marqo ecommerce embeddings
1.0.0
Dans ce travail, nous introduisons deux modèles d'intégration de pointe pour les produits de commerce électronique : Marqo-Ecommerce-B et Marqo-Ecommerce-L.
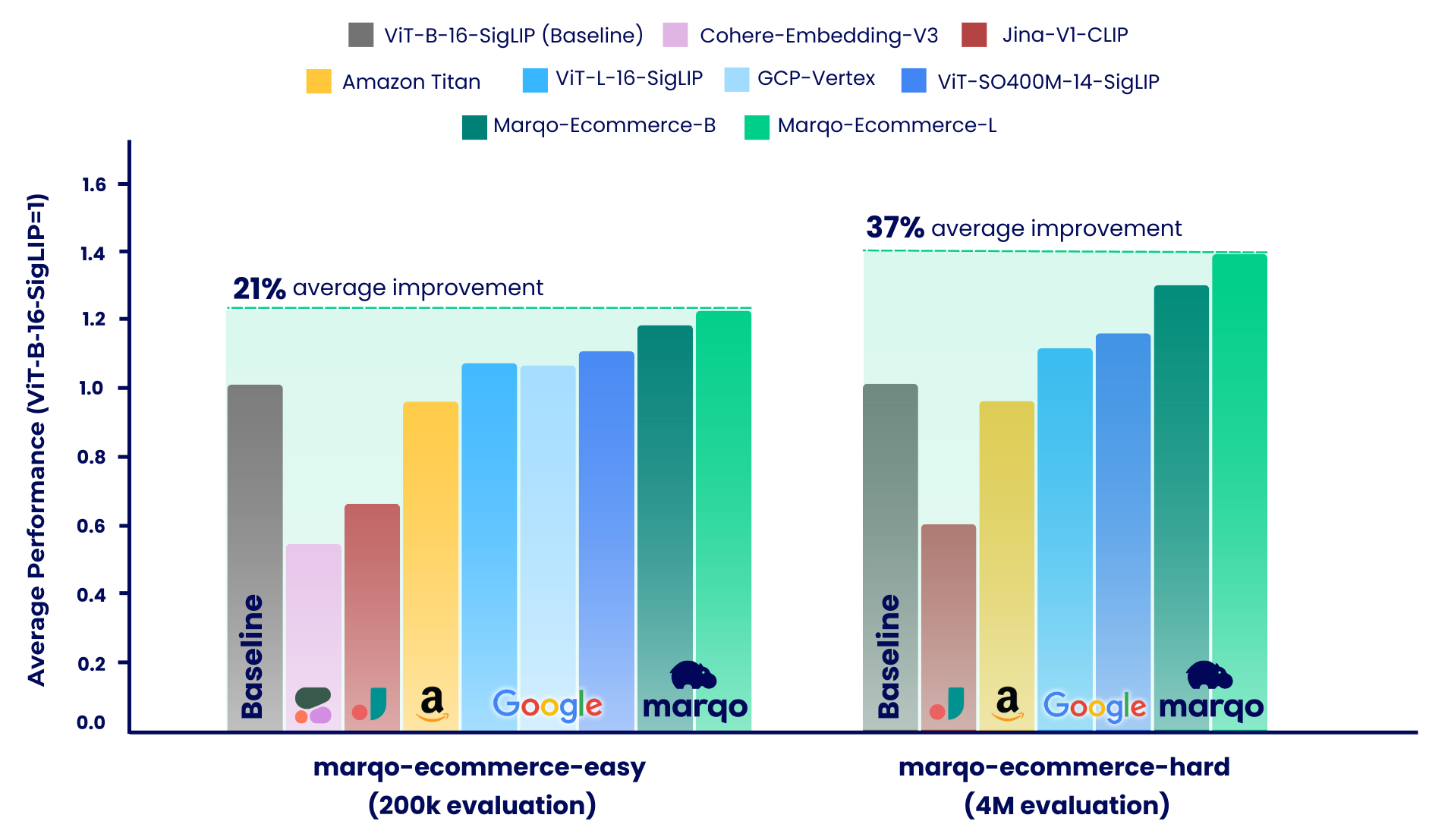
Les résultats de l'analyse comparative montrent que les modèles Marqo-Ecommerce ont systématiquement surpassé tous les autres modèles sur divers critères. Plus précisément, marqo-ecommerce-L a réalisé une amélioration moyenne de 17,6 % du MRR et de 20,5 % du nDCG@10 par rapport au meilleur modèle open source actuel, ViT-SO400M-14-SigLIP sur les trois tâches du marqo-ecommerce-hard ensemble de données marqo-ecommerce-hard . Par rapport au meilleur modèle privé, Amazon-Titan-Multimodal , nous avons constaté une amélioration moyenne de 38,9 % du MRR et de 45,1 % du nDCG@10 dans les trois tâches, et de 35,9 % du rappel dans les tâches Text-to-Image dans l'ensemble de données marqo-ecommerce-hard .
