

Nouveau robot en ville : SO-100

Nous venons d'ajouter un nouveau tutoriel sur la façon de construire un robot plus abordable, au prix de 110 $ par bras !
Apprenez-lui de nouvelles compétences en lui montrant quelques mouvements avec juste un ordinateur portable.
Alors regardez votre robot fait maison agir de manière autonome ?
Suivez le lien vers le didacticiel complet du SO-100.
LeRobot : une IA de pointe pour la robotique du monde réel
? LeRobot vise à fournir des modèles, des ensembles de données et des outils pour la robotique du monde réel dans PyTorch. L’objectif est de réduire les barrières à l’entrée dans la robotique afin que chacun puisse contribuer et bénéficier du partage d’ensembles de données et de modèles pré-entraînés.
? LeRobot contient des approches de pointe dont il a été démontré qu'elles sont transférables au monde réel en mettant l'accent sur l'apprentissage par imitation et l'apprentissage par renforcement.
? LeRobot fournit déjà un ensemble de modèles pré-entraînés, des ensembles de données avec des démonstrations collectées par des humains et des environnements de simulation pour démarrer sans assembler de robot. Dans les semaines à venir, le plan est d'ajouter de plus en plus de support pour la robotique du monde réel sur les robots les plus abordables et les plus performants du marché.
? LeRobot héberge des modèles et des ensembles de données pré-entraînés sur cette page de la communauté Hugging Face : huggingface.co/lerobot
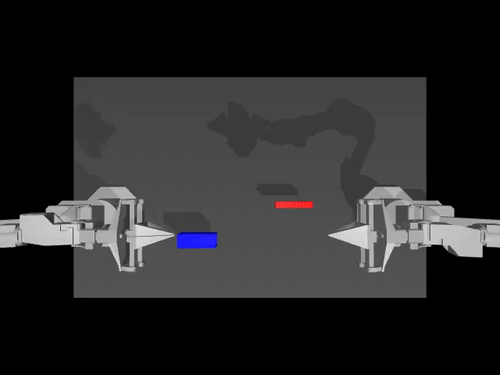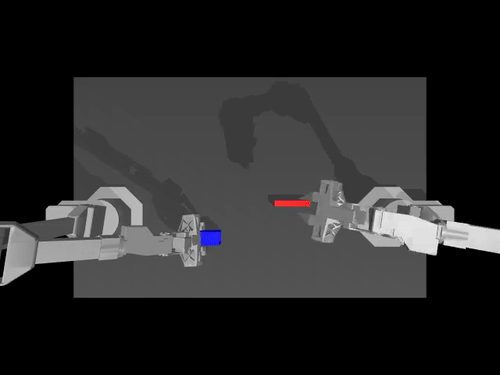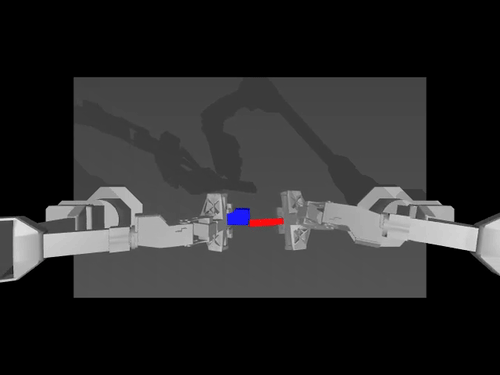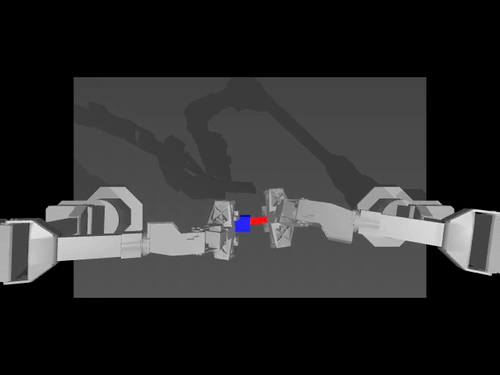 |  | 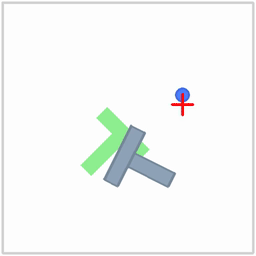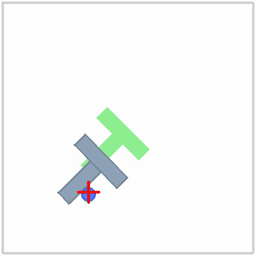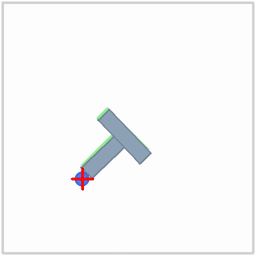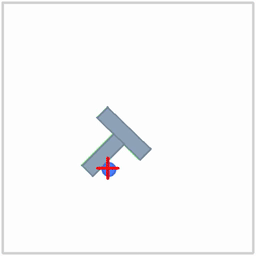 |
| Politique ACT sur l'environnement ALOHA | Politique TDMPC sur l'environnement SimXArm | Politique de diffusion sur l'environnement PushT |
Téléchargez notre code source :
git clone https://github.com/huggingface/lerobot.git
cd lerobot Créez un environnement virtuel avec Python 3.10 et activez-le, par exemple avec miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotInstaller ? LeRobot :
pip install -e .REMARQUE : en fonction de votre plate-forme, si vous rencontrez des erreurs de construction au cours de cette étape, vous devrez peut-être installer
cmakeetbuild-essentialpour créer certaines de nos dépendances. Sous Linux :sudo apt-get install cmake build-essential
Pour les simulations, ? LeRobot est livré avec des environnements de gymnase qui peuvent être installés en extra :
Par exemple, pour installer ? LeRobot avec aloha et pusht, utilisez :
pip install -e " .[aloha, pusht] "Pour utiliser les pondérations et les biais pour le suivi des expériences, connectez-vous avec
wandb login(Remarque : vous devrez également activer WandB dans la configuration. Voir ci-dessous.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Consultez l'exemple 1 qui illustre comment utiliser notre classe d'ensemble de données qui télécharge automatiquement les données depuis le hub Hugging Face.
