hands on llms
1.0.0
En utilisant la conception à 3 pipelines, c'est ce que vous apprendrez à construire dans ce cours ↓
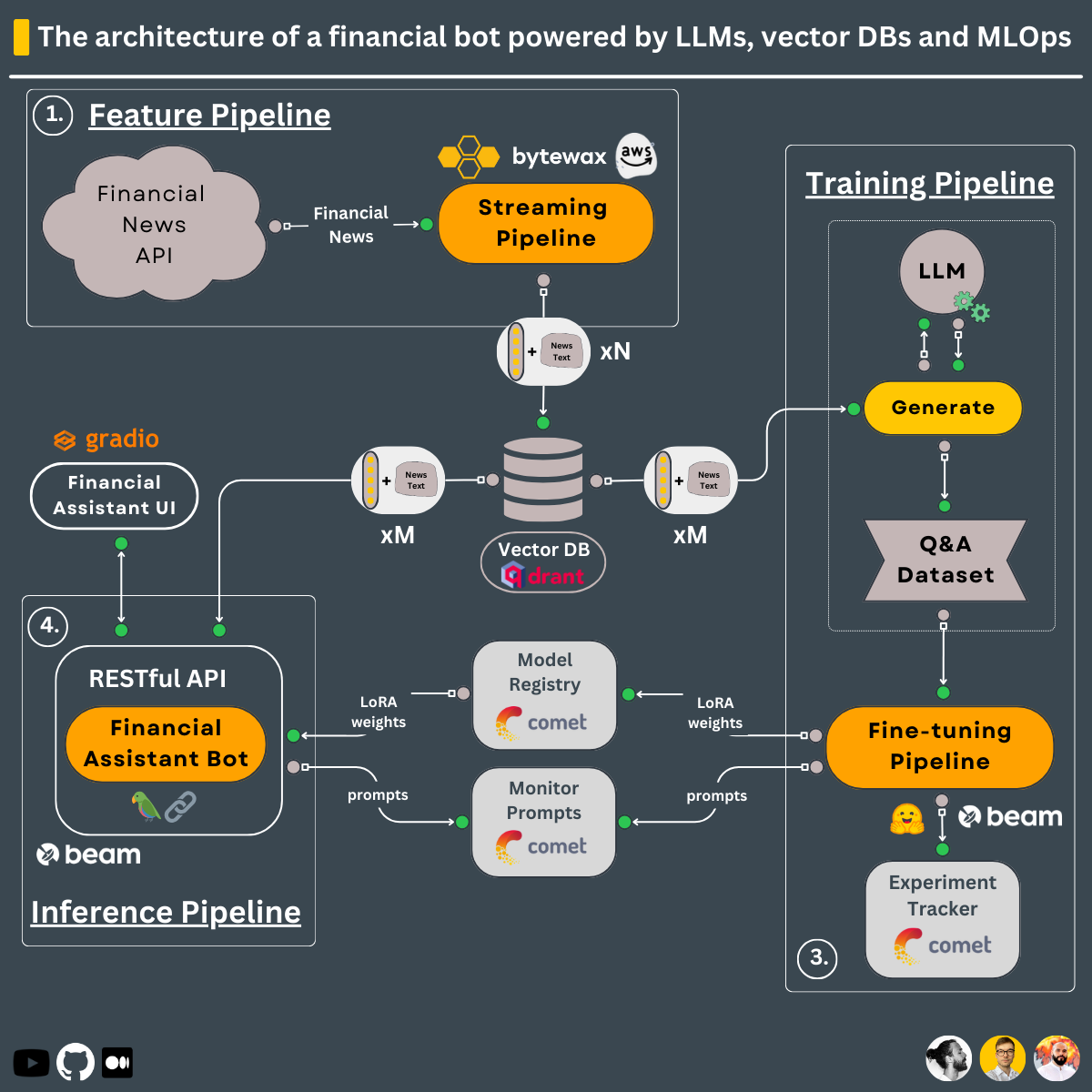
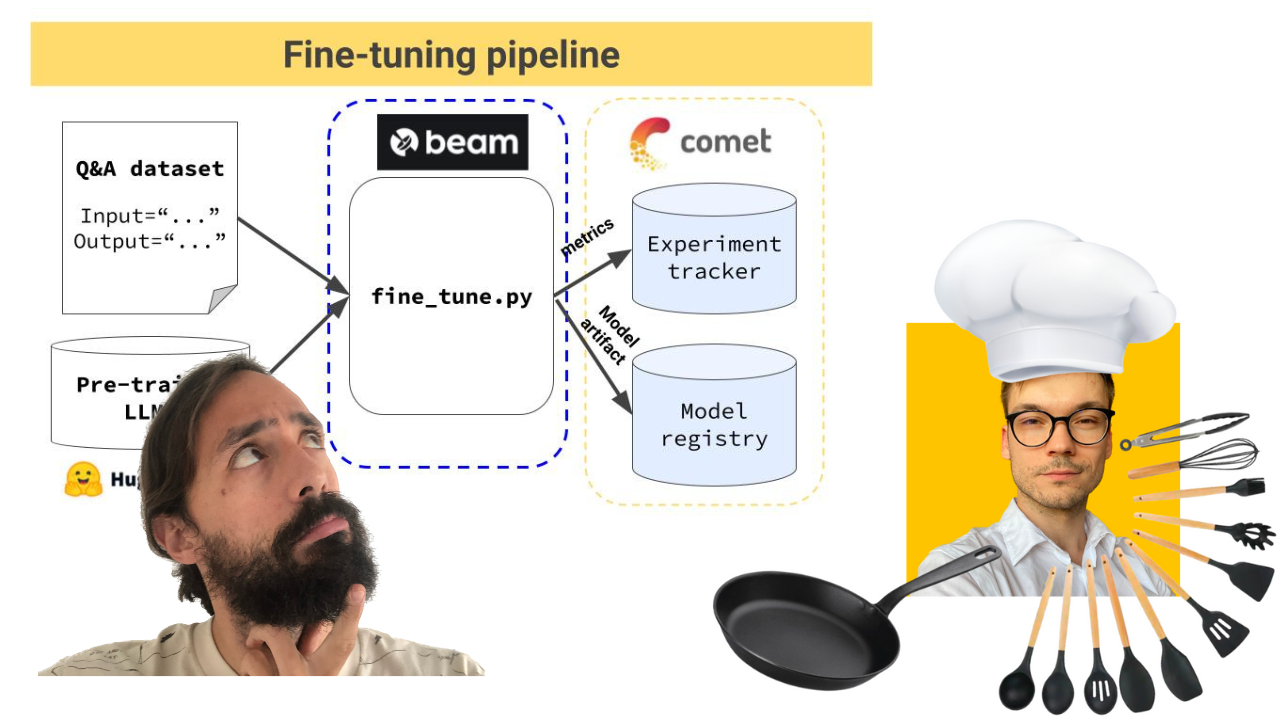
Pipeline de formation qui :
Le pipeline de formation est déployé à l'aide de Beam comme infrastructure GPU sans serveur.
-> Trouvé dans le répertoire modules/training_pipeline .
Remarque : Ne vous inquiétez pas si vous ne disposez pas de la configuration matérielle minimale requise. Nous vous montrerons comment déployer le pipeline de formation sur l'infrastructure sans serveur de Beam et y former le LLM.
Pipeline de fonctionnalités en temps réel qui :
Le pipeline de streaming est automatiquement déployé sur une machine AWS EC2 à l'aide d'un pipeline CI/CD intégré aux actions GitHub.
-> Trouvé dans le répertoire modules/streaming_pipeline .