D’autres résultats d’analyse comparative peuvent être trouvés ci-dessous.
Contenu publié :
| Modèle d'intégration | #Params (m) | Dimension | ÉtreindreVisage | Télécharger .pt | Inférence de texte par lot unique (A10g) | Inférence d'image par lot unique (A10g) |
|---|---|---|---|---|---|---|
| Marqo-Ecommerce-B | 203 | 768 | Marqo/marqo-ecommerce-embeddings-B | lien | 5,1 ms | 5,7 ms |
| Marqo-Ecommerce-L | 652 | 1024 | Marqo/marqo-ecommerce-embeddings-L | lien | 10,3 ms | 11,0 ms |
Pour charger les modèles dans OpenCLIP, voir ci-dessous. Les modèles sont hébergés sur Hugging Face et chargés via OpenCLIP. Vous pouvez également trouver ce code dans run_models.py .
pip install open_clip_torch
from PIL import Image
import open_clip
import requests
import torch
# Specify model from Hugging Face Hub
model_name = 'hf-hub:Marqo/marqo-ecommerce-embeddings-L'
model , preprocess_train , preprocess_val = open_clip . create_model_and_transforms ( model_name )
tokenizer = open_clip . get_tokenizer ( model_name )
# Preprocess the image and tokenize text inputs
# Load an example image from a URL
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw )
image = preprocess_val ( img ). unsqueeze ( 0 )
text = tokenizer ([ "dining chairs" , "a laptop" , "toothbrushes" ])
# Perform inference
with torch . no_grad (), torch . cuda . amp . autocast ():
image_features = model . encode_image ( image , normalize = True )
text_features = model . encode_text ( text , normalize = True )
# Calculate similarity probabilities
text_probs = ( 100.0 * image_features @ text_features . T ). softmax ( dim = - 1 )
# Display the label probabilities
print ( "Label probs:" , text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]Pour charger les modèles dans Transformers, voir ci-dessous. Les modèles sont hébergés sur Hugging Face et chargés à l'aide de Transformers.
from transformers import AutoModel , AutoProcessor
import torch
from PIL import Image
import requests
model_name = 'Marqo/marqo-ecommerce-embeddings-L'
# model_name = 'Marqo/marqo-ecommerce-embeddings-B'
model = AutoModel . from_pretrained ( model_name , trust_remote_code = True )
processor = AutoProcessor . from_pretrained ( model_name , trust_remote_code = True )
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw ). convert ( "RGB" )
image = [ img ]
text = [ "dining chairs" , "a laptop" , "toothbrushes" ]
processed = processor ( text = text , images = image , padding = 'max_length' , return_tensors = "pt" )
processor . image_processor . do_rescale = False
with torch . no_grad ():
image_features = model . get_image_features ( processed [ 'pixel_values' ], normalize = True )
text_features = model . get_text_features ( processed [ 'input_ids' ], normalize = True )
text_probs = ( 100 * image_features @ text_features . T ). softmax ( dim = - 1 )
print ( text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12] L'apprentissage contrastif généralisé (GCL) est utilisé pour l'évaluation. Le code suivant peut également être trouvé dans scripts .
git clone https://github.com/marqo-ai/GCL
Installez les packages requis par GCL.
