tiny cuda nn
Version 1.6
Il s'agit d'un petit framework autonome pour la formation et l'interrogation des réseaux de neurones. Plus particulièrement, il contient un perceptron multicouche « entièrement fusionné » ultra-rapide (document technique), un codage de hachage multirésolution polyvalent (document technique), ainsi que la prise en charge de divers autres codages d'entrée, pertes et optimiseurs.
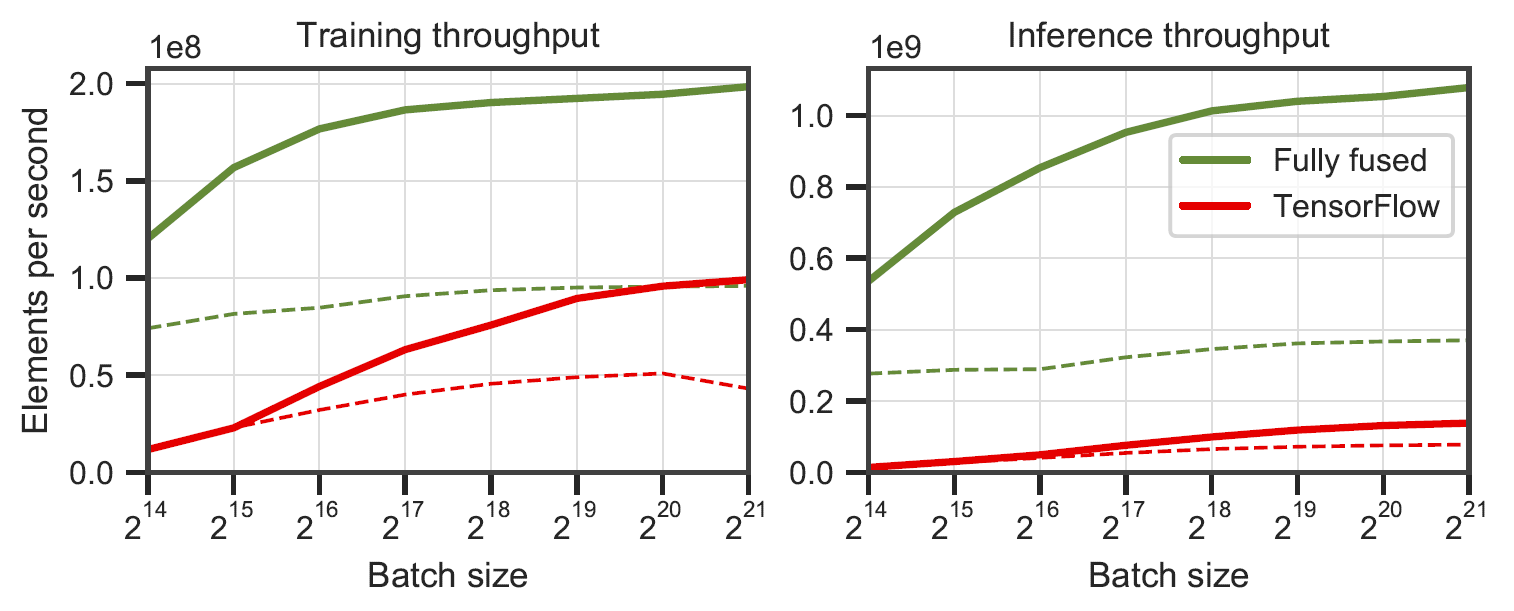 Réseaux entièrement fusionnés par rapport à TensorFlow v2.5.0 avec XLA. Mesuré sur des perceptrons multicouches de 64 (ligne continue) et 128 (ligne pointillée) de neurones sur un RTX 3090. Généré par
Réseaux entièrement fusionnés par rapport à TensorFlow v2.5.0 avec XLA. Mesuré sur des perceptrons multicouches de 64 (ligne continue) et 128 (ligne pointillée) de neurones sur un RTX 3090. Généré par benchmarks/bench_ours.cu et benchmarks/bench_tensorflow.py à l'aide data/config_oneblob.json .
