bertsearch
1.0.0
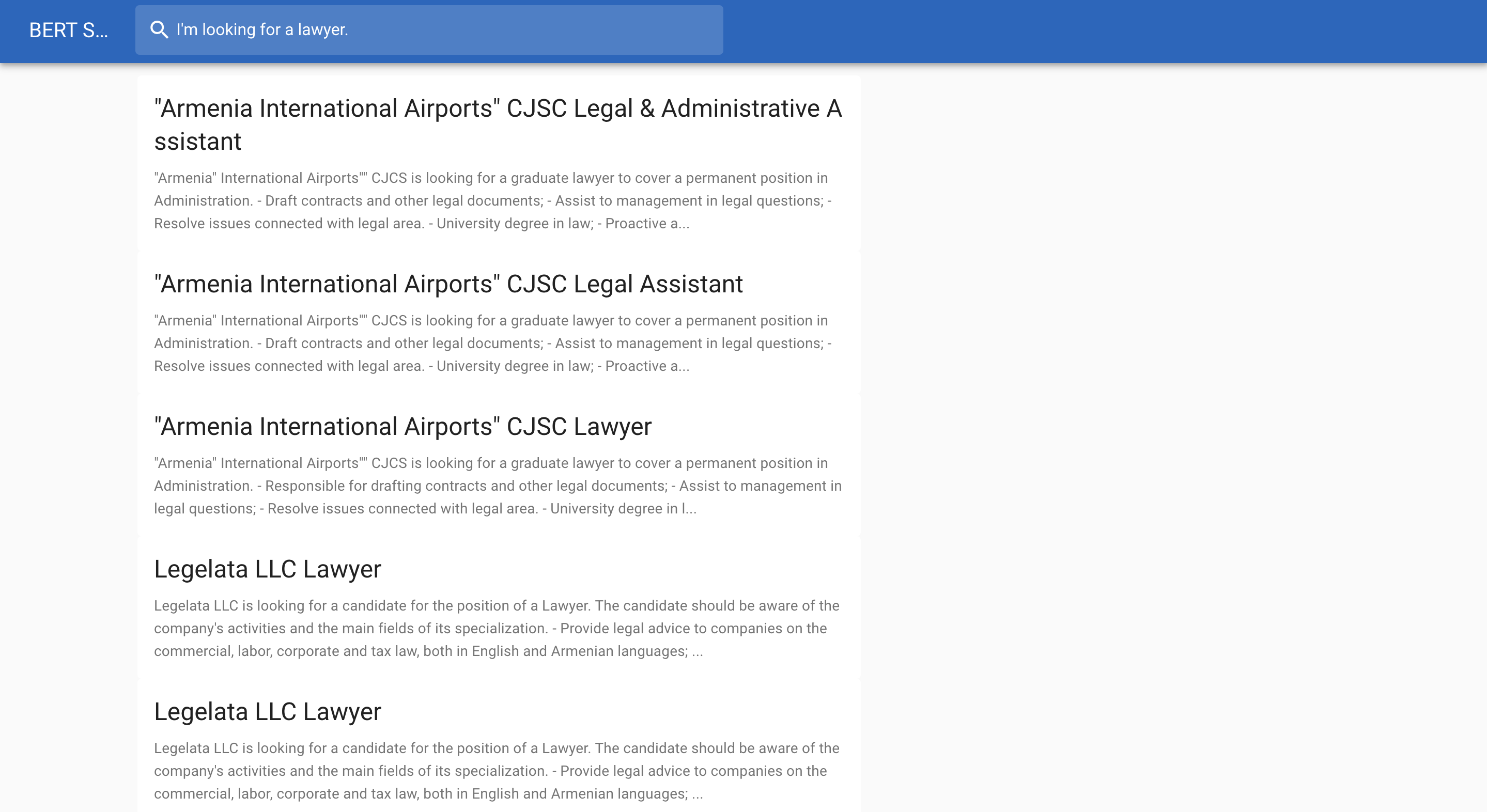
Vous trouverez ci-dessous un exemple de recherche d'emploi :
| Base BERT, sans boîtier | 12 couches, 768 cachées, 12 têtes, 110 millions de paramètres |
| BERT-Large, sans boîtier | 24 couches, 1024 cachées, 16 têtes, 340 millions de paramètres |
| Base BERT, en boîtier | 12 couches, 768 cachées, 12 têtes, 110 millions de paramètres |
| BERT-Large, en boîtier | 24 couches, 1024 cachées, 16 têtes, 340 millions de paramètres |
| BERT-Base, boîtier multilingue (nouveau) | 104 langues, 12 couches, 768 cachées, 12 têtes, 110 millions de paramètres |
| BERT-Base, boîtier multilingue (ancien) | 102 langues, 12 couches, 768 cachées, 12 têtes, 110 millions de paramètres |
| Base BERT, chinois | Chinois simplifié et traditionnel, 12 couches, 768 cachés, 12 têtes, 110 millions de paramètres |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipVous devez définir un modèle BERT pré-entraîné et le nom de l'index d'Elasticsearch comme variables d'environnement :
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up ATTENTION : si possible, attribuez une mémoire élevée (plus de 8GB ) à la configuration de la mémoire de Docker car le conteneur BERT a besoin de mémoire élevée.
Vous pouvez utiliser l'API de création d'index pour ajouter un nouvel index à un cluster Elasticsearch. Lors de la création d'un index, vous pouvez spécifier les éléments suivants :
Par exemple, si vous souhaitez créer un index jobsearch avec les champs title , text et text_vector , vous pouvez créer l'index à l'aide de la commande suivante :
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} ATTENTION : La valeur dims de text_vector doit correspondre aux dims d'un modèle BERT pré-entraîné.
Une fois que vous avez créé un index, vous êtes prêt à indexer un document. Le but ici est de convertir votre document en vecteur à l'aide de BERT. Le vecteur résultant est stocké dans le champ text_vector . Convertissons vos données en un document JSON :
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "Après avoir terminé le script, vous pouvez obtenir un document JSON comme suit :
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...Après avoir converti vos données en JSON, vous pouvez ajouter un document JSON à l'index spécifié et le rendre consultable.
$ python example/index_documents.pyAccédez à http://127.0.0.1:5000.