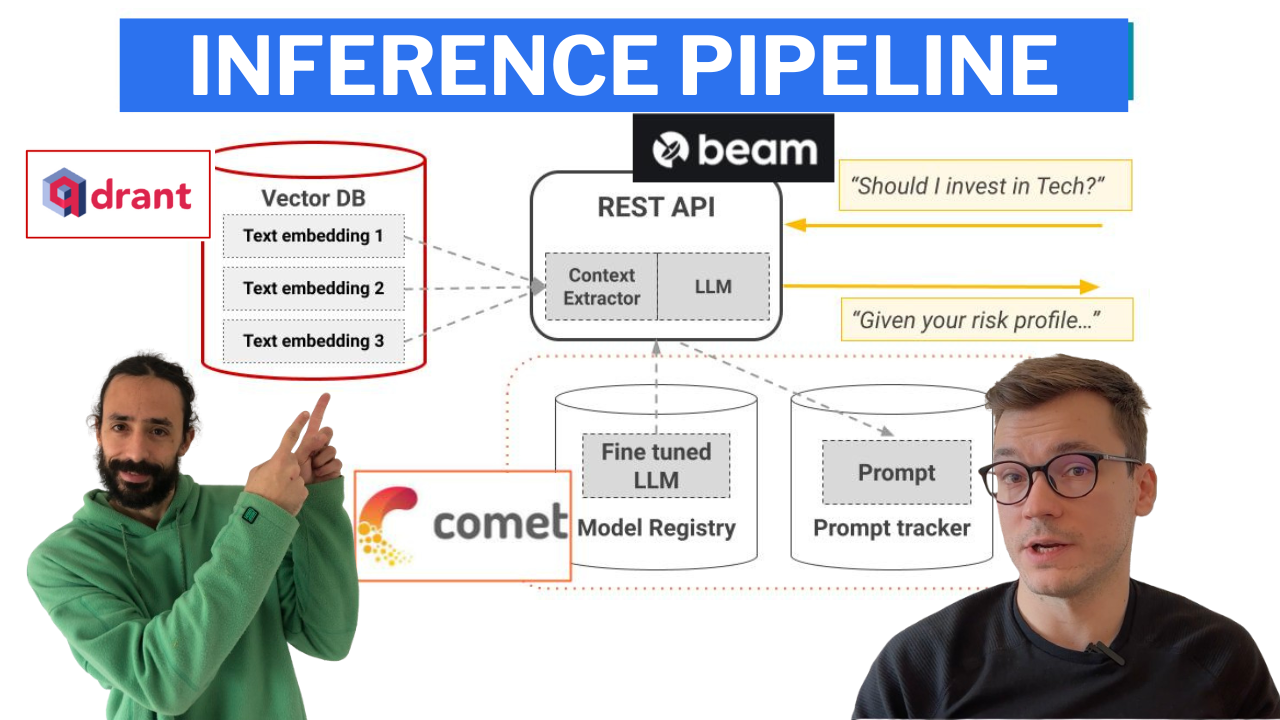
Pipeline d'inférence qui utilise LangChain pour créer une chaîne qui :
Le pipeline d'inférence est déployé à l'aide de Beam en tant qu'infrastructure GPU sans serveur, en tant qu'API RESTful. En outre, il est intégré dans une interface utilisateur à des fins de démonstration, implémentée dans Gradio.
-> Trouvé dans le répertoire modules/financial_bot .
Remarque : Ne vous inquiétez pas si vous ne disposez pas de la configuration matérielle minimale requise. Nous allons vous montrer comment déployer le pipeline d'inférence sur l'infrastructure sans serveur de Beam et appeler le LLM à partir de là.
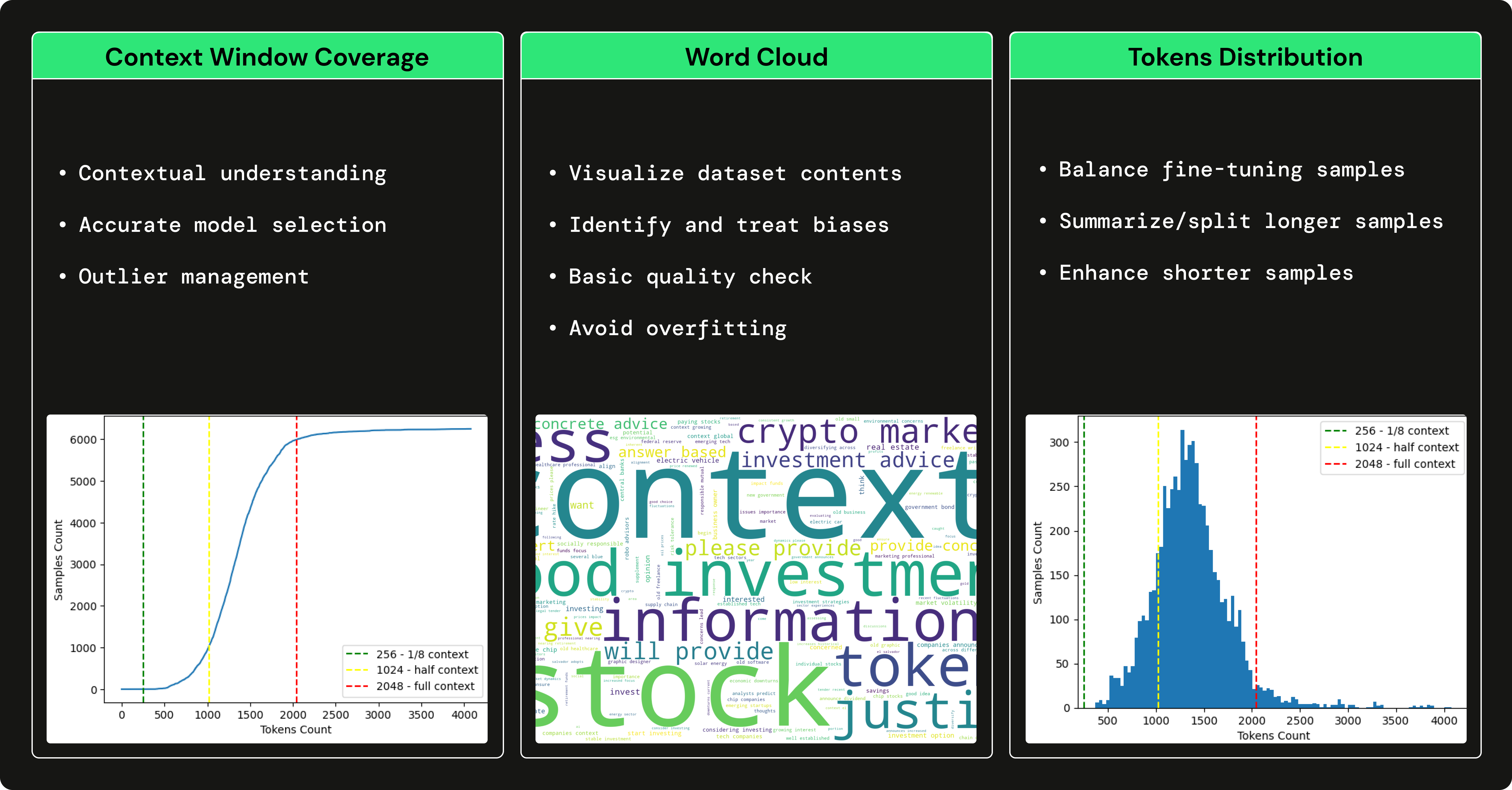
Nous avons utilisé GPT3.5 pour générer un ensemble de données financières de questions-réponses afin d'affiner notre LLM open source afin de nous spécialiser dans l'utilisation de termes financiers et la réponse aux questions financières. L'utilisation d'un grand LLM, tel que GPT3.5 pour générer un ensemble de données qui entraîne un plus petit LLM (par exemple, Falcon 7B) est connue sous le nom de réglage fin avec distillation .
→ Pour comprendre comment nous avons généré l'ensemble de données financières de questions-réponses, consultez cet article rédigé par Pau Labarta.
→ Pour voir une analyse complète de l'ensemble de données financières de questions-réponses, consultez la sous-section dataset_analysis du cours rédigé par Alexandru Razvant.
Avant de plonger dans les modules, vous devez configurer quelques outils externes supplémentaires pour le cours.
REMARQUE : Vous pouvez les configurer au fur et à mesure pour chaque module, car nous vous indiquerons dans chaque module ce dont vous avez besoin.
financial news data source
Suivez ce document pour vous montrer comment créer un compte GRATUIT et générer les clés API dont vous aurez besoin dans ce cours.
Remarque : 1x connexion de données Alpaca est GRATUITE.
serverless vector DB
Accédez à Qdrant et créez un compte GRATUIT.
Ensuite, suivez ce document pour savoir comment générer les clés API dont vous aurez besoin dans ce cours.
Remarque : nous utiliserons uniquement le plan freemium de Qdrant.
serverless ML platform
Accédez à Comet ML et créez un compte GRATUIT.
Ensuite, suivez ce guide pour générer une CLÉ API et un nouveau projet, dont vous aurez besoin dans le cours.
