self instruct
1.0.0
Ce référentiel contient du code et des données pour le document Self-Instruct, une méthode permettant d'aligner des modèles de langage pré-entraînés avec des instructions.
Self-Instruct est un cadre qui aide les modèles de langage à améliorer leur capacité à suivre les instructions en langage naturel. Pour ce faire, il utilise les propres générations du modèle pour créer une vaste collection de données pédagogiques. Avec Self-Instruct, il est possible d'améliorer les capacités de suivi des instructions des modèles de langage sans recourir à des annotations manuelles approfondies.
Ces dernières années, on a constaté un intérêt croissant pour la création de modèles capables de suivre des instructions en langage naturel pour effectuer un large éventail de tâches. Ces modèles, appelés modèles de langage « adaptés aux instructions », ont démontré leur capacité à se généraliser à de nouvelles tâches. Cependant, leurs performances dépendent fortement de la qualité et de la quantité des données d’instructions écrites par des humains utilisées pour les former, dont la diversité et la créativité peuvent être limitées. Pour surmonter ces limites, il est important de développer des approches alternatives pour superviser les modèles adaptés aux instructions et améliorer leurs capacités à suivre les instructions.
Le processus d'auto-instruction est un algorithme d'amorçage itératif qui commence par un ensemble d'instructions écrites manuellement et les utilise pour inciter le modèle de langage à générer de nouvelles instructions et les instances d'entrée-sortie correspondantes. Ces générations sont ensuite filtrées pour supprimer celles de mauvaise qualité ou similaires, et les données résultantes sont rajoutées au pool de tâches. Ce processus peut être répété plusieurs fois, ce qui donne lieu à une vaste collection de données pédagogiques qui peuvent être utilisées pour affiner le modèle linguistique afin de suivre les instructions plus efficacement.
Voici un aperçu de l’auto-instruction :
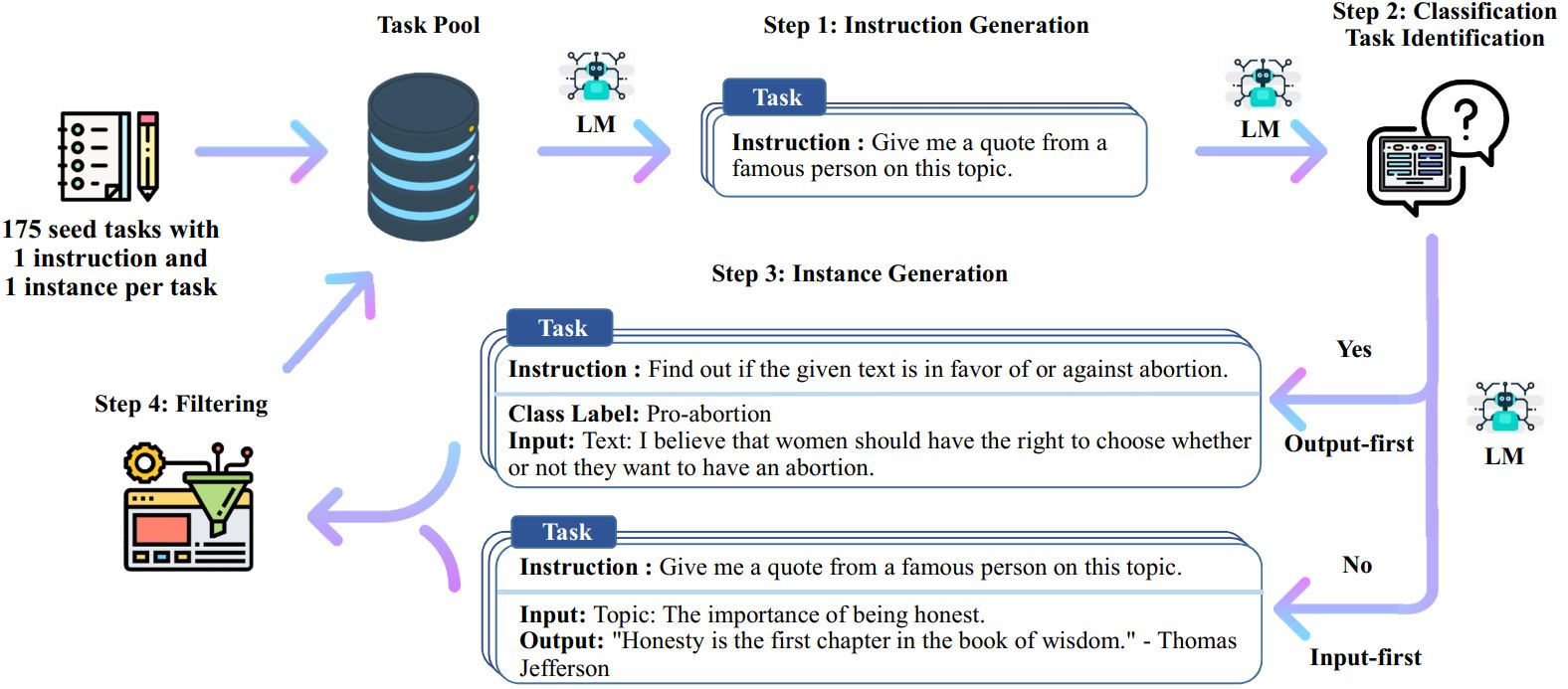
* Ce travail est toujours en cours. Nous pouvons mettre à jour le code et les données à mesure que nous progressons. Soyez prudent concernant le contrôle de version.
