EasyDetect
1.0.0

Un cadre de détection d'hallucinations multimodales facile à utiliser pour les MLLM
Remerciements • Benchmark • Démo • Présentation • ModelZoo • Installation • Démarrage rapide • Citation
Reconnaissance
Aperçu
Hallucination multimodale unifiée
Ensemble de données : Statistique MHalluBench
Cadre : Illustration UniHD
ModèleZoo
Installation
⏩Démarrage rapide
Citation
2024-05-17 L'article Unified Hallucination Detection for Multimodal Large Language Models est accepté par la conférence principale de l'ACL 2024.
2024-04-21 Nous remplaçons tous les modèles de base de la démo par nos propres modèles formés, réduisant ainsi considérablement le temps d'inférence.
2024-04-21 Nous publions notre modèle open source de détection d'hallucinations HalDet-LLAVA, qui peut être téléchargé dans huggingface, modelscope et wisemodel.
2024-02-10 Nous publions la démo EasyDetect .
2024-02-05 Nous publions l'article : « Unified Hallucination Detection for Multimodal Large Language Models » avec un nouveau benchmark MHaluBench ! Nous attendons avec impatience tout commentaire ou discussion sur ce sujet :)
2023-10-20 Le projet EasyDetect a été lancé et est en cours de développement.
Une partie de la mise en œuvre de ce projet a été assistée et inspirée par les boîtes à outils relatives aux hallucinations, notamment FactTool, Woodpecker et autres. Ce référentiel bénéficie également du projet public de mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO et MAERec. Nous suivons la même licence pour l'open source et les remercions pour leurs contributions à la communauté.
EasyDetect est un package systématique proposé comme cadre de détection d'hallucinations facile à utiliser pour les modèles multimodaux de langage large (MLLM) comme GPT-4V, Gemini, LlaVA dans vos expériences de recherche.
Une condition préalable à une détection unifiée est la catégorisation cohérente des principales catégories d’hallucinations au sein des MLLM. Notre article examine superficiellement la taxonomie des hallucinations suivante dans une perspective unifiée :


Figure 1 : La détection multimodale unifiée des hallucinations vise à identifier et à détecter les hallucinations conflictuelles en termes de modalités à différents niveaux tels que l'objet, l'attribut et le texte de la scène, ainsi que les hallucinations contradictoires entre les faits dans l'image vers le texte et le texte vers l'image. génération.
Hallucination en conflit de modalités. Les MLLM génèrent parfois des sorties qui entrent en conflit avec les entrées d'autres modalités, entraînant des problèmes tels que des objets, des attributs ou un texte de scène incorrects. Un exemple dans la figure (a) ci-dessus inclut un MLLM décrivant de manière inexacte l'uniforme d'un athlète, mettant en évidence un conflit au niveau des attributs en raison de la capacité limitée des MLLM à obtenir un alignement texte-image à granularité fine.
Hallucination contradictoire avec les faits. Les résultats des MLLM peuvent contredire les connaissances factuelles établies. Les modèles image-texte peuvent générer des récits qui s'éloignent du contenu réel en incorporant des faits non pertinents, tandis que les modèles texte-image peuvent produire des visuels qui ne reflètent pas les connaissances factuelles contenues dans les invites textuelles. Ces divergences soulignent la lutte des MLLM pour maintenir la cohérence factuelle, ce qui représente un défi important dans le domaine.
La détection unifiée des hallucinations multimodales nécessite la vérification de chaque paire image-texte a={v, x} , où v désigne soit l'entrée visuelle fournie à un MLLM, soit la sortie visuelle synthétisée par celui-ci. De manière correspondante, x signifie la réponse textuelle générée par le MLLM basée sur v ou la requête textuelle de l'utilisateur pour synthétiser v . Dans cette tâche, chaque x peut contenir plusieurs revendications, notées a déterminer si elle est « hallucinatoire » ou « non hallucinatoire », en fournissant une justification de leurs jugements basée sur la définition fournie de l'hallucination. La détection d'hallucinations textuelles à partir des LLM dénote un sous-cas dans ce contexte, où v est nul.
Pour faire avancer cette trajectoire de recherche, nous introduisons le benchmark de méta-évaluation MHaluBench, qui englobe le contenu de la génération image-texte et texte-image, visant à évaluer rigoureusement les progrès des détecteurs d'hallucinations multimodaux. Des détails statistiques supplémentaires sur MHaluBench sont fournis dans les figures ci-dessous.