Vous pouvez également visualiser localement les épisodes d'un ensemble de données sur le hub en exécutant notre script depuis la ligne de commande :
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 ou à partir d'un ensemble de données dans un dossier local avec la variable d'environnement racine DATA_DIR (dans le cas suivant, l'ensemble de données sera recherché dans ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Il ouvrira rerun.io et affichera les flux de caméras, les états et les actions du robot, comme ceci :
Notre script peut également visualiser des ensembles de données stockés sur un serveur distant. Voir python lerobot/scripts/visualize_dataset.py --help pour plus d'instructions.
LeRobotDataset Un jeu de données au format LeRobotDataset est très simple à utiliser. Il peut être chargé à partir d'un référentiel sur le hub Hugging Face ou d'un dossier local simplement avec par exemple dataset = LeRobotDataset("lerobot/aloha_static_coffee") et peut être indexé comme n'importe quel ensemble de données Hugging Face et PyTorch. Par exemple, dataset[0] récupérera une seule image temporelle de l'ensemble de données contenant des observations et une action en tant que tenseurs PyTorch prêts à être introduits dans un modèle.
Une spécificité de LeRobotDataset est que, plutôt que de récupérer une seule image par son index, on peut récupérer plusieurs images en fonction de leur relation temporelle avec la trame indexée, en définissant delta_timestamps sur une liste d'heures relatives par rapport à la trame indexée. Par exemple, avec delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} on peut récupérer, pour un index donné, 4 images : 3 images "précédentes" 1 seconde, 0,5 seconde, et 0,2 seconde avant la trame indexée, et la trame indexée elle-même (correspondant à l'entrée 0). Voir l'exemple 1_load_lerobot_dataset.py pour plus de détails sur delta_timestamps .
Sous le capot, le format LeRobotDataset utilise plusieurs méthodes pour sérialiser les données, ce qui peut être utile à comprendre si vous envisagez de travailler plus étroitement avec ce format. Nous avons essayé de créer un format d'ensemble de données flexible mais simple qui couvrirait la plupart des types de fonctionnalités et de spécificités présentes dans l'apprentissage par renforcement et la robotique, en simulation et dans le monde réel, en mettant l'accent sur les caméras et les états des robots, mais facilement étendu à d'autres types d'informations sensorielles. entrées tant qu’elles peuvent être représentées par un tenseur.
Voici les détails importants et l'organisation de la structure interne d'un LeRobotDataset typique instancié avec dataset = LeRobotDataset("lerobot/aloha_static_coffee") . Les caractéristiques exactes changeront d’un ensemble de données à l’autre, mais pas les aspects principaux :
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
Un LeRobotDataset est sérialisé à l'aide de plusieurs formats de fichiers répandus pour chacune de ses parties, à savoir :
safetensorsafetensor L'ensemble de données peut être téléchargé/téléchargé de manière transparente à partir du hub HuggingFace. Pour travailler sur un ensemble de données local, vous pouvez définir la variable d'environnement DATA_DIR sur votre dossier racine de l'ensemble de données, comme illustré dans la section ci-dessus sur la visualisation de l'ensemble de données.
Consultez l'exemple 2 qui illustre comment télécharger une stratégie pré-entraînée à partir du hub Hugging Face et exécuter une évaluation sur son environnement correspondant.
Nous fournissons également un script plus performant pour paralléliser l'évaluation sur plusieurs environnements au cours du même déploiement. Voici un exemple avec un modèle pré-entraîné hébergé sur lerobot/diffusion_pusht :
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Remarque : Après avoir formé votre propre stratégie, vous pouvez réévaluer les points de contrôle avec :
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Voir python lerobot/scripts/eval.py --help pour plus d'instructions.
Consultez l'exemple 3 qui illustre comment entraîner un modèle à l'aide de notre bibliothèque principale en python, et l'exemple 4 qui montre comment utiliser notre script d'entraînement à partir de la ligne de commande.