1. Récupération GoogleShopping-Text2Image.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-title2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
2. Récupération d'images GoogleShopping-Category2.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-cat2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['query']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
3. Récupération d'images AmazonProducts-Category2.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/ap-title2image
mkdir -p $outdir
hfdataset=Marqo/amazon-products-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
Notre processus d'analyse comparative a été divisé en deux régimes distincts, chacun utilisant différents ensembles de données de listes de produits de commerce électronique : marqo-ecommerce-hard et marqo-ecommerce-easy. Les deux ensembles de données contenaient des images et du texte de produits et ne différaient que par leur taille. L'ensemble de données « facile » est environ 10 à 30 fois plus petit (200 000 produits contre 4 millions) et conçu pour prendre en charge des modèles à débit limité, en particulier Cohere-Embeddings-v3 et GCP-Vertex (avec des limites de 0,66 rps et 2 rps respectivement). L'ensemble de données « hard » représente le véritable défi, car il contient quatre millions de listes de produits de commerce électronique et est plus représentatif des scénarios de recherche de commerce électronique réels.
Dans ces deux scénarios, les modèles ont été comparés à trois tâches différentes :
Marqo-Ecommerce-Hard examine l'évaluation complète menée à l'aide de l'ensemble complet de 4 millions de données, soulignant les performances robustes de nos modèles dans un contexte réel.
Récupération d'images GoogleShopping-Text2.
| Modèle d'intégration | carte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,682 | 0,878 | 0,683 | 0,726 |
| Marqo-Ecommerce-B | 0,623 | 0,832 | 0,624 | 0,668 |
| ViT-SO400M-14-SigLip | 0,573 | 0,763 | 0,574 | 0,613 |
| ViT-L-16-SigLip | 0,540 | 0,722 | 0,540 | 0,577 |
| ViT-B-16-SigLip | 0,476 | 0,660 | 0,477 | 0,513 |
| Amazon-Titan-MultiModal | 0,475 | 0,648 | 0,475 | 0,509 |
| Jina-V1-CLIP | 0,285 | 0,402 | 0,285 | 0,306 |
Récupération d'images GoogleShopping-Category2.
| Modèle d'intégration | carte | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,463 | 0,652 | 0,822 | 0,666 |
| Marqo-Ecommerce-B | 0,423 | 0,629 | 0,810 | 0,644 |
| ViT-SO400M-14-SigLip | 0,352 | 0,516 | 0,707 | 0,529 |
| ViT-L-16-SigLip | 0,324 | 0,497 | 0,687 | 0,509 |
| ViT-B-16-SigLip | 0,277 | 0,458 | 0,660 | 0,473 |
| Amazon-Titan-MultiModal | 0,246 | 0,429 | 0,642 | 0,446 |
| Jina-V1-CLIP | 0,123 | 0,275 | 0,504 | 0,294 |
Récupération d'images AmazonProducts-Text2.
