Ce code a été construit sur un modèle d'apprentissage profond Image to BEV préexistant, basé sur l'article Translating Images Into Maps. Ce code a été écrit en utilisant python 3.7. et a été formé sur l'ensemble de données nuScenes. Veuillez vous référer au fichier ReadMe du référentiel pour connaître les dépendances et les ensembles de données à installer.
La première étape consiste à créer un dossier nommé « translating-images-into-maps-main » et à y télécharger tous les fichiers. Ensuite, en raison de la grande taille du fichier, les derniers points de contrôle de notre formation et le mini ensemble de données nuScenes utilisé pour la validation peuvent être téléchargés à partir de ce Google Drive. Ces dossiers doivent être ajoutés directement dans le répertoire "translating-images-into-maps-main".
Vous trouverez ci-dessous la liste des bibliothèques requises pour ce dépôt :
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Pour utiliser les fonctions de ce référentiel, les arguments de ligne de commande suivants peuvent devoir être modifiés :
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
Quant à l'entraînement du modèle, ces arguments de ligne de commande peuvent être modifiés :
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Les ensembles de données NuScenes Mini et Full peuvent être trouvés aux emplacements suivants :
NuScene Mini :
NuScenes Full US :
Comme les jeux de données NuScene mini et complet n'ont pas le même format d'entrée d'image (lmdb ou png), certaines modifications doivent être appliquées au code pour utiliser l'un ou l'autre :
mini par false pour utiliser le mini ensemble de données ainsi que les chemins et divisions args dans les fichiers train.py , validation.py et inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Les points de contrôle pré-entraînés peuvent être trouvés ici :
Les points de contrôle doivent être conservés dans /pretrained_models/27_04_23_11_08 du répertoire racine de ce référentiel. Si vous souhaitez les charger depuis un autre répertoire, veuillez modifier les arguments suivants :
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Pour vous entraîner sur scitas, vous devez lancer le script suivant depuis le répertoire racine :
sbatch job.script.sh
Pour s'entraîner localement sur le processeur :
python3 train.py
Assurez-vous d'adapter le script avec vos arguments de ligne de commande.
Pour valider les performances d'un modèle sur scitas :
sbatch job.validate.sh
Pour s'entraîner localement sur le processeur :
python3 validate.py
Assurez-vous d'adapter le script avec vos arguments de ligne de commande.
A déduire sur une vidéo sur scitas :
sbatch job.evaluate.sh
Pour s'entraîner localement sur le processeur :
python3 inference.py
Assurez-vous d'adapter le script avec vos arguments de ligne de commande, notamment :
--batch-size // 1 for the test videos
--video-name
--video-root
Ce projet a été réalisé dans le cadre du cours Deep Learning for Autonomous Vehicles CIVIL-459, enseigné par le professeur Alexandre Alahi à l'EPFL. Nous étions encadrés par le doctorant Yuejiang Liu. L'objectif principal du projet du cours est de développer un modèle d'apprentissage profond pouvant être utilisé à bord d'un système de pilote automatique Tesla. Quant à notre groupe, nous avons étudié la transformation des images de caméra monoculaire en vue à vol d'oiseau. Cela peut être fait en utilisant la segmentation sémantique pour classer des éléments tels que les voitures, les trottoirs, les piétons et l'horizon.
Au cours de nos recherches sur les images monoculaires vers les modèles d'apprentissage profond BEV, nous avons remarqué que les informations concernant les piétons étaient perdues lors de la segmentation, entraînant une mauvaise classification. Comme le montre l'image ci-dessous, une fois évalué, le modèle que nous avons sélectionné atteint une moyenne de 25,7 % IoU (Intersection over Union) sur 14 classes d'objets sur l'ensemble de données nuScenes. La précision des prévisions pour les véhicules roulants est bonne (74,5 %), plutôt mauvaise pour les vélos, les barrières et les remorques. Toutefois, la précision des prévisions pour les piétons (9,5 %) est bien trop faible. Une précision aussi faible pourrait provoquer des accidents si quelqu'un traversait la route sans être sur le passage à niveau.

Plus d’informations sur nos recherches peuvent être trouvées sur le Drive.
Comme la mauvaise détection des piétons semblait être le problème le plus immédiat avec le modèle entraîné actuel, nous avons cherché à améliorer la précision en examinant des fonctions de perte mieux adaptées et en entraînant le nouveau modèle sur l'ensemble de données nuScenes.
