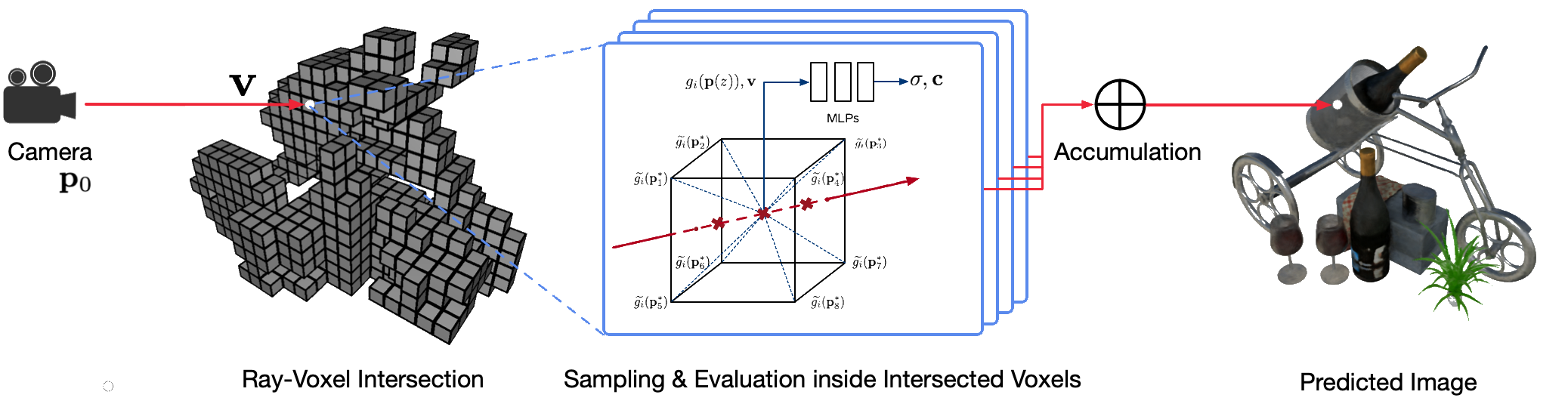
Le rendu photoréaliste à point de vue libre de scènes du monde réel à l'aide de techniques d'infographie classiques est un problème difficile car il nécessite l'étape difficile de capture de modèles détaillés d'apparence et de géométrie. Le rendu neuronal est un domaine émergent qui utilise des réseaux neuronaux profonds pour apprendre implicitement des représentations de scènes encapsulant à la fois la géométrie et l'apparence à partir d'observations 2D avec ou sans géométrie grossière. Cependant, les approches existantes dans ce domaine montrent souvent des rendus flous ou souffrent d'un processus de rendu lent. Nous proposons Neural Sparse Voxel Fields (NSVF), une nouvelle représentation de scène neuronale pour un rendu rapide et de haute qualité en point de vue libre.
Voici le dépôt officiel du journal :
Nous fournissons également notre implémentation non officielle pour :
Ce code est implémenté dans PyTorch à l'aide du framework fairseq.
Le code a été testé sur le système suivant :
Seuls l'apprentissage et le rendu sur GPU sont pris en charge.
Pour installer, clonez d'abord ce dépôt et installez toutes les dépendances :
pip install -r requirements.txtEnsuite, courez
pip install --editable ./Ou si vous souhaitez installer le code localement, exécutez :
python setup.py build_ext --inplaceVous pouvez télécharger les ensembles de données synthétiques et réelles prétraités utilisés dans notre article. Veuillez également citer les articles originaux si vous en utilisez dans votre travail.
| Ensemble de données | Lien de téléchargement | Notes sur la division de l'ensemble de données |
|---|---|---|
| Synthétique-NSVF | télécharger (.zip) | 0_* (formation) 1_* (validation) 2_* (test) |
| Synthétique-NeRF | télécharger (.zip) | 0_* (formation) 1_* (validation) 2_* (test) |
| MélangeMVS | télécharger (.zip) | 0_* (formation) 1_* (test) |
| Réservoirs et Temples | télécharger (.zip) | 0_* (formation) 1_* (test) |
Pour préparer un nouvel ensemble de données d'une seule scène pour la formation et les tests, veuillez suivre la structure des données :
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) où le fichier bbox.txt contient une ligne décrivant le cadre de délimitation initial et la taille du voxel :
x_min y_min z_min x_max y_max z_max initial_voxel_size Notez que les noms de fichiers des images cibles et ceux des fichiers de pose de caméra correspondants ne doivent pas nécessairement être exactement les mêmes. Cependant, l'ordre de ces deux types de fichiers (triés par chaîne) doit correspondre. Les ensembles de données sont divisés avec des indices de vue. Par exemple, " train (0..100) , valid (100..200) et test (200..400) " signifient les 100 premières vues pour la formation, les 100 à 199e vues pour la validation et les 200 à 399e vues pour les tests. .
