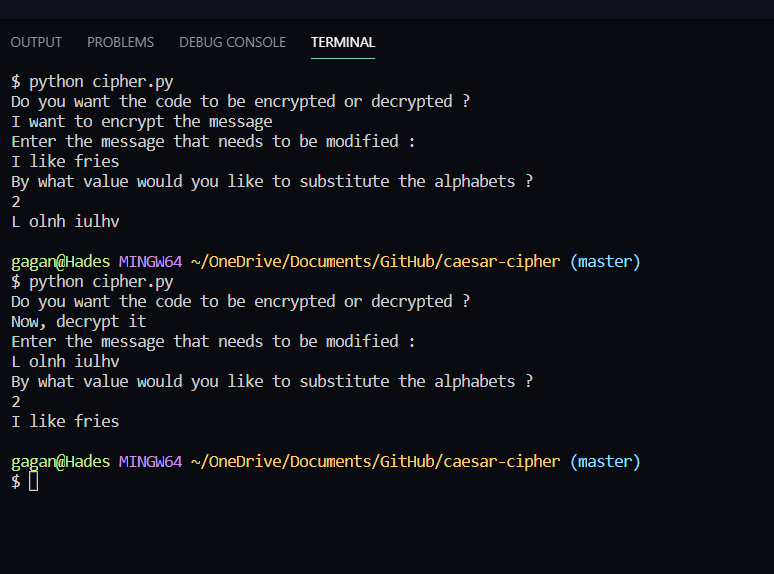
En explorant la cryptographie, j'ai trouvé une vidéo de la Khan Academy qui a éveillé mon intérêt pour les failles du fameux chiffre de César.
Chaque fois que vous écrivez une longue lettre ou un e-mail en anglais, vous laissez involontairement une empreinte digitale derrière vous ; si vous scannez un message que vous avez écrit et comptez la fréquence de chaque lettre, vous découvrirez un modèle assez cohérent. « e » sera probablement la lettre la plus récurrente dans tout le message. J'ai pris une fable aléatoire sur Internet pour tester cela et le résultat que j'ai obtenu était ce que l'on pouvait en attendre. « e » était en effet la lettre la plus populaire. Ce fait est vrai pour tout message suffisamment long.
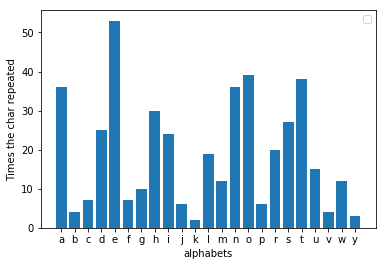
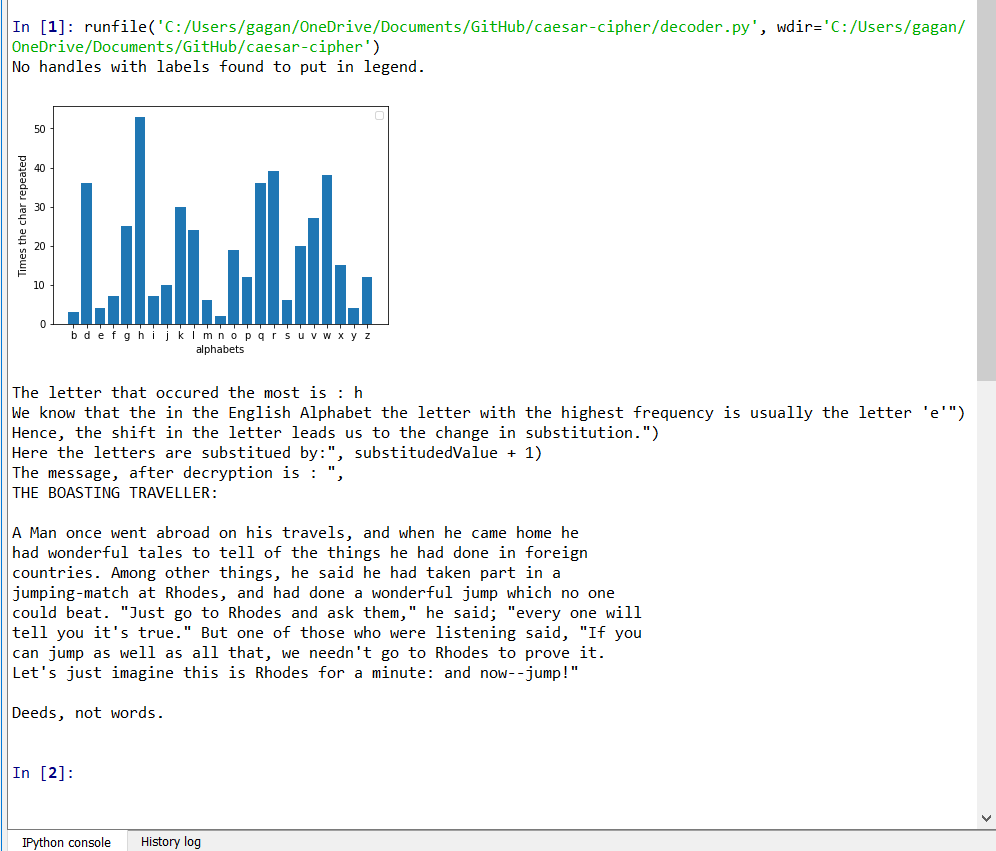
Le défaut découvert par Al-kindi était que, lorsque vous analysez la fréquence du message crypté, une lettre différente revient désormais le plus souvent. Si vous vérifiez dans quelle mesure la lettre est décalée de trois, vous pourrez trouver la valeur par laquelle le message est remplacé. Par exemple, si « h » est la lettre la plus populaire dans le message chiffré, le décalage est probablement de trois. Maintenant, en inversant le décalage, nous pourrions facilement obtenir le message original. Dans le decoder.py lorsque vous lui fournissez un fichier crypté, il décrypte le message et l'imprime. J'ai chiffré la même fable en décalant les alphabets de trois lettres et il s'avère que le « h » est effectivement la lettre la plus populaire ici.
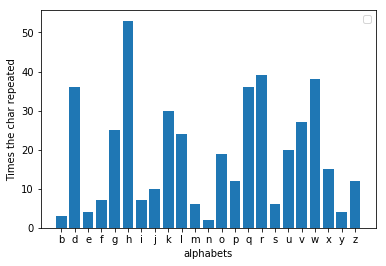
Pour reproduire les résultats de mon chiffre et l'explorer avec d'autres messages, en plus de python, vous devez avoir installé matplotlib.
pip install matplotlibRappel : Le décodeur fonctionne sur le principe de la linguistique et des statistiques, plus le message est long, plus le résultat est précis.
Gagan Devagiri © MIT


