QuillGPT
1.0.0

QuillGPT est une implémentation du bloc décodeur GPT basée sur l'architecture de l'article Attention is All You Need de Vaswani et. al. implémenté dans PyTorch. De plus, ce référentiel contient deux modèles pré-entraînés : Shakespeare GPT et Harpoon GPT, ainsi que leurs poids entraînés. Pour faciliter l'expérimentation et le déploiement, un Streamlit Playground est fourni pour l'exploration interactive de ces modèles et le microservice FastAPI implémenté avec la conteneurisation Docker pour un déploiement évolutif. Vous trouverez également des scripts Python pour entraîner de nouveaux modèles GPT et effectuer des inférences sur ceux-ci, ainsi que des blocs-notes présentant les modèles entraînés. Pour faciliter l'encodage et le décodage du texte, un simple tokenizer est implémenté. Explorez QuillGPT pour utiliser ces outils et améliorer vos projets de traitement du langage naturel !
Il existe deux modèles et poids pré-entraînés inclus dans ce référentiel.
| Fonctionnalité | GPT shakespearien | Harpon GPT |
|---|---|---|
| Paramètres | 10,7 millions | 226 M |
| Poids | Poids | Poids |
| Configuration du modèle | Configuration | Configuration |
| Données de formation | Texte de pièces shakespeariennes (input.txt) | Texte aléatoire provenant de livres (corpus.txt) |
| Type d'intégration | Intégrations de personnages | Intégrations de personnages |
| Carnet de formation | Carnet de notes | Carnet de notes |
| Matériel | Nvidia T4 | Nvidia A100 |
| Perte de formation et de validation | 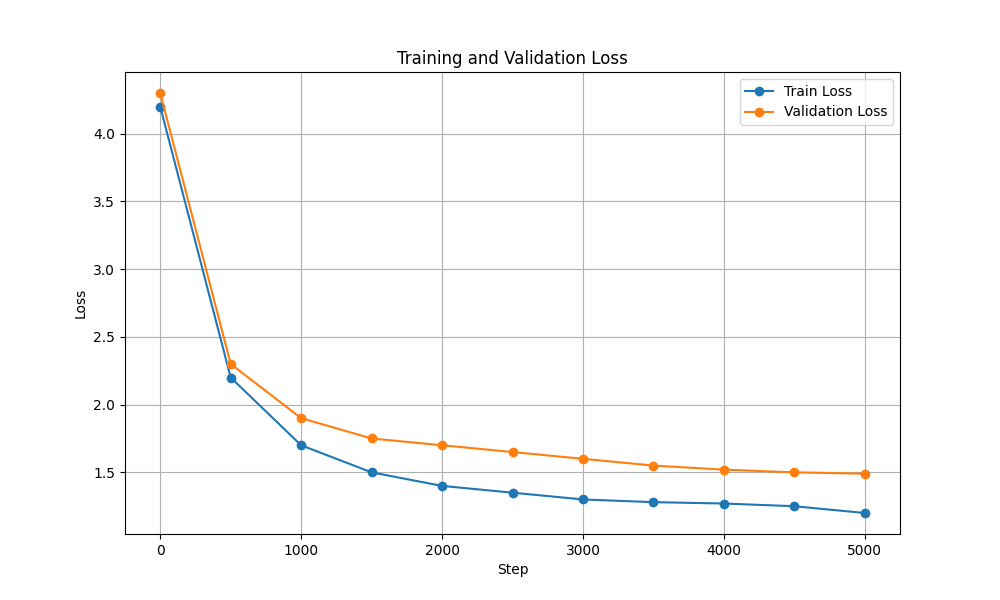 | 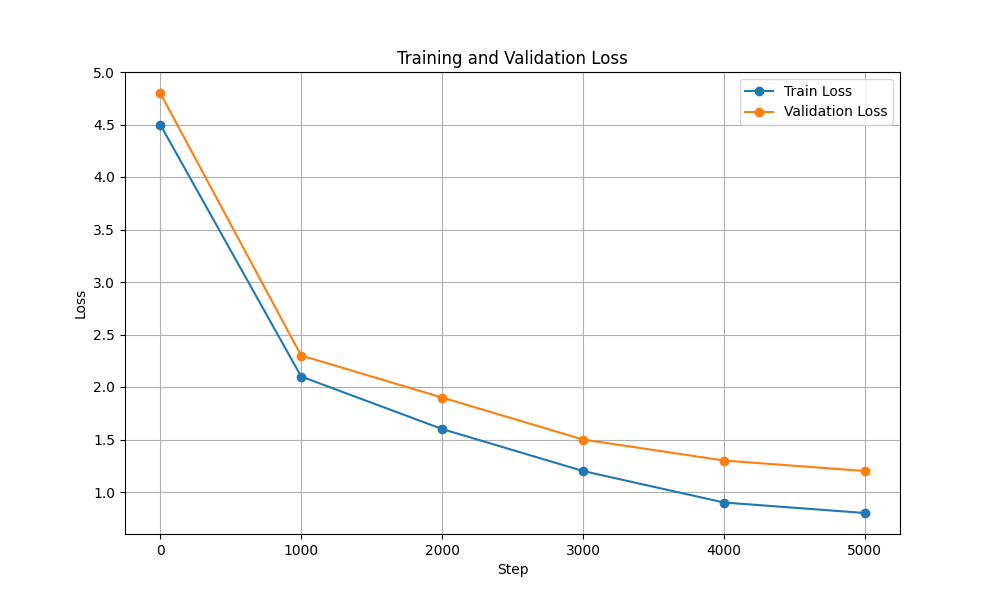 |
Pour exécuter les scripts de formation et d'inférence, procédez comme suit :
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtAssurez-vous de télécharger les poids pour Harpoon GPT à partir d'ici avant de continuer !