Le modèle sur lequel nous avons construit a été formé à l'aide d'un
Un autre problème avec
Le
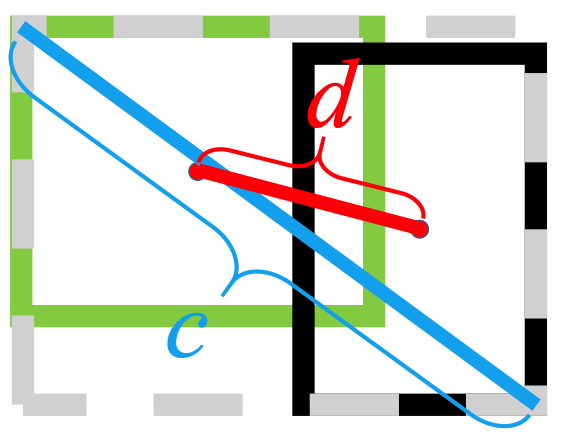
Il utilise la norme L2 pour minimiser la distance entre les cases prédites et cibles, et converge beaucoup plus rapidement que

Étirement horizontal

Étirement vertical
De plus, la perte DIoU introduit un terme de régularisation qui encourage une convergence en douceur.
Comme on peut le voir sur l'image suivante, le
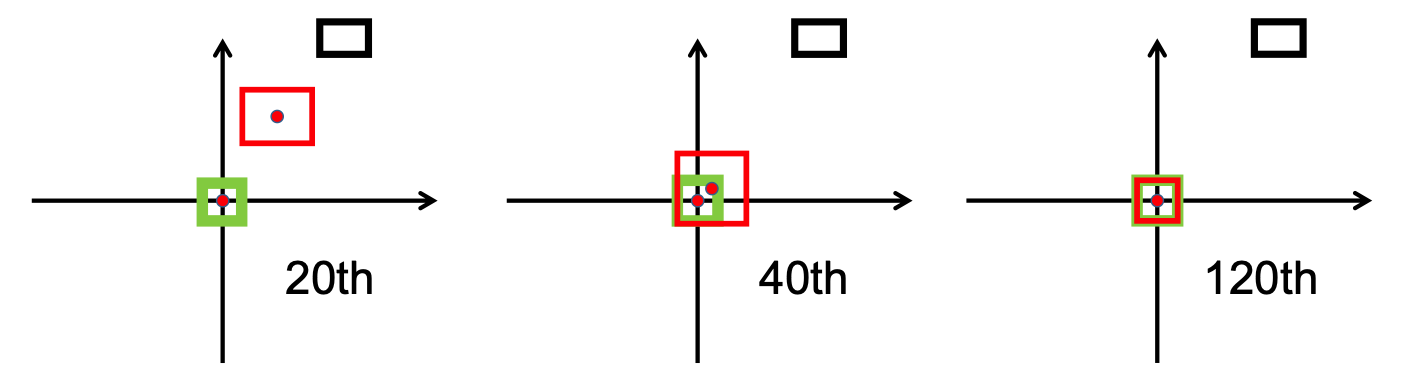
Après la phase de recherche, nous avons mis en œuvre le bbox_overlaps_diou du fichier /src/utils.py , en utilisant le
Cette fonction est ensuite utilisée pour calculer multi-échelles compute_multiscale_iou du même fichier. Pour chaque classe, le iou ) est calculé sur la taille du lot. La sortie de la fonction est un dictionnaire iou_dict contenant le multiscale
Nous avons ensuite utilisé ces valeurs dans train.py , où le val-interval . Ces valeurs ont également été utilisées dans validation.py où elles ont été utilisées pour afficher les pertes et
Nous avons entraîné le modèle sur l'ensemble de données NuScenes en commençant par le checkpoint-008.pth.gz , une fois avec le
Une autre contribution est le nouveau format de visualisation permettant de mieux distinguer les classes avec toutes les étiquettes et valeurs IoU correspondantes. Cela a été implémenté dans le fichier visualization.py .
Enfin, nous avons travaillé sur la mise en œuvre d'un mode qui prendrait des vidéos .mp4 en entrée et les décomposerait en images individuelles. Ceux-ci seraient ensuite évalués par le modèle et nous pourrions visualiser le résultat de la segmentation dans le fichier inference.py .
Pour avoir une première idée de la stratégie d'entraînement de ce modèle, nous avons d'abord décidé de l'entraîner sur les mini jeux de données NuScenes. À partir de checkpoint-008.pth.gz , nous avons pu entraîner deux modèles différents dans la métrique IoU utilisée (IoU pour l'un et DIoU pour l'autre). Les résultats obtenus sur un mini lot NuScenes après 10 époques d'entraînement sont présentés dans le tableau ci-dessous.