Remarque : nous utiliserons uniquement le plan freemium de Comet ML.
serverless GPU compute | training & inference pipelines
Accédez à Beam et créez un compte GRATUIT.
Ensuite, vous devez suivre leur guide d'installation pour installer leur CLI et la configurer avec vos informations d'identification Beam.
Pour en savoir plus sur Beam, voici un guide d'introduction.
Remarque : Vous disposez d’environ 10 heures de calcul gratuites. Ensuite, vous ne payez que ce que vous utilisez. Si vous disposez d'un GPU Nvidia > 8 Go de VRAM et que vous ne souhaitez pas déployer les pipelines de formation et d'inférence, l'utilisation de Beam est facultative.
Lors de l’utilisation de Poetry, nous avons eu des problèmes pour localiser la CLI Beam dans un environnement virtuel Poetry. Pour résoudre ce problème, après avoir installé Beam, nous créons un lien symbolique qui pointe vers les binaires de Poetry, comme suit :
export COURSE_MODULE_PATH= < your-course-module-path > # e.g., modules/training_pipeline
cd $COURSE_MODULE_PATH
export POETRY_ENV_PATH= $( dirname $( dirname $( poetry run which python ) ) )
ln -s /usr/local/bin/beam ${POETRY_ENV_PATH} /bin/beam cloud compute | feature pipeline
Accédez à AWS, créez un compte et générez une paire d'informations d'identification.
Ensuite, téléchargez et installez leur AWS CLI v2.11.22 et configurez-le avec vos informations d'identification.
Remarque : vous ne paierez que ce que vous utilisez. Vous déployerez uniquement une VM t2.small EC2, ce qui ne coûte que ~$0.023 /heure. Si vous ne souhaitez pas déployer le pipeline de fonctionnalités, l'utilisation d'AWS est facultative.
Chaque module a ses dépendances et ses scripts. Dans une configuration de production, chaque module aurait son référentiel, mais dans ce cas d'utilisation, à des fins d'apprentissage, nous mettons tout au même endroit :
Ainsi, consultez le README pour chaque module individuellement pour voir comment l'installer et l'utiliser :
Nous vous encourageons fortement à cloner ce référentiel et à reproduire tout ce que nous avons fait pour tirer le meilleur parti de ce cours.
Dans les conférences vidéo, les articles et la documentation README de chaque module, vous trouverez des instructions étape par étape.
Bon apprentissage !
Le code GitHub (publié sous licence MIT) et les conférences vidéo (publiées sur YouTube) sont entièrement gratuits. Le sera toujours.
Les leçons Medium sont publiées sous le mur payant de Medium. Si vous l'avez déjà, ils sont gratuits. Sinon, vous devez payer des frais mensuels de 5 $ pour lire les articles.
Si vous avez des questions ou des problèmes pendant le cours, nous vous encourageons à créer un numéro dans ce référentiel où vous pourrez expliquer en profondeur tout ce dont vous avez besoin.
Sinon, vous pouvez également contacter les professeurs sur LinkedIn :
Cliquez ici pour regarder la vidéo ?

Cliquez ici pour regarder la vidéo ?
Cliquez ici pour regarder la vidéo ?

Cliquez ici pour regarder la vidéo ?

Cliquez ici pour regarder la vidéo ?
To understand the entire code step-by-step, check out our articles ↓
Ce cours est un projet open source publié sous licence MIT. Ainsi, tant que vous distribuez notre LICENCE et reconnaissez notre travail, vous pouvez cloner ou bifurquer ce projet en toute sécurité et l'utiliser comme source d'inspiration pour tout ce que vous voulez (par exemple, des projets universitaires, des projets de diplôme collégial, etc.).
 | Pau Labarta Bajo | Ingénieur ML & MLOps Senior Professeur principal. Le gars des leçons vidéo. Twitter/X YouTube Newsletter ML du monde réel Site ML du monde réel |
 | Alexandru Razvant | Ingénieur ML senior Deuxième chef. L'ingénieur dans les coulisses. Neura saute |
 | Paul Iusztin | Ingénieur ML & MLOps Senior Chef principal. Les gars qui apparaissent au hasard dans les cours vidéo. Twitter/X Newsletter sur le décodage du ML Site personnel | Centre ML et MLOps |