Il est hébergé sur Streamlit Cloud Service. Vous pouvez le visiter via le lien ici.
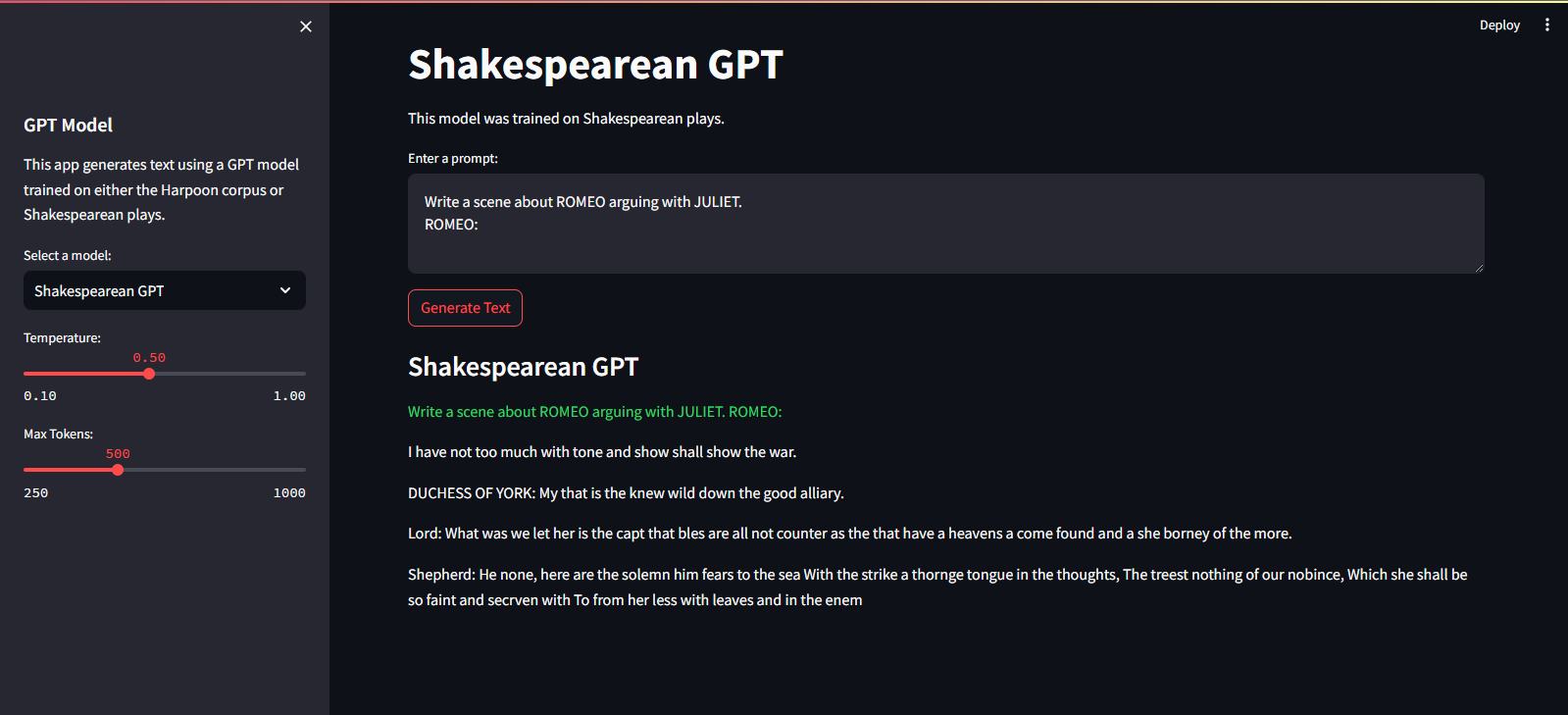
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devPour entraîner le modèle GPT, procédez comme suit :
Préparez les données. Mettez toutes les données texte dans un seul fichier .txt et enregistrez-le.