Après avoir examiné ces résultats, nous avons observé que la classe des piétons, sur laquelle nous avons fondé notre hypothèse, ne présentait aucun résultat concluant. Nous avons donc conclu que le mini-ensemble de données n'était pas suffisant pour nos besoins et avons décidé de déplacer notre formation vers l'ensemble de données complet sur Scitas.
Après avoir entraîné nos nouveaux modèles (avec DIoU ou IoU) à partir de checkpoint-008.pth.gz pendant 8 nouvelles époques, nous avons observé des résultats prometteurs. Dans le but de comparer les performances de ces modèles nouvellement formés, nous avons effectué une étape de validation sur le mini jeu de données. Une visualisation du résultat pour une image de cet ensemble de données est fournie ci-dessous.
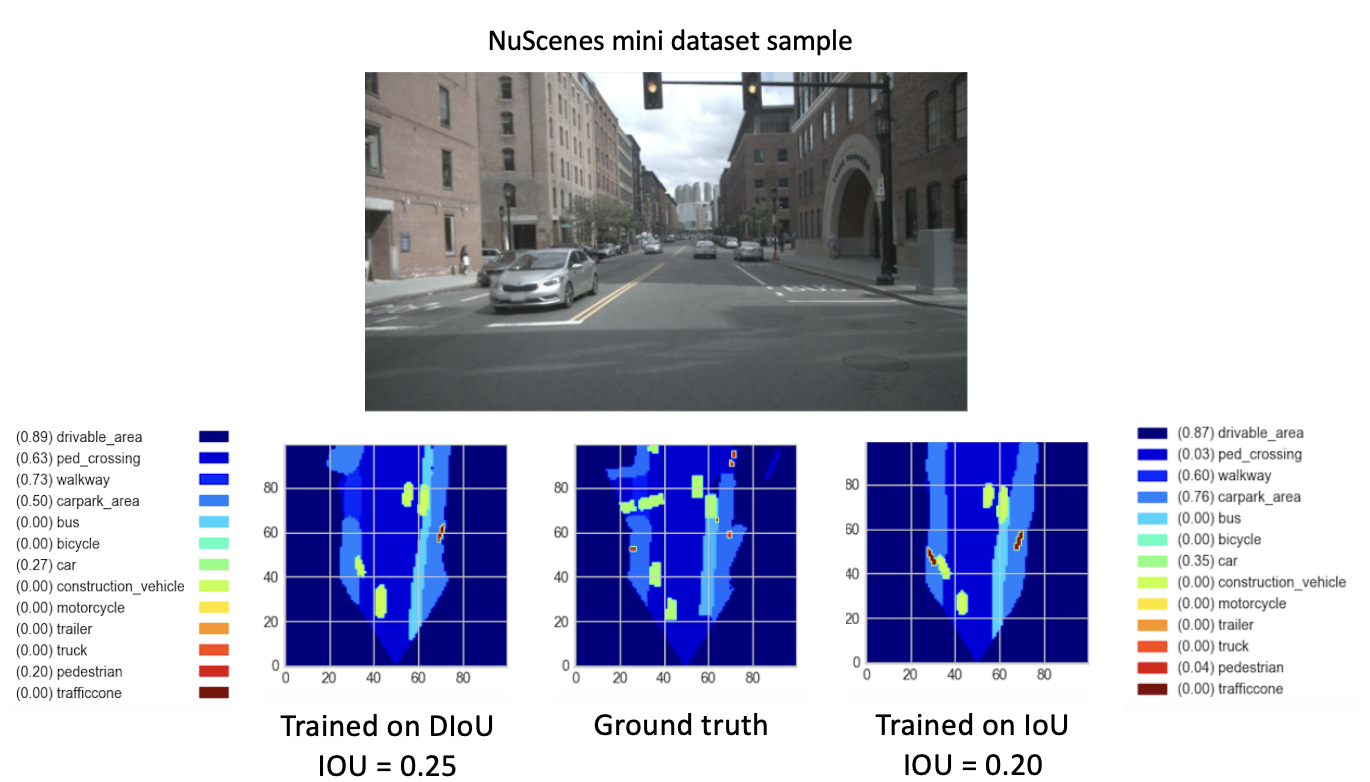
Ici, le

Ces résultats montrent enfin une meilleure performance du
Maintenant que nous disposons d'un modèle entraîné, nous pouvons l'utiliser pour prédire le BEV à l'aide de n'importe quelle image ou vidéo d'entrée. Alors que notre ambition était d'implémenter notre méthode dans la démo finale du cours, les cartes vues à vol d'oiseau qui en découlaient n'étaient malheureusement pas suffisamment performantes. La figure ci-dessous montre le résultat de l'inférence sur l'une des vidéos de test fournies (voir vidéos de test).

