VideoMambaPro
1.0.0
Implémentation officielle de VideoMambaPro : un pas en avant pour Mamba dans la compréhension de la vidéo 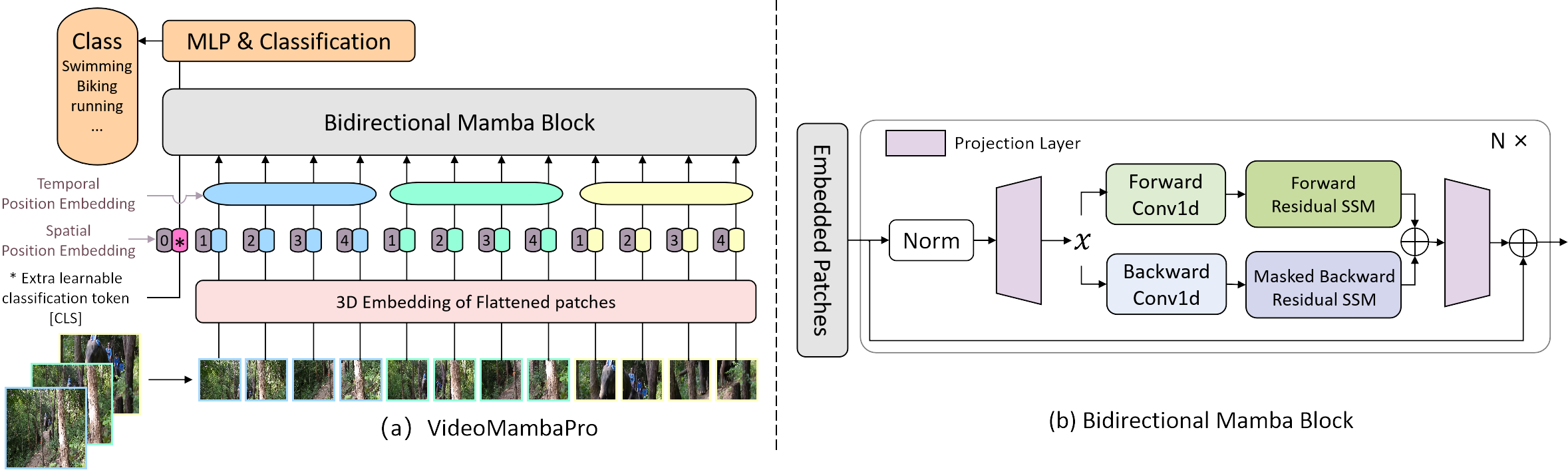
nous étudions les similitudes et les différences entre l'attention personnelle et Mamba du point de vue de ce dernier, et révélons les limites de Mamba dans la tâche de compréhension vidéo. Nous proposons VideoMambaPro qui utilise VideoMamba comme épine dorsale, mais améliore considérablement les performances dans la tâche de compréhension vidéo, réduisant ainsi l'écart avec les transformateurs.
Les packages requis se trouvent dans le fichier requirements.txt et vous pouvez exécuter la commande suivante pour installer l'environnement
conda create -n videomambapro python=3.10
conda activate videomambapro
conda install cudatoolkit==11.8 -c nvidia
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
conda install -c "nvidia/label/cuda-11.8.0" cuda-nvcc
conda install packaging
pip install causal_conv1d==1.4.0 (we recommend to install through .whl file)
pip install mamba-ssm
pip install -r requirements.txt
Nous lisons et traitons de la même manière que VideoMAE, mais avec une convention différente pour le format du fichier de liste de données.
Nous pré-entraînons le modèle sur l'ensemble de données ImageNet-1K, où le modèle charge un fichier de liste de données au format suivant :
frame_folder_path étiquette total_frames
Il existe deux implémentations de notre ensemble de données de réglage fin VideoClsDataset et RawFrameClsDataset , prenant respectivement en charge les données vidéo et les données rawframes. Où SSV2 utilise RawFrameClsDataset par défaut et le reste des ensembles de données utilisent VideoClsDataset .
VideoClsDataset charge un fichier de liste de données au format suivant :
étiquette chemin_vidéo
tandis que RawFrameClsDataset charge un fichier de liste de données au format suivant :
frame_folder_path étiquette total_frames
Par exemple, la liste des données vidéo et la liste des données rawframes sont présentées ci-dessous :
# The path prefix 'your_path' can be specified by `--data_root ${PATH_PREFIX}` in scripts when training or inferencing.
# k400 video data validation list
your_path/k400/jf7RDuUTrsQ.mp4 325
your_path/k400/JTlatknwOrY.mp4 233
your_path/k400/NUG7kwJ-614.mp4 103
your_path/k400/y9r115bgfNk.mp4 320
your_path/k400/ZnIDviwA8CE.mp4 244
...
# ssv2 rawframes data validation list
your_path/SomethingV2/frames/74225 62 140
your_path/SomethingV2/frames/116154 51 127
your_path/SomethingV2/frames/198186 47 173
your_path/SomethingV2/frames/137878 29 99
your_path/SomethingV2/frames/151151 31 166
...
Notre projet est basé sur VideoMamba pour une comparaison équitable. Pour résoudre les limitations 1 et 2 de notre article, nous modifions principalement le pipeline de Mamba en appliquant le masque diagonal pendant le SSM arrière et en appliquant une connexion résiduelle sur le SSM bidirectionnel. La connexion résiduelle de Ab est réalisée dans la fonction selected_scan_ref dans mamba/mamba_ssm/ops/selective_scan_interface.py, et l'option clé est ci-dessous :
x = u[:, :, 0].unsqueeze(-1).expand(-1, -1, dstate)
x = deltaA[:, :, i] * x + deltaB_u[:, :, i]
L'attribution du masque est réalisée en définissant deux fonctions sélectives, à savoir sélective_scan_ref et sélective_scan_ref_sub dans mamba/mamba_ssm/ops/selective_scan_interface.py. Lors du calcul du mamba bidirectionnel, par exemple dans bimamba_inner_ref de mamba/mamba_ssm/ops/selective_scan_interface.py, le code clé est ci-dessous :
y = selective_scan_fn(x, delta, A, B, C, D, z=z, delta_bias=delta_bias, delta_softplus=True)
y_b = selective_scan_ref_sub(x.flip([-1]), delta.flip([-1]), A_b, B.flip([-1]), C.flip([-1]), D, z.flip([-1]), delta_bias, delta_softplus=True)
y = y + y_b.flip([-1])
Nom : https://pan.baidu.com/s/1vJN_XTRct65cDA_0AB259g?pwd=ghqb Nom : ghqb


