LVBench
1.0.0
[Page du projet] [Article arXiv] [Ensemble de données][? Classement][? Classement Huggingface]
LVBench est une référence conçue pour évaluer et améliorer les capacités des modèles multimodaux à comprendre et à extraire des informations à partir de longues vidéos d'une durée maximale de deux heures.
2024.08.2 Nous mettons en place le classement LVBench sur Huggingface Spaces ! Vérifiez le classement.
2024.06.11 Nous avons publié LVBench, une nouvelle référence pour la compréhension des vidéos longues !
LVBench est un benchmark conçu pour évaluer les capacités des modèles à comprendre de longues vidéos. Nous avons collecté de nombreuses données vidéo longues provenant de sources publiques, annotées grâce à une combinaison d'efforts manuels et d'assistance de modèle. Notre référence fournit une base solide pour tester des modèles sur des contextes temporels étendus, garantissant une évaluation de haute qualité grâce à une annotation humaine méticuleuse et un contrôle qualité en plusieurs étapes.
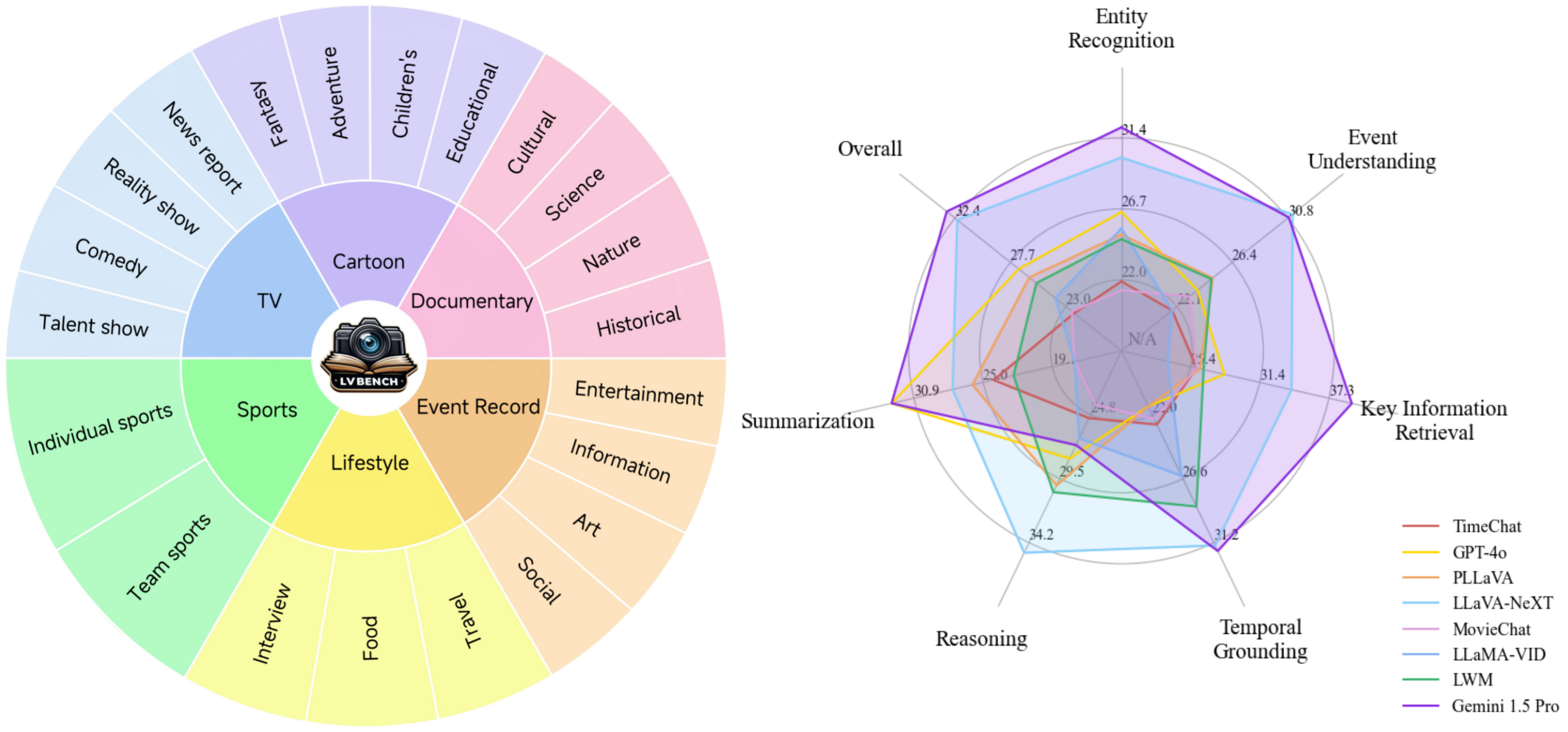
Capacités de base : six fonctionnalités de base pour la compréhension de longues vidéos, permettant la création de questions complexes et stimulantes pour une évaluation complète du modèle.