Écrivez les configurations du transformateur et enregistrez le fichier.
Par exemple : json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Entraîner le modèle à l'aide de scripts scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Vous pouvez modifier config_path , data_path et output_dir selon vos besoins.)
output_dir spécifié dans la commande.Après la formation, vous pouvez utiliser le modèle GPT entraîné pour la génération de texte. Voici un exemple d'utilisation du modèle entraîné pour l'inférence :
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 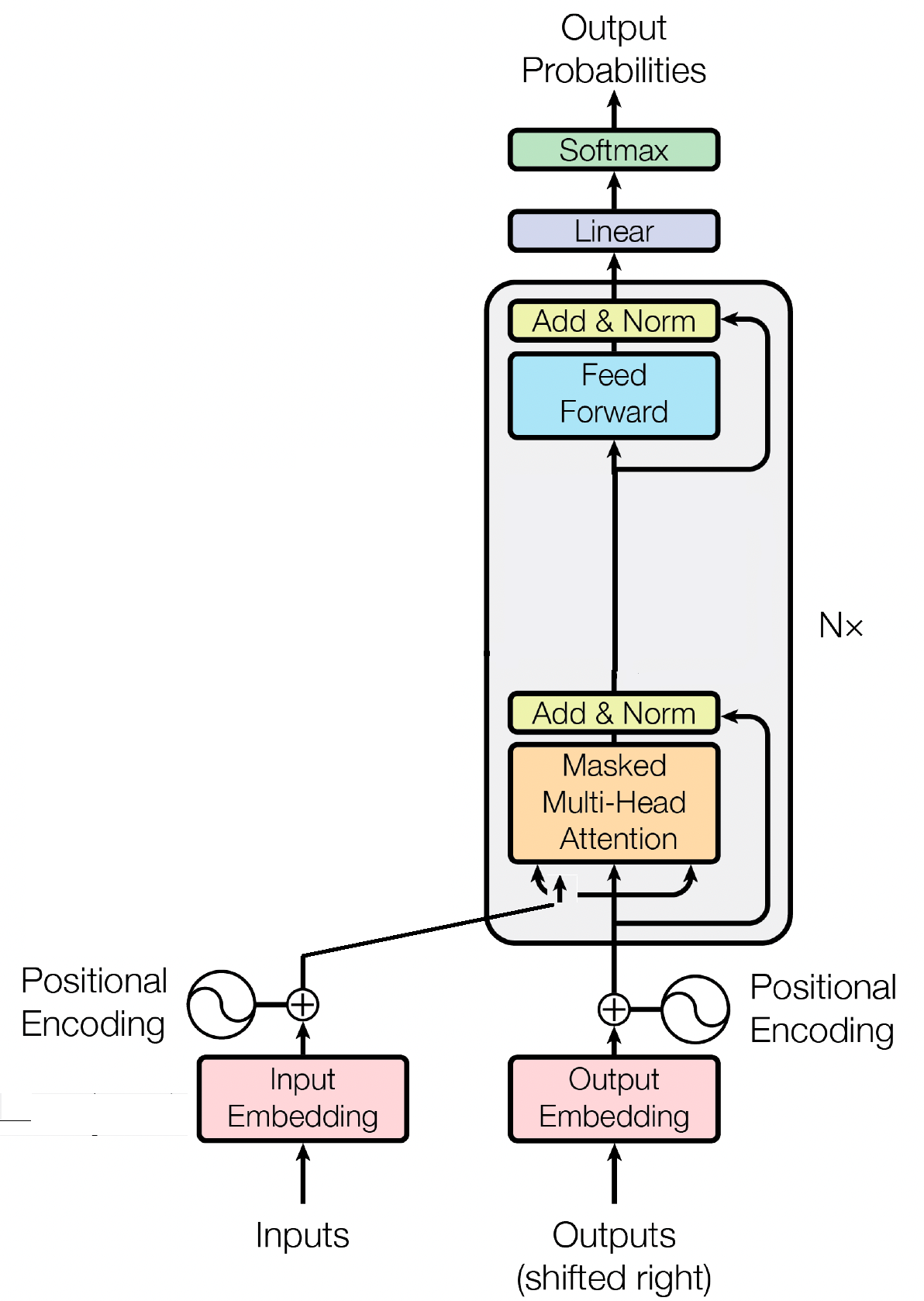
Le bloc décodeur est un composant crucial du modèle GPT (Generative Pre-trained Transformer), c'est là que GPT génère réellement le texte. Il exploite le mécanisme d’auto-attention pour traiter les séquences d’entrée et générer des sorties cohérentes. Chaque bloc de décodeur se compose de plusieurs couches, notamment des couches d'auto-attention, des réseaux neuronaux à action directe et une normalisation des couches. Les couches d'auto-attention permettent au modèle de peser l'importance des différents mots dans une séquence, capturant le contexte et les dépendances quelle que soit leur position. Cela permet au modèle GPT de générer un texte contextuellement pertinent.