Nous publions un ensemble de données contenant 52 000 instructions, associées à 82 000 entrées et sorties d'instance. Ces données d'instruction peuvent être utilisées pour effectuer le réglage des instructions pour les modèles de langage et permettre au modèle de langage de mieux suivre les instructions. L'intégralité des données générées par le modèle est accessible dans data/gpt3-generations/batch_221203/all_instances_82K.jsonl . Ces données (+ les 175 tâches de départ) reformatées au format de réglage fin GPT3 propre (invite + achèvement) sont placées dans data/finetuning/self_instruct_221203 . Vous pouvez utiliser le script dans ./scripts/finetune_gpt3.sh pour affiner GPT3 sur ces données.
Remarque : Ces données sont générées par un modèle de langage (GPT3) et contiennent forcément quelques erreurs ou biais. Nous avons analysé la qualité des données sur 200 instructions aléatoires dans notre article et avons constaté que 46 % des points de données peuvent présenter des problèmes. Nous encourageons les utilisateurs à utiliser ces données avec prudence et proposons de nouvelles méthodes pour filtrer ou améliorer les imperfections.
Nous publions également un nouvel ensemble de 252 tâches écrites par des experts et leurs instructions motivées par des applications orientées utilisateur (plutôt que des tâches PNL bien étudiées). Ces données sont utilisées dans la section d'évaluation humaine du document d'auto-instruction. Veuillez vous référer au fichier README d'évaluation humaine pour plus de détails.
Pour générer des données d'auto-instruction à l'aide de vos propres tâches de départ ou d'autres modèles, nous open source nos scripts pour l'ensemble du pipeline ici. Notre code actuel est testé uniquement sur le modèle GPT3 accessible via l'API OpenAI.
Voici les scripts pour générer les données :
# 1. Générez des instructions à partir des tâches de départ./scripts/generate_instructions.sh# 2. Identifiez si l'instruction représente ou non une tâche de classification./scripts/is_clf_or_not.sh# 3. Générez des instances pour chaque instruction./scripts/generate_instances. sh# 4. Filtrage, traitement et reformatage./scripts/prepare_for_finetuning.sh
Si vous utilisez le framework ou les données Self-Instruct, n'hésitez pas à nous citer.
@misc{selfinstruct, title={Auto-instruction : aligner le modèle de langage avec les instructions auto-générées}, author={Wang, Yizhong et Kordi, Yeganeh et Mishra, Swaroop et Liu, Alisa et Smith, Noah A. et Khashabi, Daniel et Hajishirzi, Hannaneh}, journal={préimpression arXiv arXiv:2212.10560}, année={2022}} 