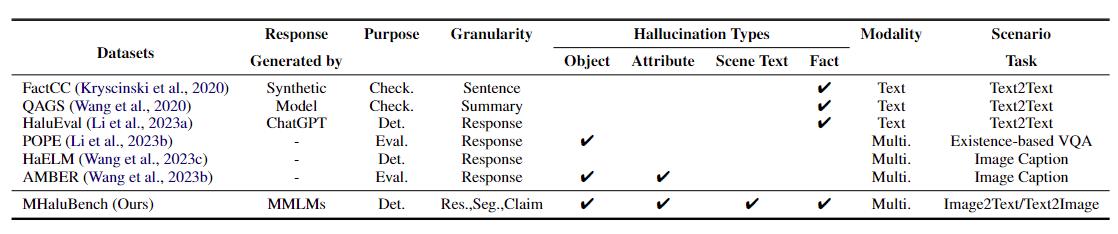
Tableau 1 : Une comparaison des critères de référence par rapport à la vérification des faits ou à l'évaluation des hallucinations existantes. "Vérifier." indique la vérification de la cohérence factuelle, « Eval ». désigne l'évaluation des hallucinations générées par différents LLM, et sa réponse est basée sur différents LLM testés, tandis que « Det ». incarne l'évaluation de la capacité d'un détecteur à identifier les hallucinations.
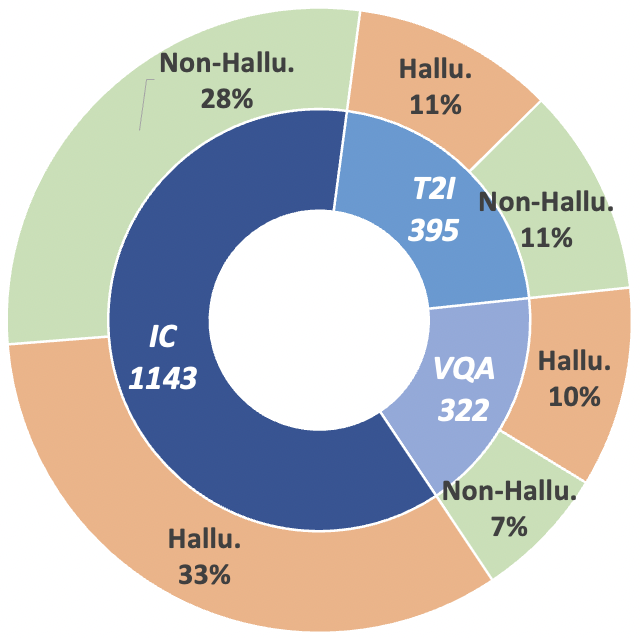
Figure 2 : Statistiques de données au niveau des réclamations de MHaluBench. "IC" signifie sous-titrage d'image et "T2I" indique respectivement la synthèse texte-image.
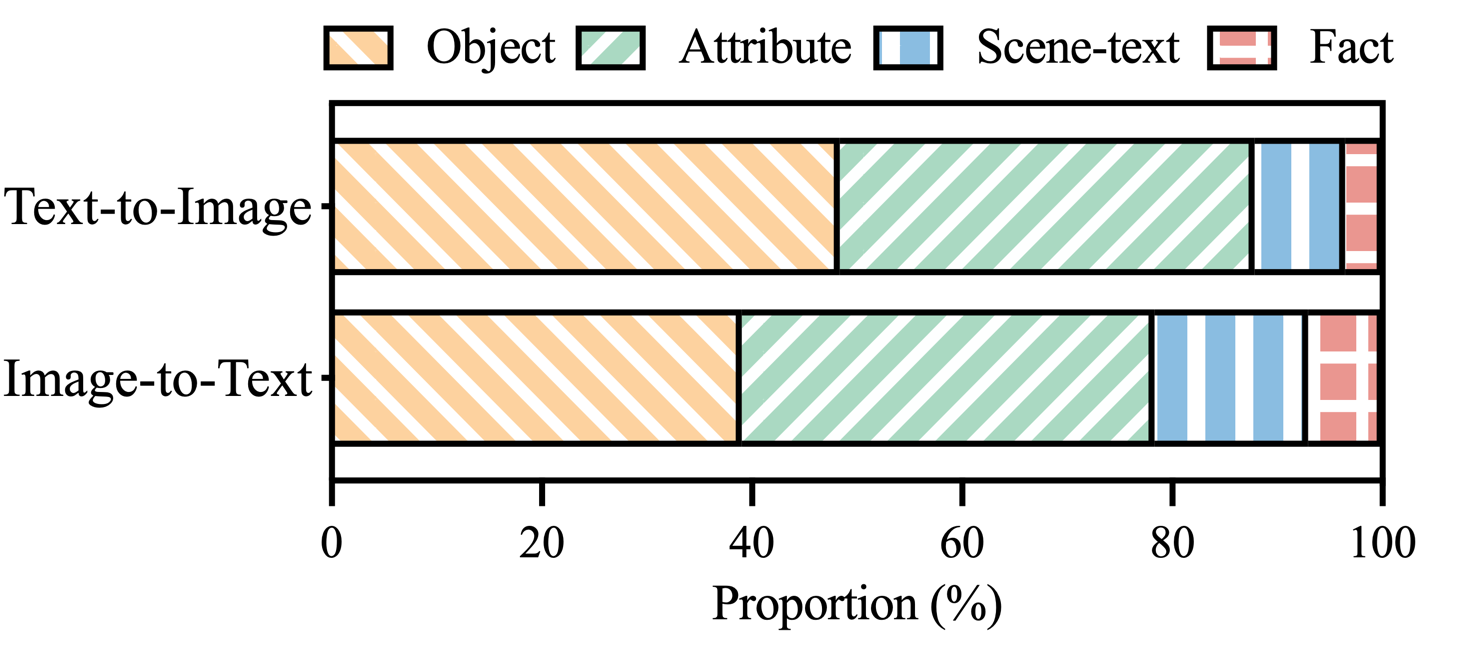
Figure 3 : Répartition des catégories d'hallucinations dans les allégations d'hallucinations de MHaluBench.