Étant donné l'ensemble de données d'une seule scène ( {DATASET} ), nous utilisons la commande suivante pour entraîner un modèle NSVF afin de synthétiser de nouvelles vues à 800x800 pixels, avec une taille de lot de 4 images par GPU et 2048 rayons par image. Par défaut, le code détectera automatiquement tous les GPU disponibles.
Dans l'exemple suivant, nous utilisons une architecture prédéfinie nsvf_base avec des arguments spécifiques :
--no-sampling-at-reader , le modèle échantillonne uniquement les pixels dans la région de l'image projetée des voxels clairsemés pour l'entraînement.1/8 (0.125) de la taille du voxel qui est généralement décrite dans le fichier bbox.txt .--use-octree . Il construira un octree de voxels clairsemé pour accélérer l'intersection rayon-voxel, en particulier lorsque le nombre de voxels est supérieur à 10000 .--pruning-every-steps sur 2500 , le modèle effectue un auto-élagage toutes 2500 étapes.--half-voxel-size-at et --reduce-step-size-at sur 5000,25000,75000 , la taille du voxel et la taille du pas sont réduites de moitié à 5k , 25k et 75k , respectivement.Notez que, bien que les paramètres ci-dessus soient utilisés pour la plupart des expériences présentées dans cet article, il est possible d'ajuster ces paramètres pour obtenir une meilleure qualité. Outre les paramètres ci-dessus, d'autres paramètres peuvent également utiliser les paramètres par défaut.
Outre l'architecture nsvf_base , vous pouvez vérifier d'autres architectures ou définir vos propres architectures dans le fichier fairnr/models/nsvf.py .
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log Les points de contrôle sont enregistrés dans {SAVE} . Vous pouvez lancer Tensorboard pour vérifier la progression de l'entraînement :
tensorboard --logdir= ${SAVE} /tensorboard --port=10000Il existe d'autres exemples de scripts de formation pour reproduire les résultats de notre article sous exemples.
Une fois le modèle entraîné, la commande suivante est utilisée pour évaluer la qualité du rendu sur les vues de test en fonction du {MODEL_PATH} .
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' Notez que nous remplaçons raymarching_tolerance par 0.01 pour permettre une résiliation anticipée afin d'accélérer le rendu.
Le rendu à point de vue libre peut être obtenu une fois qu'un modèle est entraîné et qu'une trajectoire de rendu est spécifiée. Par exemple, la commande suivante concerne le rendu avec une trajectoire circulaire (vitesse angulaire 3 degrés/image, 15 images par GPU). Cela génère des images rendues par vue et fusionne les images dans une vidéo .mp4 dans ${SAVE}/output comme suit :

Par défaut, le code peut détecter tous les GPU disponibles.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Notre code prend également en charge le rendu pour des poses de caméra données. Par exemple, la commande suivante permet le rendu avec les poses de caméra définies dans les 200 à 399ème fichiers du dossier ${DATASET}/pose :
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Le code prend également en charge le rendu avec des poses de caméra définies dans un fichier .txt . Veuillez vous référer à cet exemple.
Nous prenons également en charge l'exécution de cubes de marche pour extraire les iso-surfaces sous forme de maillages triangulaires à partir d'un modèle NSVF formé et enregistrées sous {SAVE}/{NAME}.ply .
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 Il est également possible d'exporter les voxels clairsemés appris en définissant --format 'voxel_mesh' . Le fichier de sortie .ply peut être ouvert avec n'importe quelle visionneuse 3D telle que MeshLab.

NSVF est sous licence MIT. La licence s'applique également aux modèles pré-entraînés.
Veuillez citer comme
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

