EasyOCR
v1.7.2
OCR prêt à l'emploi avec plus de 80 langues prises en charge et tous les scripts d'écriture populaires, notamment : latin, chinois, arabe, devanagari, cyrillique, etc.
Essayez la démo sur notre site Web
Intégré aux espaces Huggingface ? en utilisant Gradio. Essayez la démo Web :
24 septembre 2024 - Version 1.7.2
Lire toutes les notes de version



Installer en utilisant pip
Pour la dernière version stable :
pip install easyocrPour la dernière version de développement :
pip install git+https://github.com/JaidedAI/EasyOCR.git Remarque 1 : Pour Windows, veuillez d'abord installer torch et torchvision en suivant les instructions officielles ici https://pytorch.org. Sur le site Web de pytorch, assurez-vous de sélectionner la bonne version de CUDA dont vous disposez. Si vous avez l'intention d'exécuter uniquement en mode CPU, sélectionnez CUDA = None .
Remarque 2 : Nous fournissons également un Dockerfile ici.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )La sortie sera sous forme de liste, chaque élément représente respectivement un cadre de délimitation, le texte détecté et le niveau de confiance.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Remarque 1 : ['ch_sim','en'] est la liste des langues que vous souhaitez lire. Vous pouvez transmettre plusieurs langues à la fois, mais toutes les langues ne peuvent pas être utilisées ensemble. L'anglais est compatible avec toutes les langues et les langues partageant des caractères communs sont généralement compatibles entre elles.
Remarque 2 : Au lieu du chemin de fichier chinese.jpg , vous pouvez également transmettre un objet image OpenCV (tableau numpy) ou un fichier image sous forme d'octets. Une URL vers une image brute est également acceptable.
Note 3 : La ligne reader = easyocr.Reader(['ch_sim','en']) sert à charger un modèle en mémoire. Cela prend un certain temps, mais il ne faut l'exécuter qu'une seule fois.
Vous pouvez également définir detail=0 pour une sortie plus simple.
reader . readtext ( 'chinese.jpg' , detail = 0 )Résultat:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Les poids des modèles pour la langue choisie seront automatiquement téléchargés ou vous pouvez les télécharger manuellement depuis le hub de modèles et les placer dans le dossier « ~/.EasyOCR/model ».
Si vous n'avez pas de GPU ou si votre GPU a peu de mémoire, vous pouvez exécuter le modèle en mode CPU uniquement en ajoutant gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Pour plus d'informations, lisez le didacticiel et la documentation de l'API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TruePour le modèle de reconnaissance, lisez ici.
Pour le modèle de détection (CRAFT), lisez ici.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )L'idée est de pouvoir brancher n'importe quel modèle de pointe dans EasyOCR. De nombreux génies tentent de créer de meilleurs modèles de détection/reconnaissance, mais nous n’essayons pas d’être des génies ici. Nous souhaitons simplement rendre leurs œuvres accessibles rapidement au public… gratuitement. (enfin, nous pensons que la plupart des génies veulent que leur travail crée un impact positif aussi rapide/important que possible) Le pipeline devrait ressembler au diagramme ci-dessous. Les emplacements gris sont des espaces réservés pour les modules bleu clair modifiables.
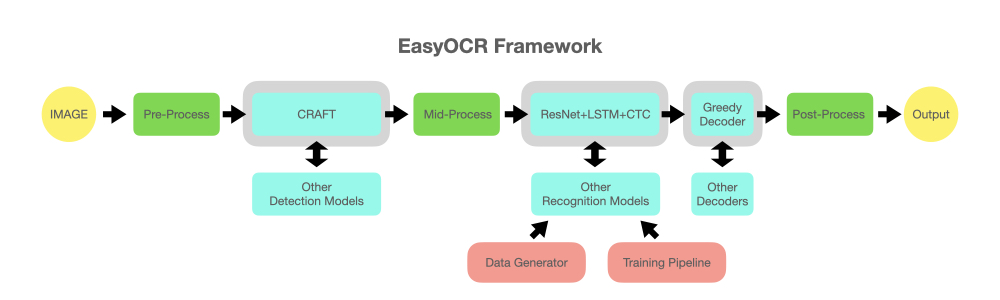
Ce projet est basé sur la recherche et le code de plusieurs articles et référentiels open source.
Toute l'exécution du deep learning est basée sur Pytorch. ❤️
L'exécution de la détection utilise l'algorithme CRAFT de ce référentiel officiel et leur article (Merci @YoungminBaek de @clovaai). Nous utilisons également leur modèle pré-entraîné. Le script de formation est fourni par @gmuffiness.
Le modèle de reconnaissance est un CRNN (papier). Il est composé de 3 composants principaux : l'extraction de fonctionnalités (nous utilisons actuellement Resnet) et VGG, l'étiquetage de séquences (LSTM) et le décodage (CTC). Le pipeline de formation pour l’exécution de la reconnaissance est une version modifiée du framework deep-text-recognition-benchmark. (Merci @ku21fan de @clovaai) Ce référentiel est un joyau qui mérite plus de reconnaissance.
Le code de recherche Beam est basé sur ce référentiel et son blog. (Merci @githubharald)
La synthèse des données est basée sur TextRecognitionDataGenerator. (Merci @Belval)
Et une bonne lecture sur CTC sur distill.pub ici.
Ensemble, faisons progresser l’humanité en rendant l’IA accessible à tous !
3 façons de contribuer :
Codeur : veuillez envoyer un PR pour les petits bugs/améliorations. Pour les plus gros, discutez avec nous en ouvrant d’abord un numéro. Il existe une liste de problèmes de bugs/améliorations possibles marqués avec « PR WELCOME ».
Utilisateur : Dites-nous comment EasyOCR vous profite, à vous ou à votre organisation, pour encourager le développement ultérieur. Publiez également les cas d'échec dans la section Problèmes pour aider à améliorer les futurs modèles.
Leader technique/gourou : Si vous avez trouvé cette bibliothèque utile, faites passer le mot ! (Voir l'article de Yann Lecun sur EasyOCR)
Pour demander une nouvelle langue, nous avons besoin que vous envoyiez un PR avec les 2 fichiers suivants :
Si votre langue comporte des éléments uniques (tels que 1. Arabe : les caractères changent de forme lorsqu'ils sont attachés les uns aux autres + écrivent de droite à gauche 2. Thaï : Certains caractères doivent être au-dessus de la ligne et d'autres en dessous), veuillez nous informer au mieux. de vos capacités et/ou donnez des liens utiles. Il est important de soigner les détails pour parvenir à un système qui fonctionne vraiment.
Enfin, comprenez que notre priorité devra aller aux langues populaires ou aux ensembles de langues partageant entre elles une grande partie de leurs caractères (dites-nous également si c'est le cas pour votre langue). Il nous faut au moins une semaine pour développer un nouveau modèle, vous devrez donc peut-être attendre un peu avant que le nouveau modèle soit publié.
Voir Liste des langages en développement
En raison de ressources limitées, un problème datant de plus de 6 mois sera automatiquement fermé. Veuillez ouvrir à nouveau un problème s'il est critique.
Pour le support entreprise, Jaided AI propose un service complet pour les systèmes OCR/IA personnalisés, depuis la mise en œuvre, la formation/la mise au point et le déploiement. Cliquez ici pour nous contacter.