Pour répondre aux principaux défis de la détection des hallucinations, nous introduisons un cadre unifié dans la figure 4 qui aborde systématiquement l'identification multimodale des hallucinations pour les tâches image-texte et texte-image. Notre cadre capitalise sur les atouts spécifiques au domaine de divers outils pour recueillir efficacement des preuves multimodales permettant de confirmer les hallucinations.
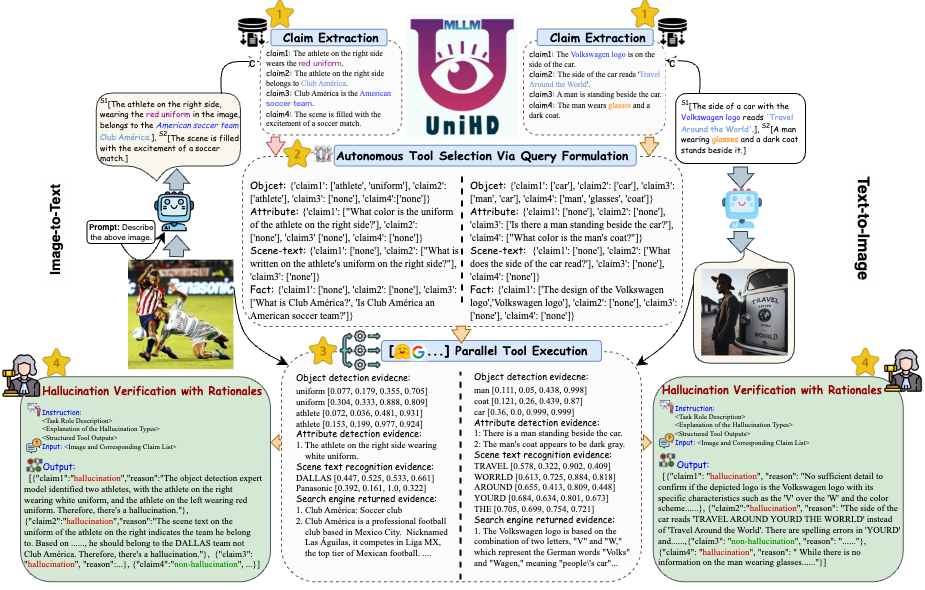
Figure 4 : L’illustration spécifique d’UniHD pour la détection unifiée des hallucinations multimodales.
Vous pouvez télécharger deux versions de HalDet-LLaVA, 7b et 13b, sur trois plateformes : HuggingFace, ModelScope et WiseModel.
| ÉtreindreVisage | ModèlePortée | Modèle sage |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
Résultats au niveau de la revendication sur l'ensemble de données de validation
L'auto-vérification (GPT-4V) signifie utiliser GPT-4V avec 0 ou 2 cas
UniHD (GPT-4V/GPT-4o) signifie utiliser GPT-4V/GPT-4o avec des informations sur 2 prises de vue et sur les outils.
