Un système de recommandation de livres est un outil qui suggère des livres aux utilisateurs en fonction de leurs intérêts et de leur historique de lecture. Ces systèmes peuvent être utilisés par les bibliothèques, les librairies ou les détaillants en ligne pour aider les utilisateurs à découvrir de nouveaux livres qui pourraient leur plaire.
Il existe plusieurs approches pour créer un système de recommandation de livres, notamment le filtrage collaboratif, le filtrage basé sur le contenu et les systèmes hybrides combinant les deux approches.
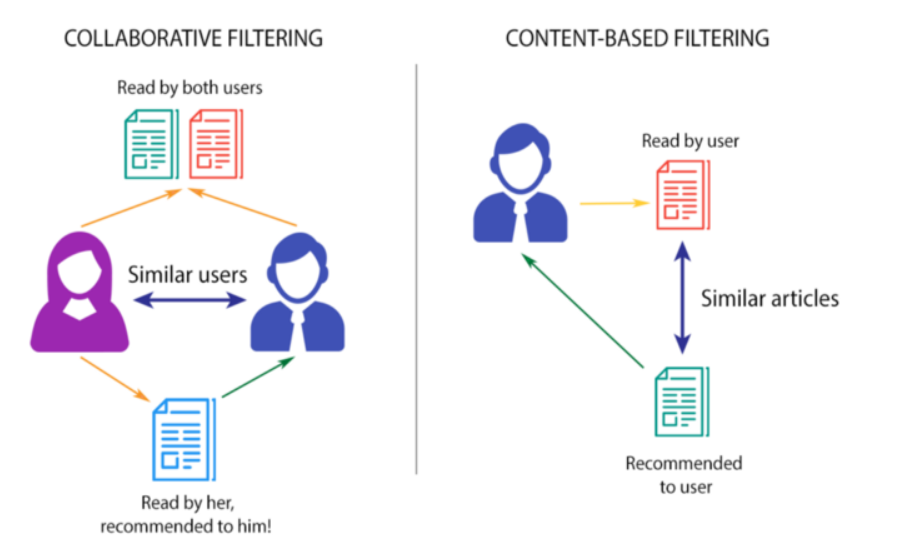
Le filtrage collaboratif repose sur l'idée que les utilisateurs ayant des antécédents de lecture similaires sont susceptibles d'avoir des intérêts similaires, de sorte qu'un livre qu'un utilisateur aime est susceptible d'être apprécié par un autre utilisateur ayant un historique de lecture similaire. Cette approche est souvent utilisée dans les systèmes de recommandation de films, de musique et d’autres produits.
Le filtrage basé sur le contenu , quant à lui, se concentre sur les caractéristiques des livres eux-mêmes, telles que leur genre, leur thème et leur auteur, pour formuler des recommandations. Cette approche est utile lorsqu'il n'y a pas suffisamment de données disponibles sur les préférences des utilisateurs pour utiliser le filtrage collaboratif.
Les systèmes hybrides combinent à la fois le filtrage collaboratif et le filtrage basé sur le contenu pour émettre des recommandations. Ils peuvent prendre en compte à la fois les caractéristiques des livres et les préférences des utilisateurs pour fournir une recommandation plus personnalisée.
La création d'un système de recommandation de livres efficace présente plusieurs défis, notamment la nécessité de disposer de grandes quantités de données pour entraîner le système, la complexité du traitement du langage naturel et la nécessité d'équilibrer la personnalisation des recommandations avec la diversité des livres recommandés.
L'ensemble de données Book-Crossing comprend 3 fichiers.
Utilisateurs : contient les utilisateurs. Notez que les ID utilisateur (User-ID) ont été anonymisés et mappés sur des nombres entiers. Les données démographiques sont fournies (localisation, âge) si disponibles. Sinon, ces champs contiennent des valeurs NULL.
Livres : les livres sont identifiés par leur ISBN respectif. Les ISBN invalides ont déjà été supprimés de l'ensemble de données. De plus, certaines informations basées sur le contenu sont fournies (titre du livre, auteur du livre, année de publication, éditeur), obtenues auprès d'Amazon Web Services. A noter que dans le cas de plusieurs auteurs, seul le premier est fourni. Des URL renvoyant vers des images de couverture sont également fournies, apparaissant dans trois versions différentes (Image-URL-S, Image-URL-M, Image-URL-L), c'est-à-dire petite, moyenne, grande. Ces URL pointent vers le site Web d'Amazon.
Notes : contient les informations de notation du livre. Les notes (Book-Rating) sont soit explicites, exprimées sur une échelle de 1 à 10 (des valeurs plus élevées dénotant une appréciation plus élevée), soit implicites, exprimées par 0.
Lien vers les ensembles de données : - https://drive.google.com/drive/folders/1Gi0wMWCTigA_rJSi9huyT51lKduBSv43?usp=share_link