Nous pensons que ce manque de performance pour l'inférence est dû aux paramètres suivants :
Bien que le passage de
Une option consiste à mettre en œuvre
Le
De plus, selon les recherches effectuées dans cet article [2], l'erreur de régression pour CIoU se dégrade plus rapidement que les autres et convergera vers
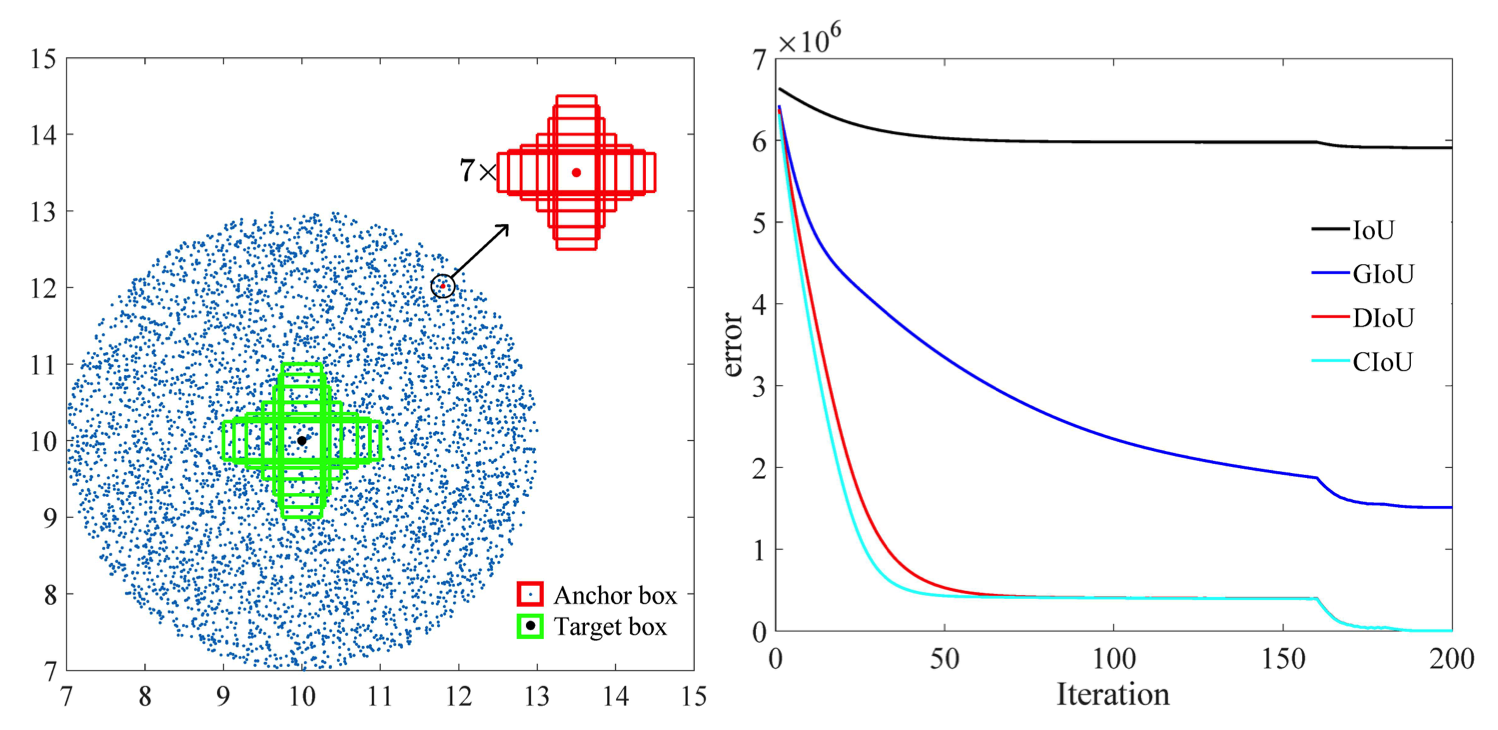
Une autre option consiste à s’entraîner sur des ensembles de données riches en environnements fréquentés pour avoir une meilleure représentation des piétons et des vélos.
Enfin, pour véritablement valider notre hypothèse, une validation sur l'ensemble de données NuScenes pourrait être effectuée et les IoU piétonnes des deux modèles pourraient être comparées.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020). Perte d'IoU à distance : apprentissage plus rapide et meilleur pour la régression du cadre de délimitation https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021). Amélioration des facteurs géométriques dans l'apprentissage et l'inférence de modèles pour la détection d'objets et la segmentation d'instances https://arxiv.org/pdf/2005.03572.pdf