Les petits réseaux de neurones CUDA ont une simple API C++/CUDA :
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Nous fournissons un exemple d'application dans laquelle une fonction d'image (x, y) -> (R, G, B) est apprise. Il peut être exécuté via
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonproduire une image toutes les deux étapes de formation. Chaque 1 000 étapes devrait prendre un peu plus d'une seconde avec la configuration par défaut sur un RTX 4090.
| 10 étapes | 100 étapes | 1000 pas | Image de référence |
|---|---|---|---|
 |  |  |  |
n_neurons ou utiliser CutlassMLP (meilleure compatibilité mais plus lente).Si vous utilisez Linux, installez les packages suivants
sudo apt-get install build-essential git Nous vous recommandons également d'installer CUDA dans /usr/local/ et d'ajouter l'installation CUDA à votre PATH. Par exemple, si vous disposez de CUDA 11.4, ajoutez ce qui suit à votre ~/.bashrc
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Commencez par cloner ce référentiel et tous ses sous-modules à l'aide de la commande suivante :
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnEnsuite, utilisez CMake pour créer le projet : (sous Windows, cela doit être dans une invite de commande du développeur)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Si la compilation échoue de manière inexplicable ou prend plus d’une heure, vous risquez de manquer de mémoire. Essayez d'exécuter la commande ci-dessus sans -j dans ce cas.
tiny-cuda-nn est livré avec une extension PyTorch qui permet d'utiliser les MLP rapides et les encodages d'entrée dans un contexte Python. Ces liaisons peuvent être nettement plus rapides que les implémentations Python complètes ; en particulier pour le codage de hachage multirésolution.
Les frais généraux de Python/PyTorch peuvent néanmoins être importants si la taille du lot est petite. Par exemple, avec une taille de lot de 64 Ko, l'exemple
mlp_learning_an_imagefourni est environ 2 fois plus lent via PyTorch que CUDA natif. Avec une taille de lot de 256 Ko et plus (par défaut), les performances sont beaucoup plus proches.
Commencez par configurer un environnement Python 3.X avec une version récente de PyTorch compatible CUDA. Ensuite, invoquez
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchAlternativement, si vous souhaitez installer à partir d'un clone local de tiny-cuda-nn , invoquez
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installEn cas de succès, vous pouvez utiliser des modèles tiny-cuda-nn comme dans l'exemple suivant :
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Voir samples/mlp_learning_an_image_pytorch.py pour un exemple.
Voici un résumé des composants de ce cadre. La documentation JSON répertorie les options de configuration.
| Réseaux | ||
|---|---|---|
| MLP entièrement fusionné | src/fully_fused_mlp.cu | Implémentation ultra-rapide de petits perceptrons multicouches (MLP). |
| COUTELASS MLP | src/cutlass_mlp.cu | MLP basé sur les routines GEMM de CUTLASS. Plus lent que entièrement fusionné, mais gère des réseaux plus grands et reste raisonnablement rapide. |
| Codages d'entrée | ||
|---|---|---|
| Composite | include/tiny-cuda-nn/encodings/composite.h | Permet de composer plusieurs encodages. Peut être, par exemple, utilisé pour assembler le codage Neural Radiance Caching [Müller et al. 2021]. |
| Fréquence | include/tiny-cuda-nn/encodings/frequency.h | NeRF [Mildenhall et al. 2020] codage de position appliqué de manière égale à toutes les dimensions. |
| Grille | include/tiny-cuda-nn/encodings/grid.h | Encodage basé sur des grilles multirésolution entraînables. Utilisé pour les primitives graphiques neuronales instantanées [Müller et al. 2022]. Les grilles peuvent être soutenues par des tables de hachage, un stockage dense ou un stockage en mosaïque. |
| Identité | include/tiny-cuda-nn/encodings/identity.h | Laisse les valeurs intactes. |
| Unblob | include/tiny-cuda-nn/encodings/oneblob.h | À partir de l’échantillonnage d’importance neuronale [Müller et al. 2019] et les variations du contrôle neuronal [Müller et al. 2020]. |
| Harmoniques Sphériques | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Un codage dans l'espace fréquentiel qui convient mieux aux vecteurs de direction qu'à ceux par composants. |
| TriangleVague | include/tiny-cuda-nn/encodings/triangle_wave.h | Alternative peu coûteuse à l'encodage NeRF. Utilisé dans la mise en cache de rayonnement neuronal [Müller et al. 2021]. |
| Pertes | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | Perte standard de L1. |
| L1 relative | include/tiny-cuda-nn/losses/l1.h | Perte L1 relative normalisée par la prédiction du réseau. |