| Modèle d'intégration | carte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,658 | 0,854 | 0,663 | 0,703 |
| Marqo-Ecommerce-B | 0,592 | 0,795 | 0,597 | 0,637 |
| ViT-SO400M-14-SigLip | 0,560 | 0,742 | 0,564 | 0,599 |
| ViT-L-16-SigLip | 0,544 | 0,715 | 0,548 | 0,580 |
| ViT-B-16-SigLip | 0,480 | 0,650 | 0,484 | 0,515 |
| Amazon-Titan-MultiModal | 0,456 | 0,627 | 0,457 | 0,491 |
| Jina-V1-CLIP | 0,265 | 0,378 | 0,266 | 0,285 |
Comme mentionné, notre processus d'analyse comparative a été divisé en deux scénarios distincts : marqo-ecommerce-hard et marqo-ecommerce-easy. Cette section couvre ce dernier qui présente un corpus 10 à 30 fois plus petit et a été conçu pour s'adapter aux modèles à débit limité. Nous examinerons l'évaluation complète menée à l'aide de l'intégralité des 200 000 produits dans les deux ensembles de données. En plus des modèles déjà évalués ci-dessus, ces tests incluent également Cohere-embedding-v3 et GCP-Vertex.
Récupération d'images GoogleShopping-Text2.
| Modèle d'intégration | carte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,879 | 0,971 | 0,879 | 0,901 |
| Marqo-Ecommerce-B | 0,842 | 0,961 | 0,842 | 0,871 |
| ViT-SO400M-14-SigLip | 0,792 | 0,935 | 0,792 | 0,825 |
| GCP-Sommet | 0,740 | 0,910 | 0,740 | 0,779 |
| ViT-L-16-SigLip | 0,754 | 0,907 | 0,754 | 0,789 |
| ViT-B-16-SigLip | 0,701 | 0,870 | 0,701 | 0,739 |
| Amazon-Titan-MultiModal | 0,694 | 0,868 | 0,693 | 0,733 |
| Jina-V1-CLIP | 0,480 | 0,638 | 0,480 | 0,511 |
| Cohere-intégration-v3 | 0,358 | 0,515 | 0,358 | 0,389 |
Récupération d'images GoogleShopping-Category2.
| Modèle d'intégration | carte | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,515 | 0,358 | 0,764 | 0,590 |
| Marqo-Ecommerce-B | 0,479 | 0,336 | 0,744 | 0,558 |
| ViT-SO400M-14-SigLip | 0,423 | 0,302 | 0,644 | 0,487 |
| GCP-Sommet | 0,417 | 0,298 | 0,636 | 0,481 |
| ViT-L-16-SigLip | 0,392 | 0,281 | 0,627 | 0,458 |
| ViT-B-16-SigLip | 0,347 | 0,252 | 0,594 | 0,414 |
| Amazon-Titan-MultiModal | 0,308 | 0,231 | 0,558 | 0,377 |
| Jina-V1-CLIP | 0,175 | 0,122 | 0,369 | 0,229 |
| Cohere-intégration-v3 | 0,136 | 0,110 | 0,315 | 0,178 |
Récupération d'images AmazonProducts-Text2.
| Modèle d'intégration | carte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,92 | 0,978 | 0,928 | 0,940 |
| Marqo-Ecommerce-B | 0,897 | 0,967 | 0,897 | 0,914 |
| ViT-SO400M-14-SigLip | 0,860 | 0,954 | 0,860 | 0,882 |
| ViT-L-16-SigLip | 0,842 | 0,940 | 0,842 | 0,865 |
| GCP-Sommet | 0,808 | 0,933 | 0,808 | 0,837 |
| ViT-B-16-SigLip | 0,797 | 0,917 | 0,797 | 0,825 |
| Amazon-Titan-MultiModal | 0,762 | 0,889 | 0,763 | 0,791 |
| Jina-V1-CLIP | 0,530 | 0,699 | 0,530 | 0,565 |
| Cohere-intégration-v3 | 0,433 | 0,597 | 0,433 | 0,465 |
@software{zhu2024marqoecommembed_2024,
author = {Tianyu Zhu and and Jesse Clark},
month = oct,
title = {{Marqo Ecommerce Embeddings - Foundation Model for Product Embeddings}},
url = {https://github.com/marqo-ai/marqo-ecommerce-embeddings/},
version = {1.0.0},
year = {2024}
}