En général, vous pouvez utiliser notre script de formation pour former facilement n'importe quelle politique. Voici un exemple de formation de la politique ACT sur les trajectoires collectées par les humains sur l'environnement de simulation Aloha pour la tâche d'insertion :
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human Le répertoire des expériences est généré automatiquement et apparaîtra en jaune dans votre terminal. Cela ressemble à outputs/train/2024-05-05/20-21-12_aloha_act_default . Vous pouvez spécifier manuellement un répertoire d'expérience en ajoutant cet argument à la commande python train.py :
hydra.run.dir=your/new/experiment/dir Dans le répertoire de l'expérience, il y aura un dossier appelé checkpoints qui aura la structure suivante :
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Pour reprendre l'entraînement à partir d'un point de contrôle, vous pouvez les ajouter à la commande python train.py :
hydra.run.dir=your/original/experiment/dir resume=trueIl chargera les états du modèle pré-entraîné, de l'optimiseur et du planificateur pour la formation. Pour plus d’informations veuillez consulter notre tutoriel sur la reprise de l’entraînement ici.
Pour utiliser wandb pour enregistrer les courbes de formation et d'évaluation, assurez-vous d'avoir exécuté wandb login en tant qu'étape de configuration unique. Ensuite, lors de l'exécution de la commande d'entraînement ci-dessus, activez WandB dans la configuration en ajoutant :
wandb.enable=trueUn lien vers les journaux wandb pour l'exécution apparaîtra également en jaune dans votre terminal. Voici un exemple de ce à quoi ils ressemblent dans votre navigateur. Veuillez également consulter ici l'explication de certaines métriques couramment utilisées dans les journaux.

Remarque : Pour des raisons d'efficacité, pendant l'entraînement, chaque point de contrôle est évalué sur un faible nombre d'épisodes. Vous pouvez utiliser eval.n_episodes=500 pour évaluer plus d'épisodes que la valeur par défaut. Ou, après la formation, vous souhaiterez peut-être réévaluer vos meilleurs points de contrôle sur davantage d'épisodes ou modifier les paramètres d'évaluation. Voir python lerobot/scripts/eval.py --help pour plus d'instructions.
Nous avons organisé nos fichiers de configuration (sous lerobot/configs ) de telle sorte qu'ils reproduisent les résultats SOTA d'une variante de modèle donnée dans leurs œuvres originales respectives. Exécuter simplement :
python lerobot/scripts/train.py policy=diffusion env=pushtreproduit les résultats SOTA pour la politique de diffusion sur la tâche PushT.
Les politiques pré-entraînées, ainsi que les détails de reproduction, peuvent être trouvées dans la section « Modèles » de https://huggingface.co/lerobot.
Si vous souhaitez contribuer à ? LeRobot, veuillez consulter notre guide de contribution.
Pour ajouter un ensemble de données au hub, vous devez vous connecter à l'aide d'un jeton d'accès en écriture, qui peut être généré à partir des paramètres Hugging Face :
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Pointez ensuite sur votre dossier d'ensemble de données brutes (par exemple data/aloha_static_pingpong_test_raw ) et transférez votre ensemble de données vers le hub avec :
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Voir python lerobot/scripts/push_dataset_to_hub.py --help pour plus d'instructions.
Si le format de votre ensemble de données n'est pas pris en charge, implémentez le vôtre dans lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py en copiant des exemples comme pusht_zarr, umi_zarr, aloha_hdf5 ou xarm_pkl.
Une fois que vous avez formé une politique, vous pouvez la télécharger sur le hub Hugging Face en utilisant un identifiant de hub qui ressemble à ${hf_user}/${repo_name} (par exemple lerobot/diffusion_pusht).
Vous devez d'abord trouver le dossier checkpoint situé dans votre répertoire d'expérience (par exemple outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Dans celui-ci se trouve un répertoire pretrained_model qui doit contenir :
config.json : une version sérialisée de la configuration de la stratégie (suivant la configuration de la classe de données de la stratégie).model.safetensors : Un ensemble de paramètres torch.nn.Module , enregistrés au format Hugging Face Safetensors.config.yaml : une configuration de formation Hydra consolidée contenant les configurations de politique, d'environnement et d'ensemble de données. La configuration de la stratégie doit correspondre exactement config.json . La configuration de l'environnement est utile à toute personne souhaitant évaluer votre politique. La configuration de l'ensemble de données sert simplement de trace écrite pour la reproductibilité.Pour les télécharger sur le hub, exécutez ce qui suit :
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelVoir eval.py pour un exemple de la façon dont d'autres personnes peuvent utiliser votre politique.
Un exemple d'extrait de code pour profiler l'évaluation d'une politique :
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Si vous le souhaitez, vous pouvez citer ce travail avec :
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}De plus, si vous utilisez une architecture politique, des modèles pré-entraînés ou des ensembles de données particuliers, il est recommandé de citer les auteurs originaux de l'ouvrage tels qu'ils apparaissent ci-dessous :
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