Données diverses : une gamme diversifiée de données vidéo longues, en moyenne cinq fois plus longues que les ensembles de données existants les plus longs, couvrant diverses catégories.
Annotations de haute qualité : référence fiable avec des annotations humaines méticuleuses et des processus de contrôle qualité en plusieurs étapes.

Notre ensemble de données est sous la licence CC-BY-NC-SA-4.0.
LVBench est uniquement utilisé pour la recherche universitaire. L’utilisation commerciale sous quelque forme que ce soit est interdite. Nous ne possédons aucun droit d'auteur sur les fichiers vidéo bruts.
S'il y a une infraction dans LVBench, veuillez contacter [email protected] ou soulever directement un problème, et nous le supprimerons immédiatement.
Installez d'abord video2dataset :
pip installer video2dataset pip désinstaller le moteur du transformateur
Ensuite, vous devez télécharger video_info.meta.jsonl depuis Huggingface et le placer dans le répertoire data .
Chaque entrée du fichier video_info.meta.jsonl possède un champ clé correspondant à l'ID d'une vidéo YouTube. Les utilisateurs peuvent télécharger la vidéo correspondante en utilisant cet identifiant. Alternativement, les utilisateurs peuvent utiliser le script de téléchargement que nous fournissons, download.sh, pour télécharger :
scripts de CD bash télécharger.sh
Après l'exécution, les fichiers vidéo seront stockés dans le répertoire script/videos .
pip install -e .
(Remarque : si vous souhaitez essayer l'évaluation rapidement, vous pouvez utiliser scripts/construct_random_answers.py pour préparer un fichier de réponses aléatoires.)
scripts de CD python test_acc.py