Les intégrations d'entrée jouent un rôle crucial dans les modèles basés sur des transformateurs comme GPT en transformant les jetons d'entrée en représentations numériques significatives. Ces intégrations servent d'entrée initiale pour le modèle, capturant des informations sémantiques sur les mots de la séquence. Le processus consiste à mapper chaque jeton de la séquence d’entrée sur un espace vectoriel de grande dimension, où les jetons similaires sont rapprochés les uns des autres. Cela permet au modèle de comprendre les relations entre différents mots et d'apprendre efficacement des données d'entrée. Les intégrations d'entrée sont ensuite introduites dans les couches suivantes du modèle pour un traitement ultérieur.
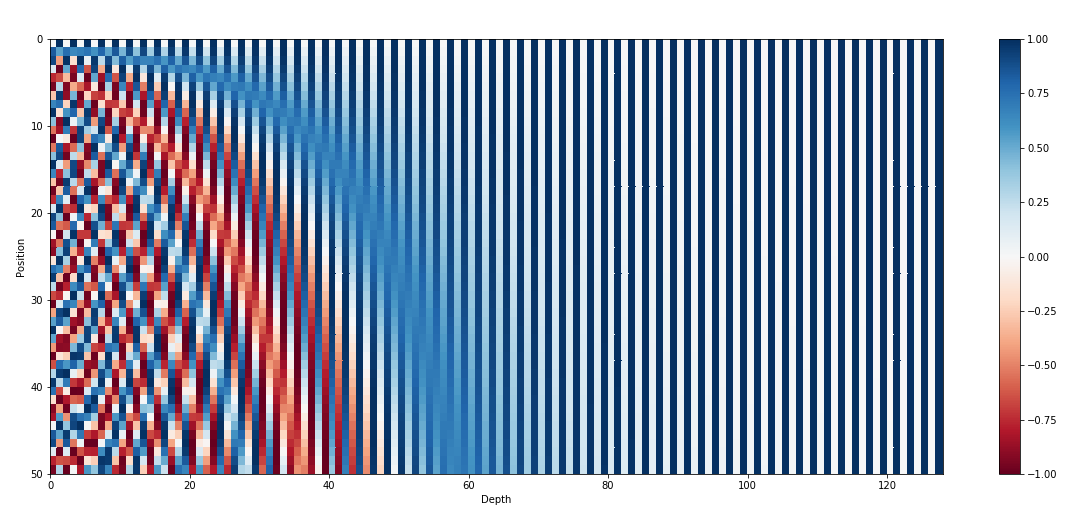
En plus des intégrations d'entrée, les intégrations positionnelles sont un autre composant essentiel des architectures de transformateur telles que GPT. Étant donné que les transformateurs manquent d'informations inhérentes sur l'ordre des jetons dans une séquence, des intégrations positionnelles sont introduites pour fournir au modèle des informations de position. Ces intégrations codent la position de chaque jeton dans la séquence, permettant au modèle de distinguer les jetons en fonction de leurs positions. En incorporant des intégrations positionnelles, les transformateurs comme GPT peuvent capturer efficacement la nature séquentielle des données et générer des sorties cohérentes qui maintiennent l'ordre correct des mots dans le texte généré.

L'attention personnelle, un mécanisme fondamental dans les modèles basés sur des transformateurs comme GPT, fonctionne en attribuant des scores d'importance à différents mots dans une séquence. Ce processus implique trois étapes clés : calculer les scores d'attention, appliquer softmax pour obtenir des poids d'attention, et enfin combiner ces poids avec les intégrations d'entrée pour générer des représentations contextuellement informées. À la base, l’auto-attention permet au modèle de se concentrer davantage sur les mots pertinents tout en atténuant les moins importants, facilitant ainsi un apprentissage efficace des dépendances contextuelles au sein des données d’entrée. Ce mécanisme est essentiel pour capturer les dépendances à longue portée et les nuances contextuelles, permettant aux modèles de transformateur de générer de longues séquences de texte.
MIT © Shrirang Mahajan
N'hésitez pas à soumettre des pull request, à créer des problèmes ou à faire passer le message !
Soutenez-moi en mettant simplement en vedette ce référentiel !