HalDet (LLAVA) signifie utiliser LLAVA-v1.5 formé sur nos ensembles de données de train
| type de tâche | modèle | Acc | Préc moyenne | Rappel moyen | Mac.F1 |
| image en texte | Auto-vérification 0shot (GPV-4V) | 75.09 | 74,94 | 75.19 | 74,97 |
| Auto-vérification 2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| HalDet (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77,69 | |
| UniHD(GPT-4V) | 81.91 | 81,81 | 81.52 | 81,63 | |
| UniHD(GPT-4o) | 86.08 | 85,89 | 86.07 | 85,96 | |
| texte en image | Auto-vérification 0shot (GPV-4V) | 76.20 | 79.31 | 75,99 | 75.45 |
| Auto-vérification 2shot (GPV-4V) | 80,76 | 81.16 | 80,69 | 80,67 | |
| HalDet (LLAVA-7b) | 67.35 | 69.31 | 67,50 | 66,62 | |
| HalDet (LLAVA-13b) | 74,74 | 76,68 | 74,88 | 74.34 | |
| UniHD(GPT-4V) | 85,82 | 85,83 | 85,83 | 85,82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
Pour afficher des informations plus détaillées sur HalDet-LLaVA et l'ensemble de données ferroviaires, veuillez vous référer au fichier Lisez-moi.
Installation pour le développement local :
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Installation des outils (GroundingDINO et MAERec) :
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
Nous fournissons un exemple de code permettant aux utilisateurs de démarrer rapidement avec EasyDetect.
Les utilisateurs peuvent facilement configurer les paramètres d'EasyDetect dans un fichier yaml ou simplement utiliser rapidement les paramètres par défaut dans le fichier de configuration que nous fournissons. Le chemin du fichier de configuration est EasyDetect/pipeline/config/config.yaml
openai : api_key : saisissez votre clé API openai
base_url : saisissez base_url, la valeur par défaut est Aucun
température : 0,2
max_tokens : 1024outil :
detect:groundingdino_config : le chemin de GroundingDINO_SwinT_OGC.pymodel_path : le chemin de groundingdino_swint_ogc.pthdevice : cuda:0BOX_TRESHOLD : 0,35TEXT_TRESHOLD : 0,25AREA_THRESHOLD : 0,001
ocr:dbnetpp_config : le chemin de dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path : le chemin de dbnetpp.pthmaerec_config : le chemin de maerec_b_union14m.pymaerec_path : le chemin de maerec_b.pthdevice : cuda:0content : word.numbercachefiles_path : le chemin des fichiers cache pour enregistrer les images temporairesBOX_TRESHOLD : 0,2TEXT_TRESHOLD : 0,25
google_serper:serper_api_key : saisissez vos clés d'API de serveurnippet_cnt : 10prompts : claim_generate : pipeline/prompts/claim_generate.yaml
query_generate : pipeline/prompts/query_generate.yaml
vérifier : pipeline/prompts/verify.yamlExemple de code
from pipeline.run_pipeline import *pipeline = Pipeline()text = "Le café dans l'image s'appelle "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, claims_list = pipeline .run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
Veuillez citer notre référentiel si vous utilisez EasyDetect dans votre travail.
@article{chen23factchd, author = {Xiang Chen et Duanzheng Song et Honghao Gui et Chengxi Wang et Ningyu Zhang et Jiang Yong et Fei Huang et Chengfei Lv et Dan Zhang et Huajun Chen}, title = {FactCHD : analyse comparative de la détection des hallucinations contradictoires avec les faits }, journal = {CoRR}, volume = {abs/2310.12086}, année = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {bibliographie informatique dblp, https://dblp.org}}@inproceedings{chen-etal-2024- unified-hallucination,title = "Détection unifiée des hallucinations pour les grands modèles de langage multimodaux", author = "Chen, Xiang et Wang, Chenxi et Xue, Yida et Zhang, Ningyu et Yang, Xiaoyan et Li, Qiang et Shen, Yue et Liang, Lei et Gu, Jinjie et Chen, Huajun", éditeur = " Ku, Lun-Wei et Martins, Andre et Srikumar, Vivek " ,booktitle = "Actes de la 62e réunion annuelle de l'Association for Computational Linguistics (Volume 1 : Long Papers)", mois = août, année = "2024", adresse = "Bangkok, Thaïlande", éditeur = "Association pour la linguistique computationnelle", url = "https://aclanthology.org/2024.acl-long.178", pages = "3235--3252",
}Nous proposerons une maintenance à long terme pour corriger les bugs, résoudre les problèmes et répondre aux nouvelles demandes. Donc, si vous rencontrez des problèmes, veuillez nous en faire part.