Après l'exécution, vous obtiendrez un fichier de résultats d'évaluation result.json dans le répertoire scripts . Vous pouvez soumettre les résultats au classement.
Comparaison des modèles :
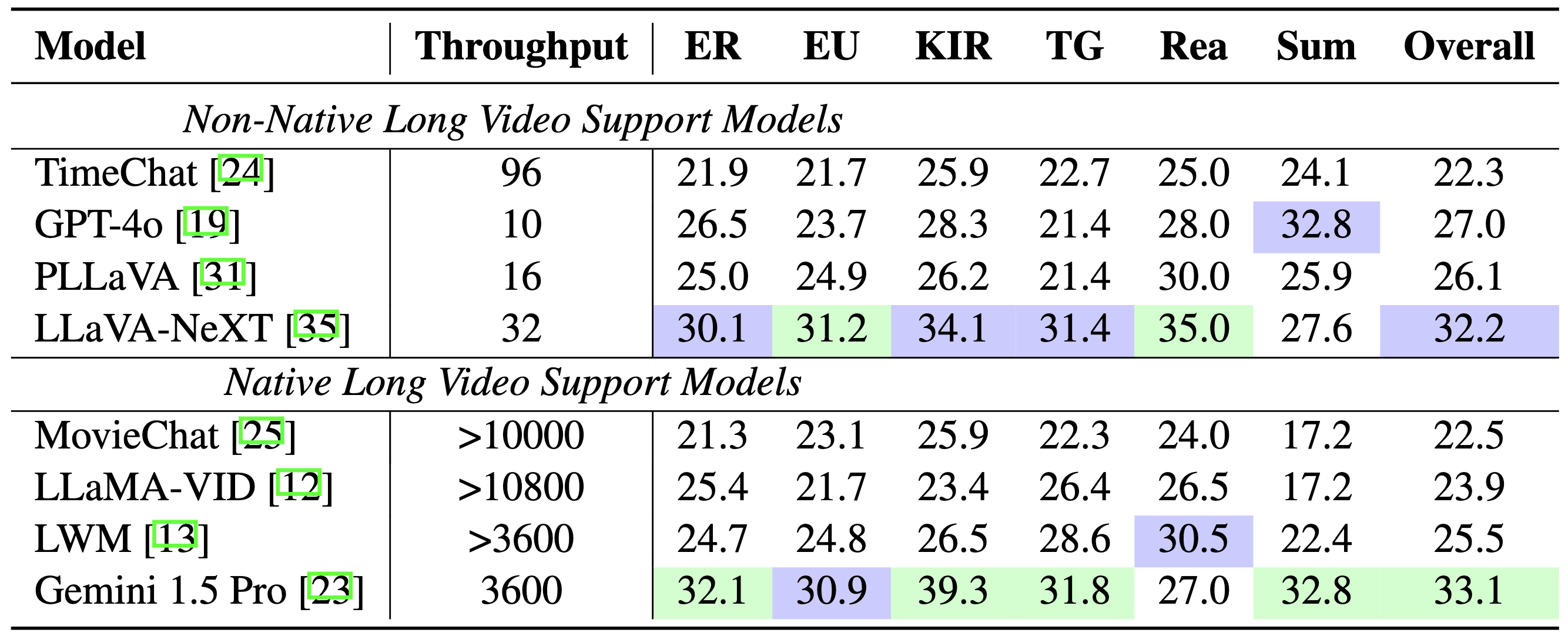
Comparaison de référence :
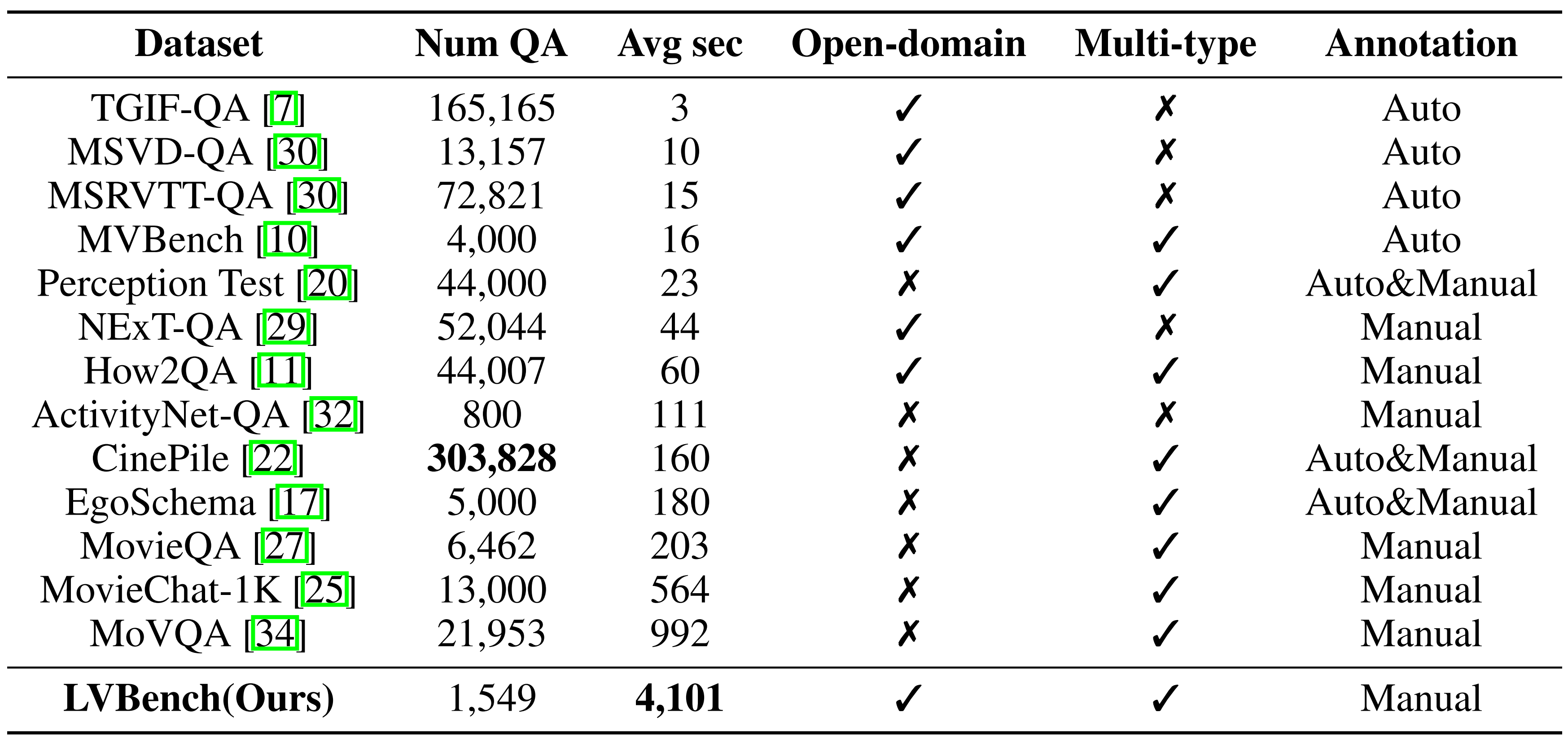
Modèle vs humain :

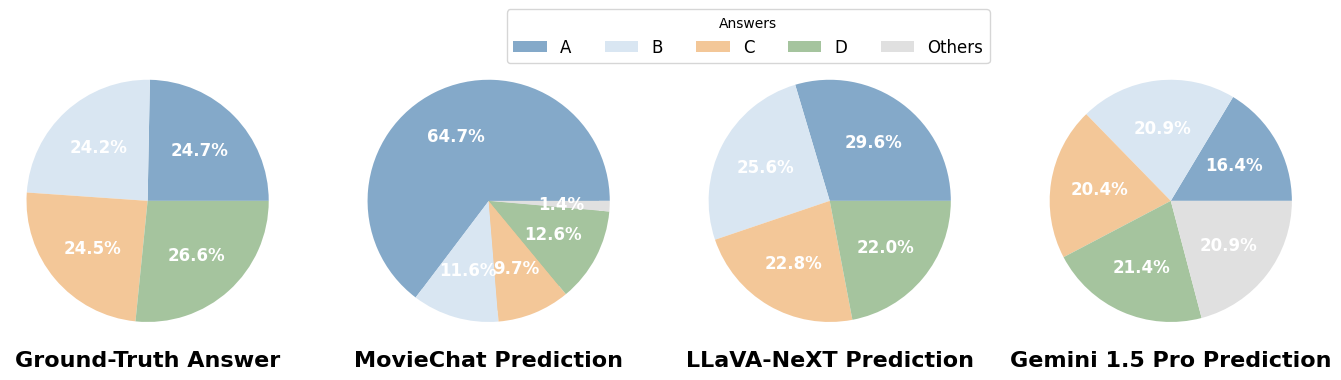
Répartition des réponses :
Si vous trouvez notre travail utile pour votre recherche, pensez à citer notre travail.
@misc{wang2024lvbench, title={LVBench : un benchmark de compréhension des vidéos extrêmement longues},
author={Weihan Wang et Zehai He et Wenyi Hong et Yean Cheng et Xiaohan Zhang et Ji Qi et Shiyu Huang et Bin Xu et Yuxiao Dong et Ming Ding et Jie Tang}, année={2024}, eprint={2406.08035}, archivePrefix ={arXiv}, PrimaryClass={cs.CV}} 