| MAPE | include/tiny-cuda-nn/losses/mape.h | Erreur moyenne absolue en pourcentage (MAPE). Identique à Relative L1, mais normalisé par la cible. |
| SMAPE | include/tiny-cuda-nn/losses/smape.h | Erreur de pourcentage absolu moyen symétrique (SMAPE). Identique à Relative L1, mais normalisé par la moyenne de la prédiction et de la cible. |
| L2 | include/tiny-cuda-nn/losses/l2.h | Perte standard de L2. |
| L2 relative | include/tiny-cuda-nn/losses/relative_l2.h | Perte relative de L2 normalisée par la prédiction du réseau [Lehtinen et al. 2018]. |
| Luminance relative L2 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | Comme ci-dessus, mais normalisé par la luminance de la prédiction du réseau. Applicable uniquement lorsque la prédiction du réseau est RVB. Utilisé dans la mise en cache de rayonnement neuronal [Müller et al. 2021]. |
| Entropie croisée | include/tiny-cuda-nn/losses/cross_entropy.h | Perte d'entropie croisée standard. Applicable uniquement lorsque la prédiction réseau est un PDF. |
| Variance | include/tiny-cuda-nn/losses/variance_is.h | Perte de variance standard. Applicable uniquement lorsque la prédiction réseau est un PDF. |
| Optimiseurs | ||
|---|---|---|
| Adam | include/tiny-cuda-nn/optimizers/adam.h | Implémentation d'Adam [Kingma et Ba 2014], généralisée à AdaBound [Luo et al. 2019]. |
| Novograd | include/tiny-cuda-nn/optimizers/lookahead.h | Mise en œuvre de Novograd [Ginsburg et al. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | Descente de gradient stochastique standard (SGD). |
| Shampooing | include/tiny-cuda-nn/optimizers/shampoo.h | Implémentation de l'optimiseur de shampooing de 2ème ordre [Gupta et al. 2018] avec des optimisations maison ainsi que celles d'Anil et al. [2020]. |
| Moyenne | include/tiny-cuda-nn/optimizers/average.h | Encapsule un autre optimiseur et calcule une moyenne linéaire des poids sur les N dernières itérations. La moyenne est utilisée uniquement à des fins d’inférence (ne sert pas à la formation). |
| Par lots | include/tiny-cuda-nn/optimizers/batched.h | Encapsule un autre optimiseur, en appelant l'optimiseur imbriqué une fois tous les N pas sur le dégradé moyen. A le même effet que d’augmenter la taille du lot mais ne nécessite qu’une quantité constante de mémoire. |
| Composite | include/tiny-cuda-nn/optimizers/composite.h | Permet d'utiliser plusieurs optimiseurs sur différents paramètres. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | Encapsule un autre optimiseur et calcule une moyenne mobile exponentielle des poids. La moyenne est utilisée uniquement à des fins d’inférence (ne sert pas à la formation). |
| Décroissance exponentielle | include/tiny-cuda-nn/optimizers/exponential_decay.h | Encapsule un autre optimiseur et effectue une décroissance exponentielle du taux d'apprentissage constante par morceaux. |
| Anticipation | include/tiny-cuda-nn/optimizers/lookahead.h | Encapsule un autre optimiseur, implémentant l'algorithme d'anticipation [Zhang et al. 2019]. |
Ce framework est sous licence BSD à 3 clauses. Veuillez consulter LICENSE.txt pour plus de détails.
Si vous l'utilisez dans vos recherches, nous apprécierions une citation via
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Pour toute demande commerciale, veuillez visiter notre site Web et soumettre le formulaire : NVIDIA Research Licensing
Entre autres, ce cadre alimente les publications suivantes :
Primitives graphiques neuronales instantanées avec un codage de hachage multirésolution
Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
Transactions ACM sur graphiques ( SIGGRAPH ), juillet 2022
Site Web / Papier / Code / Vidéo / BibTeX
Extraction de modèles 3D triangulaires, de matériaux et d'éclairage à partir d'images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR (Oral) , juin 2022
Site Web / Article / Vidéo / BibTeX
Mise en cache du rayonnement neuronal en temps réel pour le traçage de chemin
Thomas Müller, Fabrice Rousselle, Jan Novák, Alexander Keller
Transactions ACM sur graphiques ( SIGGRAPH ), août 2021
Papier / Discussion GTC / Vidéo / Visualiseur de résultats interactif / BibTeX
Ainsi que les logiciels suivants :
NerfAcc : une boîte à outils générale d'accélération NeRF
Ruilong Li, Matthew Tancik, Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio : un cadre pour le développement de champs de rayonnement neuronal
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
N'hésitez pas à faire une pull request si votre publication ou votre logiciel n'est pas répertorié.
Des remerciements particuliers vont aux auteurs du NRC pour leurs discussions utiles et à Nikolaus Binder pour avoir fourni une partie de l'infrastructure de ce framework, ainsi que pour son aide dans l'utilisation de TensorCores depuis CUDA.


