @NavodPeiris pour cet excellent travail !
[2024/07/30] Prise en charge de Llama3.1 405B (exemple de portable). Prise en charge de la quantification 8 bits/4 bits .
[2024/04/20] AirLLM prend déjà en charge Llama3 de manière native. Exécutez Llama3 70B sur un seul GPU de 4 Go.
[2023/12/25] v2.8.2 : Prise en charge de MacOS exécutant 70 B de grands modèles de langage.
[2023/12/20] v2.7 : prise en charge d'AirLLMMixtral.
[2023/12/20] v2.6 : Ajout d'AutoModel, détection automatique du type de modèle, pas besoin de fournir une classe de modèle pour initialiser le modèle.
[2023/12/18] v2.5 : ajout de la prélecture pour chevaucher le chargement et le calcul du modèle. Amélioration de la vitesse de 10 %.
[2023/12/03] ajout de la prise en charge de ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] ajout de la prise en charge des safetensors. Prend désormais en charge tous les 10 meilleurs modèles du classement Open LLM.
[2023/12/01] airllm 2.0. Compressions prises en charge : accélération du temps d'exécution 3x !
[20/11/2023] airllm Version initiale !
Tout d’abord, installez le package airllm pip.
pip install airllmEnsuite, initialisez AirLLMLlama2, transmettez l'ID du dépôt huggingface du modèle utilisé, ou le chemin local, et l'inférence peut être effectuée de la même manière qu'un modèle de transformateur classique.
( Vous pouvez également spécifier le chemin pour enregistrer le modèle en couches divisé via layer_shards_ saving_path lors du lancement d'AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Remarque : Lors de l'inférence, le modèle d'origine sera d'abord décomposé et enregistré par couche. Veuillez vous assurer qu'il y a suffisamment d'espace disque dans le répertoire de cache Huggingface.
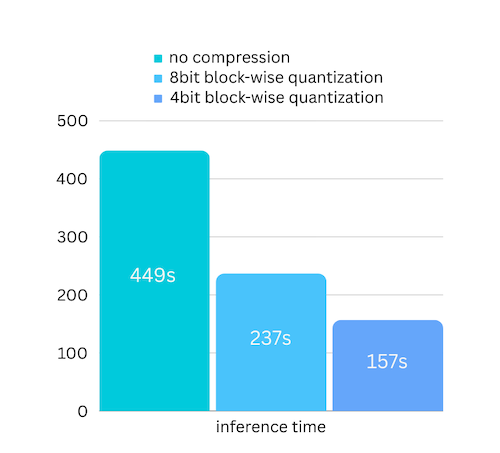
Nous venons d'ajouter une compression de modèle basée sur une compression de modèle basée sur la quantification par blocs. Ce qui peut encore accélérer la vitesse d'inférence jusqu'à 3x , avec une perte de précision presque ignorable ! (voir plus d'évaluation des performances et pourquoi nous utilisons la quantification par blocs dans cet article)
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)La quantification doit normalement quantifier à la fois les poids et les activations pour vraiment accélérer les choses. Il est donc plus difficile de maintenir la précision et d’éviter l’impact des valeurs aberrantes dans toutes sortes d’entrées.
Alors que dans notre cas, le goulot d'étranglement concerne principalement le chargement du disque, il suffit de réduire la taille de chargement du modèle. Ainsi, nous pouvons quantifier uniquement la partie des poids, ce qui est plus facile à garantir l'exactitude.
Lors de l'initialisation du modèle, nous prenons en charge les configurations suivantes :
Installez simplement airllm et exécutez le code de la même manière que sous Linux. Pour en savoir plus, consultez Démarrage rapide.
Exemple [bloc-notes Python] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Exemples de collaborations ici :
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Une grande partie du code est basée sur l'excellent travail de SimJeg lors du concours d'examen Kaggle. Un grand merci à SimJeg :
Compte GitHub @SimJeg, le code sur Kaggle, la discussion associée.
safetensors_rust.SafetensorError : erreur lors de la désérialisation de l'en-tête : MetadataIncompleteBuffer
Si vous rencontrez cette erreur, la cause la plus probable est que vous manquez d'espace disque. Le processus de fractionnement du modèle consomme beaucoup de disque. Voyez ceci. Vous devrez peut-être étendre votre espace disque, effacer le fichier Huggingface .cache et réexécuter.
Très probablement, vous chargez le modèle QWen ou ChatGLM avec la classe Llama2. Essayez ce qui suit :
Pour le modèle QWen :
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Pour le modèle ChatGLM :
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Certains modèles sont des modèles fermés et nécessitent un jeton API Huggingface. Vous pouvez fournir hf_token :
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')Le tokenizer de certains modèles n'a pas de jeton de remplissage, vous pouvez donc définir un jeton de remplissage ou simplement désactiver la configuration de remplissage :
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Si vous trouvez AirLLM utile dans votre recherche et souhaitez le citer, veuillez utiliser l'entrée BibTex suivante :
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Contributions, idées et discussions bienvenues !
Si vous le trouvez utile, s'il vous plaît ou achetez-moi un café !


